Week 11 - 머신러닝 모델이 데이터를 공부하는 방법


대부분의 우리는 등산을 하러 가면 정상에 도달하자라는 하나의 목표를 가지고 열심히 걷습니다. 시작점에 있는 지도를 보기도 하고, 중간에 있는 팻말이 가리키는 방향을 보기도 하고, 사람들에게 물어보기도 합니다. 정말 모르겠으면 일단 보이는 오르막을 무작장 오르기도 합니다. 그렇게 해서 봉우리에 올라와서 사방을 바라보았을 때 여기보다 더 높은 봉우리를 보지 못한다면 "아, 드디어 정상에 도달했구나!"라며 느낍니다.

Week 7에는 언어를 함수로 볼 수 있기 때문에 NLP와 머신 러닝은 떼놓을 수 없는 관계라는 이야기를 하였습니다. 우리가 아는 함수는 이렇게 표현되고는 합니다.
y = f(x)
(여기서 x는 input, y는 output)
예를 들어 x는 영화 대사, y는 반말(0)이냐 존댓말(1)이냐라고 합시다. 만약 어떤 관객이 x를 들었을 시, 즉시 y를 결정할 수 있을 것입니다.
(x, y)
("라면 먹고 갈래요?", 1),
("혼자니?", 0),
("어 아직 싱글이야", 0),
("눈사람 같이 만들래요?", 1)
영화 몇 편만 보면 벌써 몇 백개 또는 몇 천 개의 (x, y) 쌍을 만들 수 있을 것입니다. 이러한 데이터가 있으면 우리는 존댓말과 반말을 판단할 수 있는 NLP 모델을 학습시킬 수 있지요.
