도구(Tool)로 업그레이드되는 LLM


generated from playgroundai.com with prompt "robot picking which tool to use from many"
인간이 도구(Tool)를 사용하는 것을 배우고 나서부터 생태계의 강자가 되었듯이, LLM 역시 도구 사용(Tool Use)을 통해 강해질 수 있을까요?
지난 글에서 LLM이 직접 의사 결정을 내리고 어떠한 액션을 취할 수 있는 방식이 있다고 잠깐 언급했었죠. 그게 바로 LLM의 도구 사용에 대한 이야기였습니다.
오늘은 저의 글이 아니라 구글 딥마인드의 연구자 세바스찬 루더(Sebastian Ruder) 님의 NLP 뉴스레터를 번역해보았습니다. 이 주제에 대해 다루고 싶었는데 워낙 잘 정리된 글이 있어서 허락을 받아 <위클리 NLP> 구독자 님들께 보내드립니다.
Google Bard와 함께 번역 및 편집했습니다. (원문)

도구 사용(Tool Use)이란 무엇인가?
언어 모델은 창의적인 콘텐츠 생성, 가상 비서, 고객 지원, 검색 등 다양한 분야에 유용합니다. 그러나 정의에만 따르면 텍스트(natural language)를 생성하는 데만 한정 됨으로 실제 세계와 상호 작용할 수 없습니다^*.
^실제 세계에 접지(grounding) 되지 않았다는 점은 이미 LLM의 한계로 지적되어 왔습니다. Tool use는 이를 해결하죠.
*jiho: Week 36에서 이 부분에 대해 깊게 다루었었죠.
이러한 문제점은 언어 모델이 외부 도구에 접근할 수 있도록 하여 개선할 수 있습니다. 이는 (텍스트 대신) 특수 토큰 또는 명령어를 예측하여 수행될 수 있습니다.
Tool는 다양한 형태를 취할 수 있습니다.
a) 모델 자체 또는 다른 Neural network
b) 검색 엔진과 같이 외부에서 정보를 가져올 수 있는 시스템 (Retrieval component),
c) 기호 계산 또는 코드 모듈,
d) 이전 뉴스레터에서 언급한 물리적 로봇 또는 가상 에이전트를 제어하는 모듈일 수 있습니다.
보다 일반적으로 도구는 어떤 API가 될 수 있습니다.
아래는 언어 모델에 유용할 수 있는 세 가지 도구의 예입니다. 질문 답변(Q&A), 기계 번역(Machine Translation) 및 계산기입니다. 논문 [1]에서 이러한 방식에 대해 자세히 조사해 놓았으니 참고바랍니다.



도구 사용의 장점
도구 사용은 현재 LLM의 한계를 해결하는 실질적인 방법을 제공합니다.
❌ LLM은 수학에 약하다^ (예: 논문 [2]).
✅ 계산기 호출은 모델의 산술 기능을 향상시킬 수 있다.
❌ LLM의 사전 훈련 데이터는 빠르게 과거의 정보가 된다.
✅ 검색 엔진 호출을 통해 LLM은 최신 정보를 생성할 수 있다.
❌ LLM은 환각 증상(Hallucination)이 있다.
✅ LLM이 출처를 인용하도록 하면 신뢰성이 향상될 수 있다.
❌ LLM은 블랙 박스이다.
✅ LLM이 예측을 얻기 위해 사용한 API 호출을 추적한다면 어느 정도의 해석 가능성을 제공한다.
^최신 LLM들은 수학적인 능력이 꽤나 향상되었지만, 아직은 대학원 레벨의 수학은 풀지 못하는 것으로 알려져 있습니다. 하지만 LLM은 수학자 같은 사람들의 직관을 도울 수 있는 비서로 유용하다고 평가되고 있죠.
LLM에게 도구를 사용하는 방법을 가르치기
많은 도구는 API 호출만으로 사용할 수 있지만, LLM에게 어떻게 도구를 사용할 수 있도록 할까요? Few-shot prompting은 LLM을 제어하기 위해 가장 널리 쓰이는 방식입니다만, few-shot prompt는 특히 도구에 복잡한 파라미터가 있거나 여러 도구가 함께 필요한 경우 충분하지 않을 수 있습니다.
