Week 17 - 딥러닝이 언어 모델에 필요한 이유


지난 2주 간 인공지능이 우리의 말귀를 알아들으려면 발음 모델 그리고 언어 모델을 학습해야 한다고 공부했습니다. 생각해보면 우리는 정말 많은 단어를 머리 속에 담고 무수히 많은 조합으로 문장을 쓰거나 대화를 합니다. 난생 처음 보는 글을 읽을 때도 (제대로 쓰인 글이라면) 자연스럽게 작가가 하려는 말을 이해할 수 있습니다. 새로운 조합의 단어도, 심지어 단어를 섞어 만든 신조어도 우리는 금방 의미를 알아챕니다.
이렇게 매일 수백번도 하는 여러분의 언어적인 능력이 생각보다 굉장히 높은 지능이라고 생각해보신 적이 있나요? NLP에서 언어 모델의 원리를 공부하다보면 인간에게 간단한 것이 꼭 수학적으로 풀었을 때는 그렇지 않다는 것을 느끼실 수 있습니다.
이번 주에는 Week 15에서 공부한 n-gram LM 모델의 한계에 대해 이야기해보고, 다음 단어를 더 잘 예측하기 위해서 어떻게 LM이 발전하였는지 공부해보겠습니다.
학교에서 선생님의 수업을 매주 따라가다 보면 부분 부분 내용은 기억이 나는데, 이것들이 어떻게 다 연결이 되는지 큰 그림은 잘 이해가 안 되는 때가 많습니다. 저는 그럴 때마다 각 주의 가장 핵심 부분을 공책에다가 옮겨 적고 한 번에 바라보고는 했는데요. 이번 주 첫 시작은 여러분의 큰 그림의 이해를 돕기 위해 그렇게 해보려고 합니다.

LM 여태까지 한 것 정리
- 언어 모델 (Language Modeling; LM)이란?: 어떤 문장이 주어졌을 때, 이 문장의 그럴듯함을 확률로 계산하는 모델
- LM은 어떻게 학습하는가: 큰 텍스트 데이터 셋(corpus)을 학습 데이터로 사용하여 통계 모델을 구축함.
- N-gram LM이란?: 데이터 셋에 나오는 단어 또는 연속되는 단어들의 빈도를 계산하여 LM을 만든 모델.
- LM은 무엇을 할 수 있는가? a) 여러 가지 문장이 주어졌을 때 가장 그럴듯한 문장을 뽑을 수 있음, b) 문장의 앞부분이 주어졌을 때 다음 단어를 예측할 수 있음.
- 그렇다면 n-gram LM은 한계는 무엇인가?
- 그 한계를 극복하기 위한 방법은?
이번 주는 5와 6의 질문을 답을 하면서 Neural Language Modeling을 소개해보려고 합니다.
n-gram LM의 첫 번째 한계: 못 본 단어 조합은?
우리가 영어 공부를 하고 있다고 상상해봅시다. play라는 단어를 공부하면서 예문을 읽어보죠.
play soccer play basketballplay pingpongplay gameplay chess
자연스럽게 우리는 "play라는 단어 다음에는 스포츠나 게임 같은 것이 쓰일 수 있구나"라고 유추할 수 있습니다. 그렇기에 다음번 지문에 생전 처음 play dart라는 단어 조합이 나오면 처음 본다 해도 이해할 수 있을 것입니다. play와 dart가 함께 있는 것은 본 적은 없지만, dart가 게임의 일종이라 ping-pong, game, chess 등과 비슷한 단어라는 것을, 그리고 play가 함께 쓰일 수 있다는 것을 다른 데이터를 통해 알고 있기 때문이죠.
하지만 n-gram LM에서는 이러한 경우가 어떻게 될까요? play dart라는 bi-gram (n=2)은 학습 데이터에 존재하지 않기에, 이 단어 조합이 들어간 문장의 확률은 항상 0으로 수렴하게 됩니다.