우리는 이미 이러한 자연어 input x들을 어떻게 수학적으로 표현할 수 있는지 지난 몇 주간 알아보았습니다. 문장을 가방으로 표현한 Bag-of-Word도 배웠고, 그림처럼 보는 CNN도, 컨베이터 벨트에 넣는 RNN도 배웠습니다. 그리고 y가 0과 1이라는 것이 주어졌을 때를 binary classification 문제라고 부르고, 확률 모델로 바꾸어 풀어보기도 하였습니다.
함수 f(x)는 input이 어떻게 표현되느냐에 따라 달라집니다. 만약 텍스트인 x가 word2vec처럼 100-dimension vector로 표현된다면 f(x)는 100차원 방정식 또는 그 이상이 되어야 합니다.
하지만 우리는 100차원을 쉽게 이해하기는 힘드니, 좀 더 간단하게 2차원으로 생각해봅시다. 위 데이터에서 각 x는 이런 식으로 평면에 표현될 수 있을 것입니다.
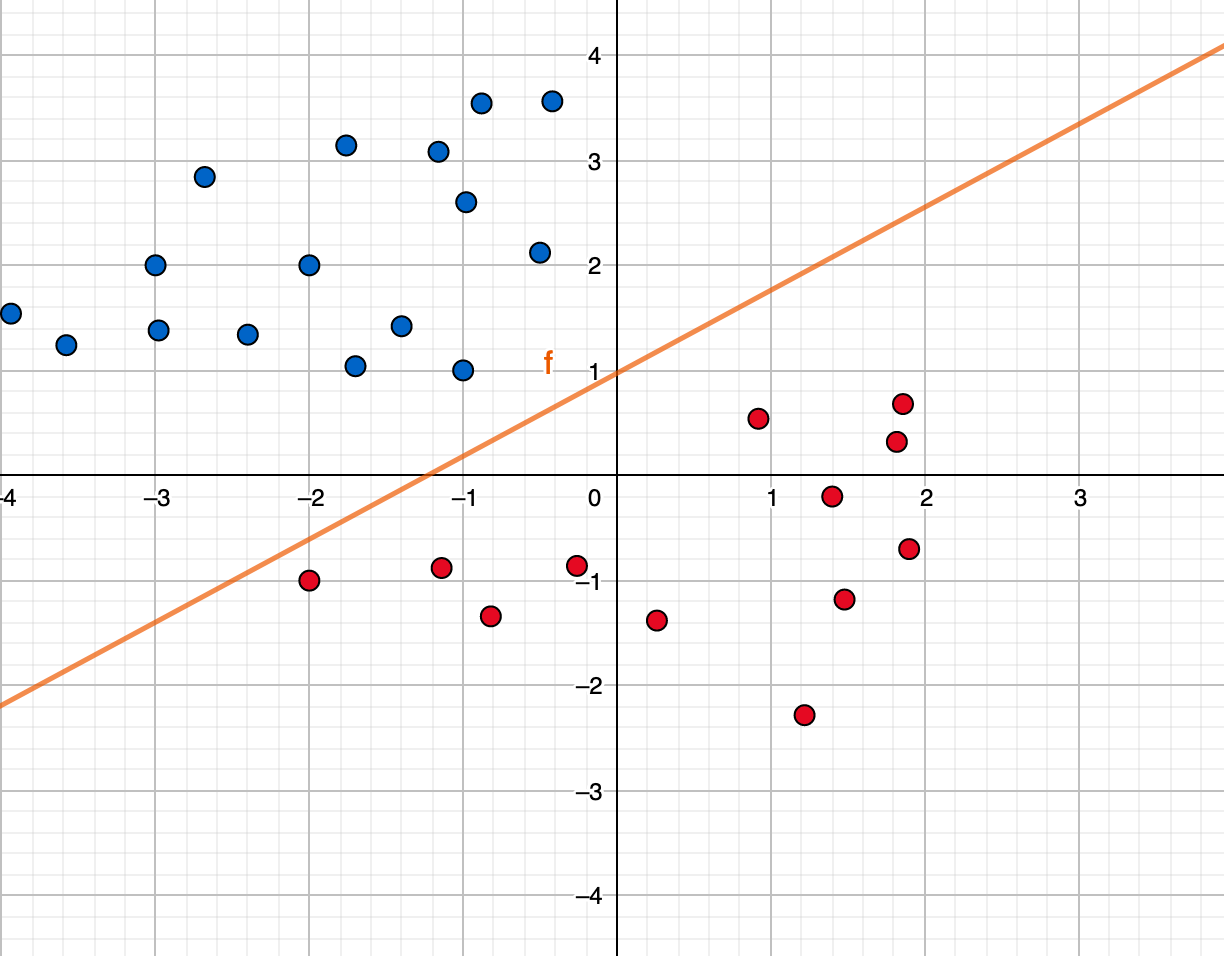
만약에 우리가 존댓말 데이터와 반말 데이터를 분리하는 경계선을 그린다면 위 오렌지 선으로 표현될 수 있겠죠. 하지만 문제는 머신러닝 모델이 데이터를 전부 살펴 보고 계산하기 전에는 저 오렌지 선을 그리기 쉽지 않다는 점입니다. 처음에 시작할 때는 데이터를 보지 않아 아무런 정보가 없기 때문에 아래처럼 대충 아무렇게 긋습니다.
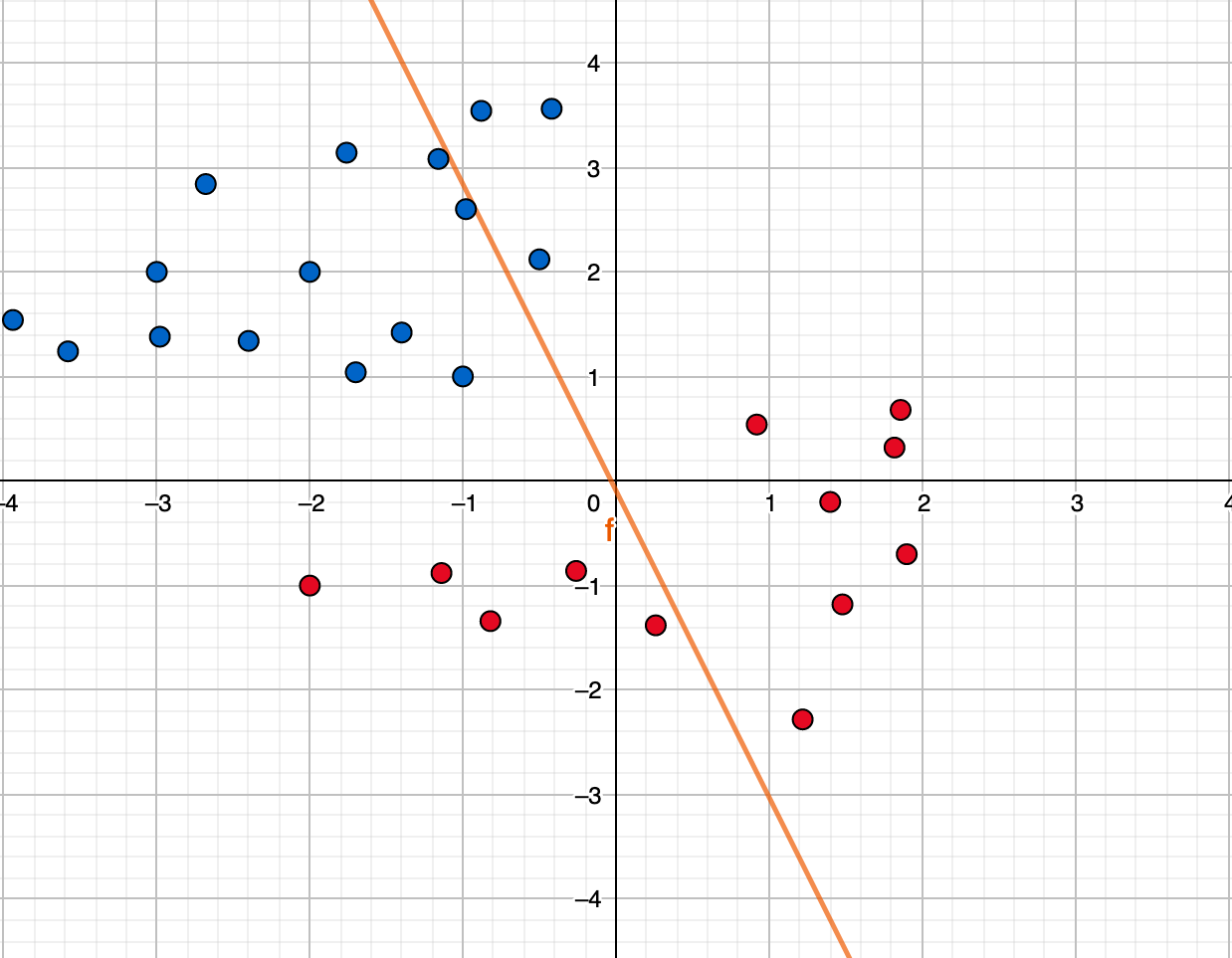