LLM에게 도구 사용 예시(demonstration)를 몇 가지 보여주는 대신 도구에 대한 설명서(documentation)를 제공할 수도 있습니다. 사용 예시는 특정 작업에 어떻게 도구를 써야 하는지 보여주는 반면, 설명서는 다양한 도구의 일반적인 기능을 적어 놓았습니다. 논문 [3]은 도구의 설명서를 보여 주는 것이 새로운 도메인에서 예시를 보여주는 few-shot prompting보다 성능이 우수하다는 것을 발견했습니다.

API 호출을 직접 포함된 데이터를 가지고 LLM을 직접 Finetuning하는 것도 좋은 방법인 것 같습니다^. 한 가지 예에 여러 API 호출이 가능하기에, '올바른' API 호출만 하도록 데이터를 만들 수 있습니다 (실제로는 LLM은 few-shot 방식으로 지시된 후 틀린 API 호출이 포함된 예측은 삭제되는 방식이 많이 쓰입니다).
^우리는 이를 Behavioral Finetuning이라고 할 수도 있습니다.
예를 들어, 논문 [4]에서는 Natural Questions 데이터로 샘플 API를 만든 후, 언어 모델이 API 호출을 직접 실행하고 돌려 받은 결과로 응답을 생성하는 데 사용하게 하였습니다. 이 때 언어 모델이 잘못된 API 호출을 생성한 예제는 필터링하고, 모델은 API 호출이 추가된 데이터셋으로 Fine-tuning 되었습니다.
논문 [5]에서는 레이블이 존재하지 않은 (unlabled) 데이터 셋 (Common Crawl의 일부분)에 비슷한 전략을 사용했습니다. 올바른 응답으로 이어지는 API 호출만 데이터 셋에 포함시키는 것이 아니라, 다음 토큰에 대한 LLM의 손실(loss)을 줄이는 호출을 유지했습니다. 대규모 레이블이 없는 텍스트 데이터에 여러 API에서 호출을 사용하는 식의 레이블을 추가로 만들기에는 비용이 많이 들기 때문에 각 API를 언제 선택해야 하는지 알려주는 휴리스틱을 사용하였습니다^.
^예를 들어, 계산기 도구는 3개 이상의 숫자가 포함되어 있는 텍스트에만 사용한다는 등.
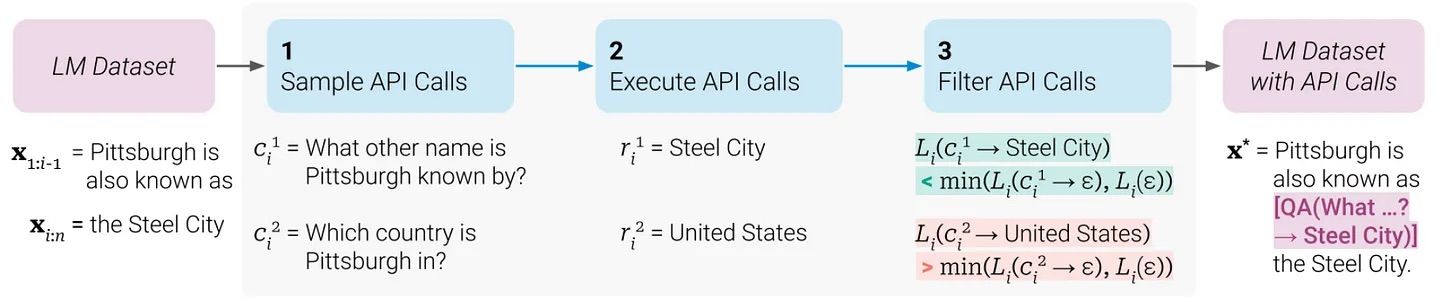
또한 언어 모델은 RLHF (Reinforcement Learning with Human Feedback)이나 하드코딩된 리워드 함수 같은 방식으로 강화 학습될 수도 있지만, 이는 학습이 매우 불안정한 것으로 나타났습니다 (논문 [6]).
