

저는 가끔은 책을 읽을 때 지금 보고 있는 부분을 손가락으로 가리키고는 합니다. 손가락을 밀면서 느껴지는 종이의 감촉이 좋아서 그런 것이기도 하고, 내용이 어려워서 집중을 잘하기 위해서 한데, 이러한 습관을 또 가지고 계신 분이 있으실까요?
이처럼 글을 읽는다는 것은 한 단어 한 단어, 한 문장 한 문장을 순차적으로 보고 이해하는 행위입니다. 문장에는 주어, 동사, 목적어 등의 어순이 있고, 글에는 서론, 본문, 결론 등의 구조가 있기 때문이죠.
지난 글에는 한 문장을 그림처럼 보는 Convolutional Neural Network (CNN)에 대해 공부를 해보았습니다. 이 모델을 가지고 여러 단어로 된 문장, 더 나아가 문장들이 합쳐진 문단을 input으로 넣으면 어떻게 될까요? 아무래도 가로가 상당히 긴 그림이 될 것 같죠? 어떤 문장은 30 개의 단어로 이루어져 있는데, 어떤 문장은 단 2개의 단어만 가지고 있다면 어쩌죠? 이처럼 CNN은 input의 길이가 너무 길거나 여러 input 간 길이간 차이가 다양하다면 효율적으로 처리하기 어렵다는 단점을 가지고 있습니다.
그렇다면 우리 사람이 읽는 것처럼 문장의 단어들을 순차적으로 처리한다면 어떨까요? 이런 방식에 아주 적합한 다른 neural network 모델이 있습니다. 바로 recurrent neural network (RNN)입니다.

Time Series Modelling의 강자 RNN
사실 RNN은 NLP 이외의 time series modelling에 굉장히 많이 쓰이는 모델입니다. Time series 시간이 지나면서 변화하는 변수 (variable)를 말합니다. 매 초마다의 주식 거래량, 매 시간의 기온, 매일의 도시의 교통량, 매달의 강수량 등 각 시간마다 바뀌는 값이 있는 데이터를 time series 합니다. 아래 예시는 매 시간의 우버 택시 콜 숫자입니다.
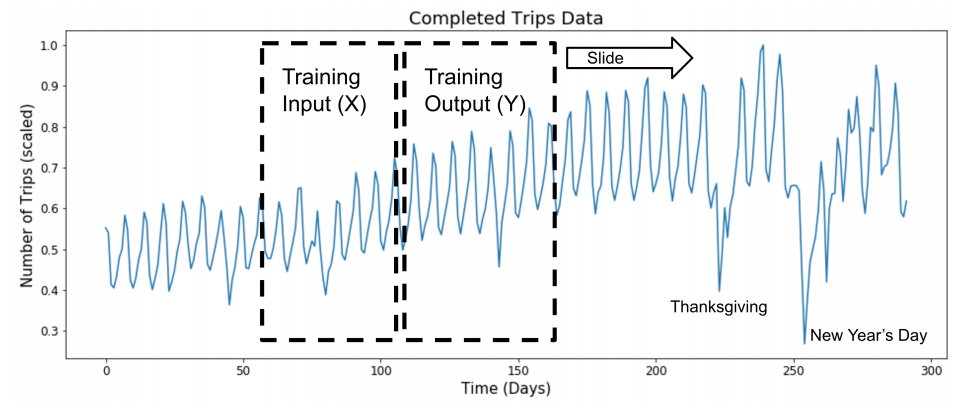
하나의 비디오의 매 초마다 지나가는 이미지, 녹음된 음성의 매 초마다 발생하는 음파, 그리고 문장에 들어있는 각 단어 모두 RNN에 적합한 데이터입니다.
RNN은 기억을 저장하는 네트워크입니다. 많은 머신러닝 모델들은 첫 번째 input이 들어가고, 그다음 두 번째 input이 들어갔을 시 두 input 간의 상관관계를 전혀 고려하지 않습니다. 하지만 만약 time series data라면 이러한 정보가 꽤나 중요할 것입니다. 예를 들어, 오늘 기온을 예측한다면 어제 기온이 27도였다는 사실이 아주 중요할 것입니다. 이러한 정보가 있다면 갑자기 오늘 기온이 -10도가 될 것이라는 예측은 틀릴 확률이 높겠지요.