머신러닝 모델은 이렇게 대충 그어놓고는 데이터를 하나하나 보면서 고쳐나갑니다. 이런걸 모델이 학습(learning)을 한다라고 표현합니다. 점차적으로 우리가 원하는 첫번째 그래프의 이쁘게 가운데에 그어진 오렌지 선이 우리의 최종 목표인 것이지요.
근데 문제는 머신러닝 모델은 우리처럼 똑똑하지 못해서 모든 데이터를 한눈에 파악하지 못합니다. 그리고 모든 데이터가 저렇게 2차원의 나타낸 예시처럼 쉽게 경계선이 보이지도 않습니다. 머신 러닝 모델은 어떻게 학습을 통해 알맞은 경계선을 찾아가는걸까요?
Cost function을 그려 나아가자
머신러닝 모델이 학습을 하는 과정도 우리가 등산을 하는 것과 비슷합니다. 다만 다른 점은 우리처럼 지도를 볼 수 없고, 시력도 근시라 정상에 올랐을 때도 가까운 지점 말고는 볼 수 없기에 이곳이 정상인지 아닌지 알지를 못합니다. 그렇다면 머신러닝 모델은 어떤 목표를 가지고 앞으로 나아가는 걸까요? 바로 핵심은 cost function (비용 함수)입니다.
경제 과목에서는 비용은 줄여나가야 좋은 것이라고 배우죠. 머신러닝에서는 현재 모델이 얼마나 목표(objective)와 멀어져 있느냐를 cost function으로 계산합니다 (그래서 loss function 또는 objective function이라고도 합니다). 머신러닝의 본질은 cost를 최소화(minimize) 하는데에 있습니다.