도구 증강 LLM(Tool-augmented LLM)을 위한 플랫폼
현재 LLM이 워낙 다재다능하다는 것이 증명되었기에, 도구 증강 LLM은 빠르게 연구자들의 관심을 사로잡았습니다. 최근 여러 논문에서 도구 사용이 AGI (논문 [7,8])으로 향하는 길을 열어준다고 주장하고 있습니다.
도구 증강 LLM의 핵심 과제는 API와 언어 모델에 대한 접근성이라고 생각합니다.
최근 제안된 도구 증강 LLM 플랫폼들 몇 가지를 소개하겠습니다.
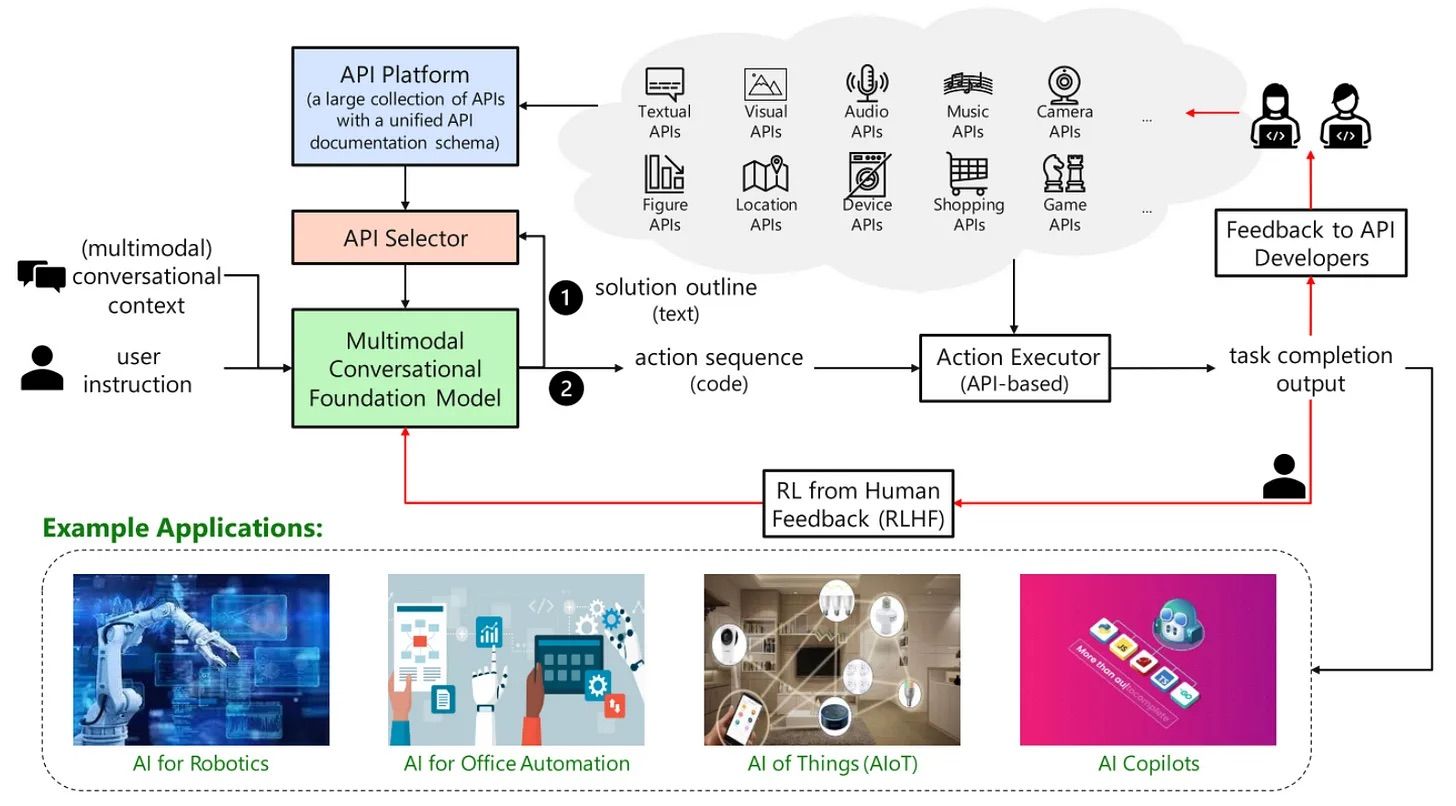
- TaskMatrix.AI(2023년 3월): LLM이 수백만 개의 API와 원활하게 인터페이스할 수 있는 생태계에 대한 비전을 가지고 있습니다. 이들의 프레임워크에는 기본 LLM, API 플랫폼 및 API 검색 엔진이 포함됩니다. 저자들은 모델이 주로 RLHF를 사용하여 API를 사용하는 방법을 배우기를 예상하지만, 이는 수백만 개의 API로 확장하기 어려울 수 있습니다. 그들은 ChatGPT를 사용하여 PowerPoint API와 인터페이스하는 케이스 스터디를 포함하였습니다.