RNN은 input 여러 개 (위 사진에서 x)가 순차적으로 들어가고, o(output)이 하나씩 생성됩니다. 저 output이 각 시간(timestep)의 예측 값을 의미합니다. 여기서 주목해야 할 것은 기억을 저장하는 h (internal hidden state)입니다. 각 timestep마다 hidden state가 연속적으로 이어지는 것을 알 수 있습니다.
이 hidden state는 여태까지 들어온 input들 간의 상관관계를 저장하는 메모리의 역할을 합니다. 이 h 역시 각 timestep마다 조금씩 변화합니다. 왜냐하면 새로 들어온 input에 따라 메모리 역시 변화해야 하기 때문이죠. 마치 사람이 새로운 지식을 습득할 때마다 사고하는 방식이 달라지는 것처럼요.
문장을 time series로 본다면?
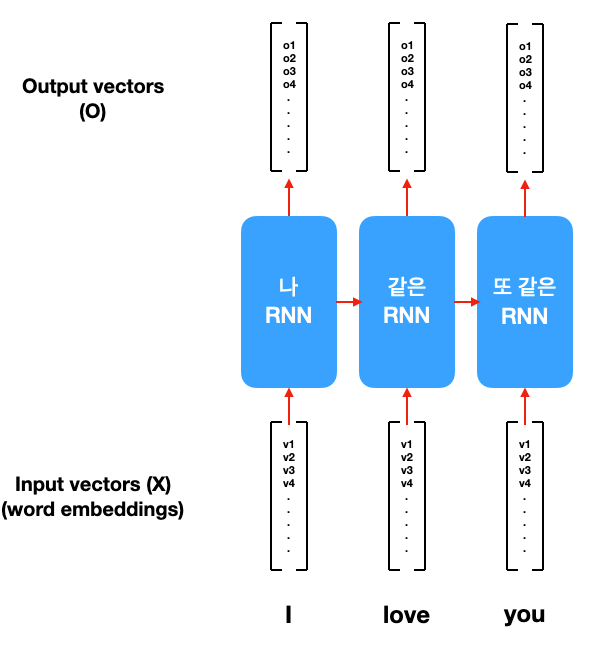
문장은 여러 개의 단어로 이루어져 있습니다. 그렇기에 우리는 단어 한 개를 하나의 input으로 볼 수 있습니다. 위 예시는 "I Love you"이라는 문장을 ["I", "love", "you"]으로 3개의 input vector로 나눈 것을 보여줍니다.
제목처럼 각 단어가 컨베이어 벨트를 타고 RNN으로 한개씩 input된다는 것을 알 수 있습니다. 해결하고자 하는 문제에 따라 하나가 들어갈 때마다 output이 나올 수도 있고, 마지막에 하나의 결과물이 나올 수도 있습니다.
지난번에 배워 듯이 각 단어를 Nx1 사이즈 vector로 표현할 수 있습니다. word2vec이나 glove 같은 pretrained embedding을 사용하는 것이 일반적입니다. 각 timestep의 단어 x는 Nx1 column vector로 표현되어 RNN에 들어가게 됩니다.
RNN의 종류 (심화 과정)
RNN이 처음 고안된 것은 Elman, Finding structure in time, 1990입니다. 이때의 모델을 Simple RNN이라고 부릅니다. 많은 첫 버전이 그렇듯이 Simple RNN은 여러 가지 문제점을 가지고 있었습니다. 예를 들어, 기억해야 할 것들을 메모리에 잘 저장하지 못해 성능이 좋지 못한 것이 가장 큰 이유였습니다. 이를 catastrophic forgetting or vanishing gradient 문제라고 하는데, 이후 많은 후속 연구들이 이를 개선하기 위해 발표되었습니다. 이 글에서는 가장 대표적인 두 가지 연구를 소개하려고 합니다.
Long Short Term Memory (LSTM)
LSTM이라고 불리는 이 모델은 Hochreiter & Schmidhuber (1997)에 처음 제안되었습니다. RNN과 LSTM의 가장 큰 차이점은 모델 안에 여러 개의 gate를 추가하여 input, output 그리고 memory 간 흐르는 정보를 좀 더 섬세하게 제어했다는 점입니다. LSTM에는 input gate, output gate, forget gate, update gate가 있는데, 어떤 정보를 받아들이고, 내보내고, 잊어버리고, 저장할지를 학습하는 수학 모델이라고 이해하시면 될 듯합니다.

현재 RNN 모델을 사용한다고 하면 거의 대부분 LSTM을 뜻합니다. LSTM의 gate mechanism은 Simple RNN보다 더 많은 계산을 필요하지만 훨씬 더 효과적이라 이제는 default로 사용하는 RNN 모델이 되었습니다.
Gated Recurrent Unit (GRU)
GRU는 neural machine translation (기계 번역)의 창시자 중 한 명인 뉴욕대의 조경현 (Kyunghyun Cho) 교수님의 포닥 연구입니다. 구글 번역이 어느 순간 성능이 엄청나게 좋아진 이유가 바로 이 조 교수님의 연구 덕분입니다. 지금도 뉴욕대와 페이스북에서 왕성한 연구 활동을 하시는 굉장한 연구자인데, 앞으로 조경현 교수님의 연구와 튜토리얼 자료를 많이 참고할 예정입니다.
GRU 역시 Simple RNN보다 long-term dependency (좀 더 과거의 정보와의 연계성)을 더 잘 배우는 모델을 만들기 위해 고민한 결과라고 하는데, 재밌는 것은 2014년 당시에 조 교수님은 LSTM에 대해 잘 알지 못했다고 강의 노트 말미에 고백(?) 하셨습니다. 어찌 되었든 GRU는 LSTM과 비슷하지만 조금 더 적은 gate를 통해 비슷한 목적을 달성합니다. 그렇기에 속도 면에서 유리해 성능이 비슷하다면 LSTM 대용으로 쓰이고는 합니다.
오늘은 문장을 순차적으로 보는 RNN을 소개하였습니다. NLP의 다양한 문제들에 쓰이는 모델이기 때문에 앞으로 RNN을 기반으로 한 모델이 등장할 예정입니다. 더 깊게 파고 싶으신 분들은 아래 Reference의 두 가지 강의 노트를 강추드립니다!

Reference
- Kyunghyun Cho, Chapter 4: Recurrent Neural Networks and Gated Recurrent Units, Natural Language Understanding with Distributed Representation
- Daniel Jurafsky & James H. Martin, Chapter 9: Sequence Processing with Recurrent Networks, Speech and Language Processing,
- LSTM 이해하기, 개발자 동건님의 한국어 블로그 포스트.