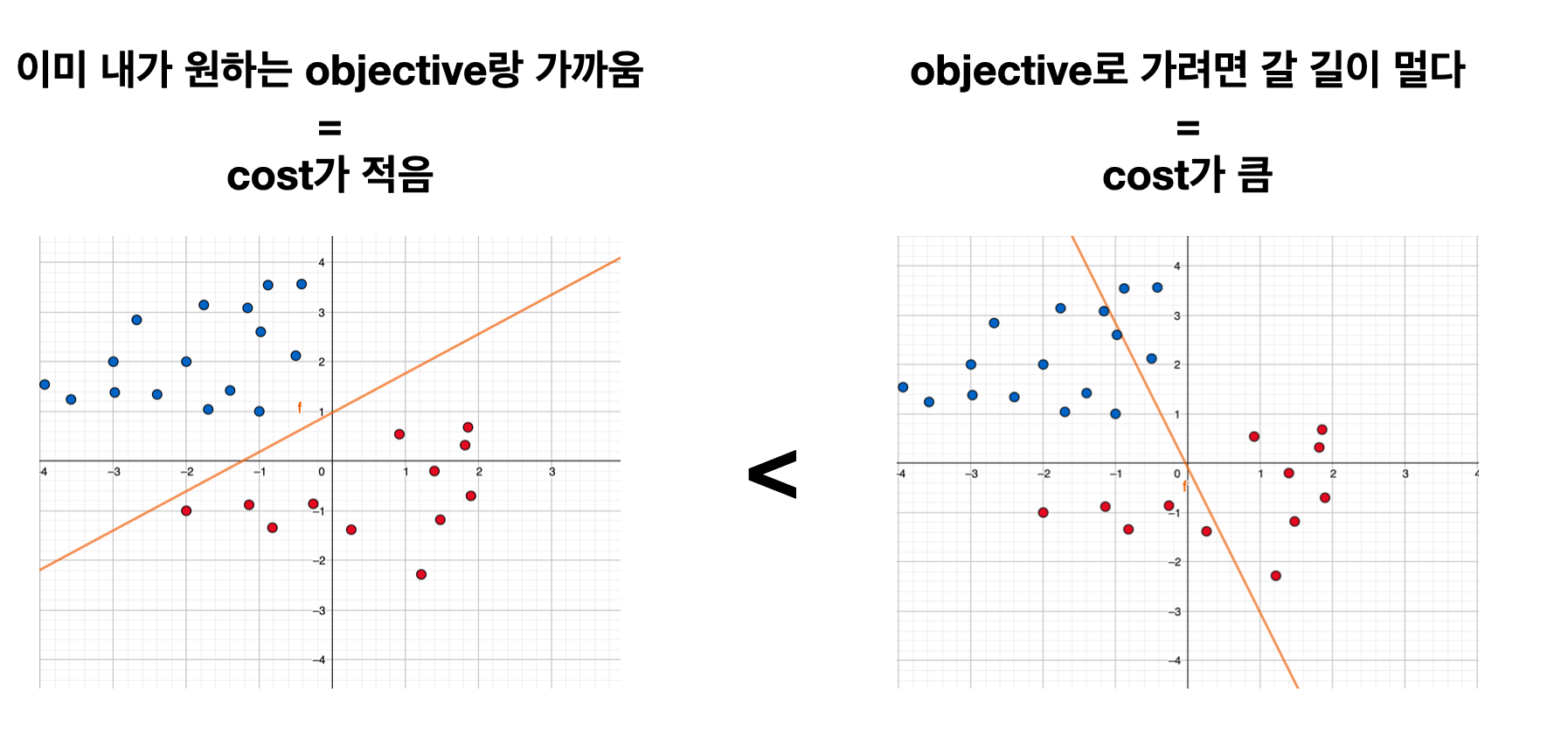
Cost는 현재 그려진 선이 얼마나 학습 데이터에 잘 맞는지 계산하여 합한 것입니다. 다시 위 그래프 두 개를 보면, 첫 번째 그래프의 선이 두 번째 보다 더 학습 데이터에 잘 맞기에 cost가 첫 번째가 더 작을 것입니다.
어떻게 f(x)가 바뀌냐고요? 바로 함수의 파라미터(parameter)를 조금씩 변형해갑니다. 2차원 방식에는 함수가 두가지죠. 기울기 a와 y절편 b. (뇌를 중학교로 잠깐 돌립니다..)
y = ax + b
우리는 a와 b를 합쳐서 function weight(w)라고 부릅니다. 2차원 함수는 w가 두개지만, 더 복잡한 함수는 w가 더 많겠죠? 심지어 최신 deep learning 모델들은 w가 몇 백만 개, 몇 억개까지 늘어나기도 합니다.
w가 바뀌면 그때그때 같이 바뀌는 cost function를 또 다른 그래프로 그리면 아래처럼 표현할 수 있습니다.