- API-Bank(2023년 4월): few-shot prompting 설정에서 LLM의 도구 사용을 평가하는 벤치마크입니다. few-shot 설정에서 도구 사용을 가능하게 하기 위해 모델은 가장 관련성 있는 API에 대한 설명서를 반환하는 API 검색 엔진에 대한 쿼리를 생성해야 합니다. 저자들은 API-Bank를 사용하여 여러 기존 LLM을 평가하고 그들의 강점과 약점을 분석합니다.
- OpenAGI(2023년 4월): 다른 도메인별 모델에 대한 호출 체인이 필요한 Synthetic Multi-step, Mutl-modal dataset으로 구성된 벤치마크입니다. 모델은 제로샷, few샷, finetuning 또는 RL 기반 설정에서 평가될 수 있습니다.
- Gentopia(2023년 8월): 도구 증강 에이전트를 생성하고 공유하는 플랫폼입니다
돌아보며
몇 년 만에 이 분야가 얼마나 진보했는지를 돌아보면 정말 감탄을 금할 수 없습니다. 특히 현재의 위치에 이르게 한 몇 가지 동향과 발전이 있습니다.
도구 사용 과거와 지금
보조 모듈과 인터페이스하는 모델을 갖는다는 아이디어는 새로운 것이 아닙니다. 예를 들어, Neural Programmer-Interpreter는 다양한 도메인별 프로그램을 실행하는 방법을 배우기 위해 복잡한 신경망 아키텍처를 제시했었습니다. BERT에 계산기를 장착해 제한된 산술 연산에 대한 벡터 기반 연산이 정의되는 방식이 제안되기도 하였죠. 과거와 지금이 다른 점은 현재 LLM이 이전 모델보다 훨~씬 다재다능하다는 것입니다. 이를 통해 어떠한 API든 다재다능하게 사용할 수 있게 되었습니다.
Embeddings->Modules->Tools
5년 전에는 특정한 작업에 가장 적합한 임베딩 조합을 선택하는 방법을 학습하는 식으로 생각했었죠. 작년에는 주어진 작업에 대한 새로운 파라미터 효율(parameter-efficient)적인 모듈을 선택하는 방식이 사용되었습니다. 이제는 언어 모델이 다른 모델이나 임의의 블랙박스 도구를 선택하고 사용하는 방법을 배우는 단계에 있습니다.
수다(chitchat)->목표 지향 대화
어떠한 목표를 달성하거나 하나의 작업을 수행하기 위한 대화 (end-toend goal or task oriented dialogue)는 긴 시간 NLP 분야에서 매우 어려운 문제로 여겨져 왔습니다. 이전 모델은 Belief States를 기반으로 DB 정보를 쿼리했지만, 도구 증강 LLM은 수다 떨기(chitchat)에서 특정 목표 지향 대화로 더 매끄럽게 전환할 수 있을 것입니다.
도구 증강 LLM의 미래
앞으로 도구 증강 LLM은 다음과 같은 몇 가지 과제와 방향을 갖게 될 것입니다.
