

저는 세기의 대결 2016년 <알파고 vs. 이세돌>을 인공지능 연구 석사를 시작하던 첫 학기 때 보았습니다. 저에게는 이제 이 새로운 길로 들어가려고 막 시작했던 때라 정말 가슴을 뛰게 하는 뉴스들이었습니다. 바둑 전문가들은 이 대결의 지켜보면서, "알파고는 인간이라면 하지 않을 수를 둔다. 여태까지 정석이라고 알고 있었던 우리의 이론과 지식들이 무참히 깨져나가고 있다."라는 취지의 분석을 많이 하였습니다.
당시 알파고는 인간 바둑 기사들의 기보들을 보고 학습된 모델이었는데도 그렇게 틀을 깨는 전략을 구사할 수 있다는 게 매우 신기하였습니다. 나중에 인공지능 연구를 해보니, 한 명의 인간은 수많은 데이터를 인공지능보다 빠른 속도로 학습하지 못하고, 그 안에 들어 있는 고차원적인 패턴을 읽기는데 비교적 미숙하기에 당연히 그럴 수밖에 없다는 생각이 들었습니다.
언어와 글을 이해하는 NLP 역시 마찬가지입니다. 데이터 기반으로 학습된 NLP 모델들은 수많은 시간을 들여 쌓아 온 언어학의 근간을 흔들기도 합니다. 점점 언어학적 분석을 거치지 않고 모델이 직접 데이터를 통해 언어학적 패턴들을 자동으로 알아내는 연구 방향이 최근 몇 년 간 딥러닝의 등장으로 가속화되었습니다.
이러한 방향과 철학이 신경망 기계 번역 (neural machine translation; nmt)을 태어나게 하였습니다. 지난주에 공부한 MT의 시조새 격인 phrase-based approach는 거의 멸종해버렸다고 해도 무방합니다. 이번 주는 NMT의 기본에 대해 배워보려 합니다. 거의 대부분의 내용은 제가 여태까지 가장 많이 인용한 NMT의 아버지인 NYU 조경현 교수님의 튜토리얼을 참고하였습니다.

번역과 language modelling의 관계?
번역이란 한 언어 (source language; x)에서 다른 언어 (target language; y)로 변환되는 과정입니다. 이걸 확률이라는 framework로 해석하면, "x가 주어졌을 때 y의 확률"이 됩니다.
바로 조건부 확률(conditional probability)라는 겁니다. 우리가 LM을 공부할 때 아주 지겹도록 많이 나온 콘셉트이죠. 앞 단어 몇 개가 주어졌을 때, 다음에 나올 단어는 무엇인가...

"Looking at it in this way, it is clear that this is nothing but conditional language modelling."
"이렇게 보면 결국 번역은 조건부 언어 모델이다"
LM을 학습할 때에는 어떤 텍스트 데이터(corpus)만 있으면 가능했습니다. 그런 것처럼 이러한 conditional LM을 학습하려면 지난주에 배운 parallel corpus을 그대로 활용하면 되겠지요!
번역을 noisy channel model로 본다면?
Week 15에서 ASR을 공부할 때 간략하게 noisy channel model을 공부했었습니다. 누가 보낸 메시지가 어떠한 소음이 섞여 들어가 변형되기 때문에, 그 소음들을 걷어내고 메시지의 내용을 알아내야 한다고요.
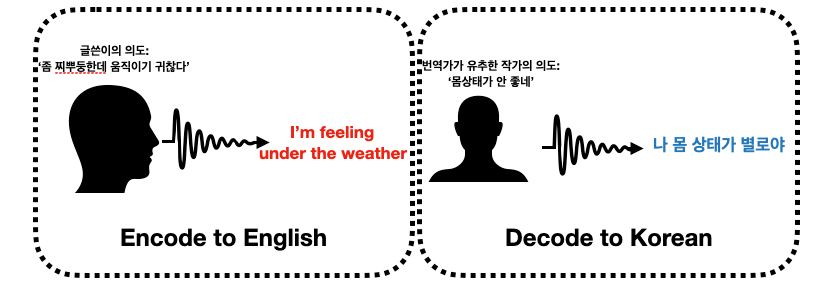
위 그림에서 글쓴이의 의도는 사실 아무도 정말 정확하게 알 수가 없습니다. encode (암호화)된 영어를 읽어 보고 유추만 수 있죠. 그리고 그 유추된 내용에 따라 target language인 한국어로 풀어쓸 수 있습니다. 위 예시 같은 경우에는 글쓴이의 의도를 생각하지 않고 그냥 단어별로 직역만 한다면, "나 지금 날씨 밑에 있어."라는 말도 안 되는 문장으로 번역이 됩니다. 그렇게 한다면 좋은 번역이라고 할 수 없겠죠. 그렇기 때문에 문장을 나누어 1대 1 매칭을 하는 phrase-based MT 모델은 이러한 경우를 잘 번역하지 못하겠지요.
이러한 noisy channel model을 encoder-decoder 모델이라고 부르기도 합니다. 위 예시처럼 암호화되는 부분과 해석하는 부분이 나뉘어 있기 때문이죠.
문장에서 문장으로 seq2seq 모델
이렇게 기계 번역이라는 문제를 두 가지 새로운 방식으로 해석해보았습니다.
1) conditional language modelling
2) encoder-decoder model.
이 두 가지 framework 그리고 지난번에 같이 공부한 엄청난 효과를 내는 RNN을 이용한 neural LM이 모두 합쳐져서 NLP, 아니 머신 러닝 학계 전부에 영향을 준 seq2seq 모델이 탄생합니다. 구조를 함께 살펴볼까요? 아주 직관적입니다.
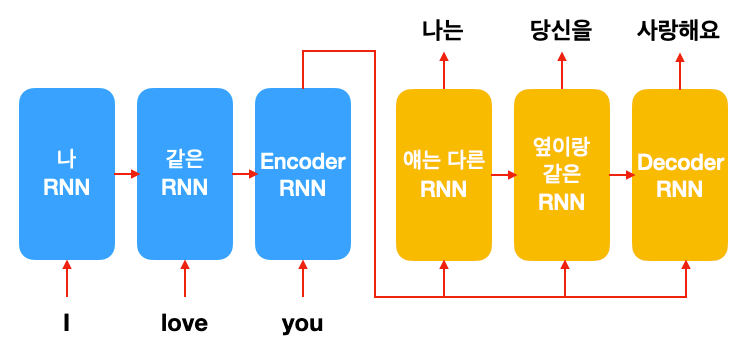
위 그림과 같이 Encoder RNN 한 개, 그리고 Decoder RNN 한 개로 구성됩니다. Source language인 영어 단어는 Encoder RNN으로 들어가고, target language인 한국어 단어는 Decoder RNN으로 출력됩니다. 여기서 중요한 점은 Decoder RNN에서 Encoder RNN의 마지막 hidden state를 계속 참고합니다. 그렇게 seq2seq 모델은 영어 단어들을 다 본 후, 영어 문장을 힐끔힐끔 보면서 한국어 단어 하나하나를 뱉습니다.
오늘은 NMT의 기본이 되는 seq2seq 모델을 설명하기 위해 조금은 더 큰 그림을 그려보았습니다. 다음 시간에는 조금 더 깊이 있기 들어가 seq2seq는 어떻게 학습이 되고, 어떻게 번역 문장을 생성하는지, 그리고 어떻게 평가가 되는지 다루어보겠습니다! 다음 내용도 놓치지 않으려면 아래 이메일 구독 추천합니다!
Reference
- Kyunghyun Cho, Chapter 6: Neural Machine Translation, Natural Language Understanding with Distributed Representation