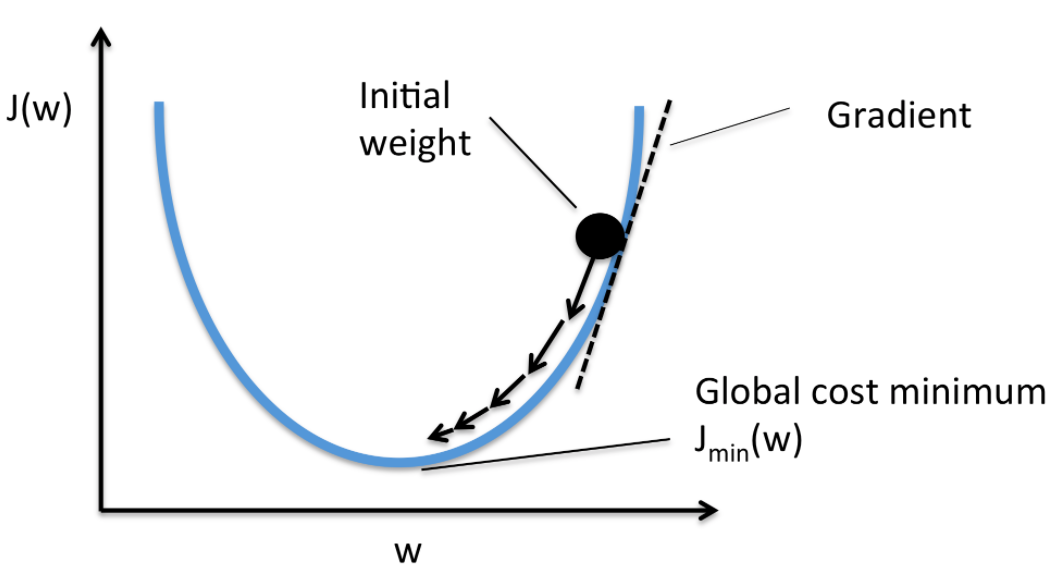
우리의 목표는 Cost가 가장 낮은 지점 (global cost minimum)을 찾아야 합니다. 데이터를 하나하나 보고 계산해보면서 시행착오를 통해 도달하는 것입니다. 이 과정이 마치 정상을 찾아가는 등산의 과정과 비슷합니다. 다만 이 함수의 정상은 가장 낮은 지점에 있다는 게 다릅니다.
또 다른 문제는 한 발자국 움직일 때 내가 가진 모든 데이터를 다 계산해보고 결정하는 것은 너무나 시간이 오래 걸립니다.
예를 들어, 길을 물어볼 때도 내가 아는 사람 100명에게 물어보고 한 발자국을 움직이는 것이 아니라 일단 주변 1~2명한테 물어보고 움직인 후, 목적지에 가까워졌다고 느껴질 때 추가로 1~2명한테 물어보아 정확한 위치를 찾고는 하지 않습니까. 그렇다면 중간중간 조금 틀린 방향으로 가더라도 결국에는 목적지에 도달할 수 있습니다.
이러한 방식으로 minimum을 찾는 방식을 Stochastic Gradient Descent (SGD)라고 합니다 (실제로 Gradient는 산의 경사를 뜻하는 영어 단어입니다). 머신 러닝을 공부하신 분들은 정말 많이 들어보고 공부해야 하는 토픽인데요. 위클리 NLP에서는 이정도만 공부하고 넘어가겠습니다.
오늘은 머신 러닝이 어떻게 데이터를 통해 학습을 하는지 배워보았습니다. 최대한 쉬운 수학으로 설명하려고 노력을 했지만 너무 어렵지 않았나 걱정이 됩니다. 반대로 머신 러닝을 공부하신 분들은 너무나 많은 수학적인 부분이 생략되어 있기에 "이게 무슨 설명이냐"라고 느끼실까봐도 걱정이 되네요.
어찌되었든 앞으로 나오는 모든 NLP 문제의 뿌리에는 오늘 공부한 cost function과 gradient descent 방식이 적용되기에 어렵더라도 간단하게라도 짚고 넘어가지 않을 수 없었습니다. 앞으로도 수학적인 머신 러닝 개념이 나온다면 이 정도 레벨에서 설명해보려고 노력하겠습니다!

References
- Deep Learning, Chapter 8: Optimization for Training Deep Models, Ian Goodfellow, Yoshua Bengio and Aaron Courville, http://www.deeplearningbook.org/contents/optimization.html
- Machine Learning Week 1: Cost Function, Gradient Descent and Univariate Linear Regression, https://medium.com/@lachlanmiller_52885/machine-learning-week-1-cost-function-gradient-descent-and-univariate-linear-regression-8f5fe69815fd
- Gradient Descent 탐색 방법, 다크프로그래머님 티스토리 블로그, https://darkpgmr.tistory.com/133