언어 모델을 위한 API 제공
(인터넷에는) LLM이 상호 작용할 수 있는 수백만 개의 API가 있습니다. (위에 언급한) API 플랫폼이나 ChatGPT Plugins와 같은 플랫폼은 API에 대한 액세스를 중앙 집중화하는 것을 목표로 하고 있는데, 이는 사용자들에게 큰 제한이 될 리스크가 있습니다. 이 분야의 연구가 좀 더 나아가려면 표준화된 API 셋를 개방적이고 자유롭게 사용할 수 있도록 하는 것이 중요합니다.
API 검색 및 확장성
가장 관련성 있는 API를 찾는 문제는 Alexa와 같은 가상 어시스턴트가 가장 적합한 스킬을 찾는 것과 유사합니다. 점점 커지는 API 풀에서 가장 관련 있는 API를 안정적으로 반환하는 검색을 갖추고 LLM이 새 도구로 쉽게 확장될 수 있도록 하는 것이 중요합니다.
도구 사용 방법 학습시키기
LLM에게 도구 사용 방법을 가장 잘 가르치는 방법은 여전히 해결되지 않은 문제입니다. 논문 [5]의 접근 방식은 한 번에 하나의 도구를 사용하는 것으로 제한되며 데이터셋을 효율적으로 강화하기 위해 도구별 휴리스틱이 필요합니다. 수백 및 수천 개의 API에 대한 (여러 단계) 시그널을 제공하고 확장할 수 있는 방법을 조사하는 것이 중요합니다.
도구 증강 LLM 사전 학습(pretraining)하기
API의 다양성과 사용 사례를 고려할 때 도구 증강 LLM을 학습하기 위해 더 큰 예산을 할당되는 것이 합리적이라고 생각됩니다. 사전 학습된 모델은 도구 사용에 맞게 Finetuning할 수 있지만, 도구 증강 LLM을 사전 학습하면 모델은 학습 초기에 특정 동작을 없애고 도구에서 포착되지 않는 부분을 학습하는 데 집중할 수 있습니다.
추론 및 문제 쪼개기
추론과 도구 사용은 밀접하게 연결되어 있습니다. 문제에 대해 올바른 API를 호출하려면 더 간단한 하위 작업으로 쪼개야 합니다. 열린 문제를 가장 잘 쪼개는 방법 역시 해결되지 않은 새로운 영역입니다.
API 에러 핸들링하기
검색엔진 같은 다른 엔진이나 도구 역시 에러에 자유롭지 않습니다. 이 때문에 추후 답변 생성에 더 큰 에러로 누적될 수 있습니다. LLM은 각 API의 안정성을 평가하고 API 에러로부터 복구하는 방법을 배워야 합니다.
도구 사용에 대한 더 나은 이해 얻기
모델이 도구를 사용하고 도구와 소통하는 인터페이스에 관해서 아직은 많은 부분이 제대로 연구되지 않았습니다. 예를 들어, 모델이 어느 정도로 예측된 추론 단계를 사용하여 최종 답변을 생성하는지는 알 수가 없습니다. 따라서 도구 증강 LLM을 분석하고 진단하는 툴을 개발하는 것이 중요합니다.
전반적으로 도구 사용은 현재 LLM의 한계 중 일부를 해결할 수 있고, 동시에 더 똑똑하면서 더 해석 가능(interpretable)하게 만들 수 있습니다. 이 분야의 향후 어떻게 더 발전하게 될지 기대됩니다!
Reference
[1] Mialon et al. (2023), Augmented Language Models: a Survey
[2] Hendrycks et al., 2021 Measuring Mathematical Problem Solving With the MATH Dataset
[3] Hsieh et al. (2023), Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models
[4] Parisi et al. (2022), TALM: Tool Augmented Language Models
[5] Schick et al. (2023), Toolformer: Language Models Can Teach Themselves to Use Tools
[6] Mialon et al. (2023), Augmented Language Models: a Survey
[7] Li et al., 2023, API-Bank: A Benchmark for Tool-Augmented LLMs
[8] Ge et al., 2023, OpenAGI: When LLM Meets Domain Experts