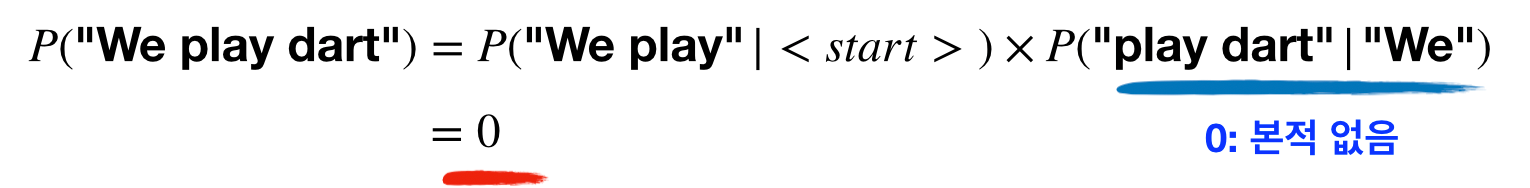
이를 머신 러닝 용어로는 모델의 일반화 능력이 떨어진다(lack of generalization ability)라고 합니다. 즉 데이터로부터 배운 것으로 보지 못한 것에 대해 적합한 예측을 하지못한다는 것이죠. 이러한 한계가 생기는 이유는 n-gram LM에서는 각 단어를 전부 독립적인 상관없는 feature로 보기 때문입니다. 우리처럼 여러 단어들 (soccer, basketball, ping-pong, game, chess 그리고 dart)의 유사성 같은 관계를 전혀 고려하지도, 학습할 수도 없습니다. 혹시 이 한계, 데자뷔 같지 않나요?
네 맞습니다. Week 1에서 배운 one-hot embedding의 한계점과 같습니다. 그렇기 때문에 Week 3에 배운 Word embedding이 다시 등장합니다!
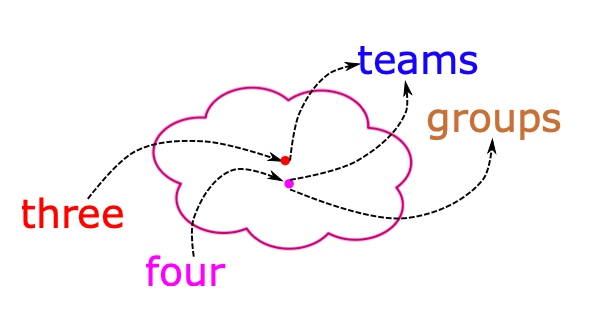
Word Embedding 모델은 각 단어들을 vector로 바꾸어 vector space에서 적당한 위치에 배치할 수 있도록 학습됩니다. 여기서 적당하다는 것은 비슷한 뜻을 가진 단어들은 모여 있게 만들고, vector를 더하거나 빼보면서 문법(syntactic) 그리고 의미적(semantic) 관계도 보여줄 수 있다는 것을 의미합니다. 가장 대표적인 word embedding은 word2vec과 glove가 있는데, 자세한 내용은 Week 3에서 복습하시면 좋을 듯합니다.
이렇게 Neural LM은 word embedding을 이용함으로써 n-gram LM이 가진 첫 번째 한계점을 극복합니다.
n-gram LM의 두 번째 한계: 기억력이 안 좋다?
"In Korea, more than half of all the residents speak _____."
다음 빈칸에 들어가야 할 단어는 무엇일까요? 너무 쉽죠? 앞에 "In Korea"라고 나오니 "Korean"이겠죠. 우리처럼 n-gram LM 역시 이 문제를 쉽게 맞힐 수 있을까요?
Week 14에서 n-gram LM을 소개했을 때 다음 단어를 예측할 때 바로 직전 2~4개의 단어만 고려할 수 있다는 이야기를 하였습니다. n이 커지면 커질수록 계산해야 하는 것이 많아져 n-gram LM은 너무 멀리있는 과거 단어를 고려하는 것이 불가능합니다.
그렇기에 위 예시처럼 단어를 예측하기 위한 정보가 많이 떨어져 있다면, n-gram LM은 어떻게 할 도리가 없습니다. n=3이라면 resident와 speak라는 정보만 가지고 예측해야 합니다. 그렇기에 모델은 "japanese", "english", "korean" 모두 비슷한 확률로 계산할 것입니다. 우리가 읽을 때는 앞에 "Korea"라는 단어가 나오기 때문에 "korean"이 가장 그럴 듯하다는 것을 쉽게 알 수 있지만요.
이러한 문제를 long term dependency라고 합니다. 사실 이 단어 역시 제가 전에 언급한 적이 있습니다. 바로 Week 7에서 Recurrent Neural Network (RNN)을 소개하면서 이야기했지요! Neural LM의 초창기 연구들은 RNN을 사용하는 것으로 이 문제점을 해결하기 시작합니다.
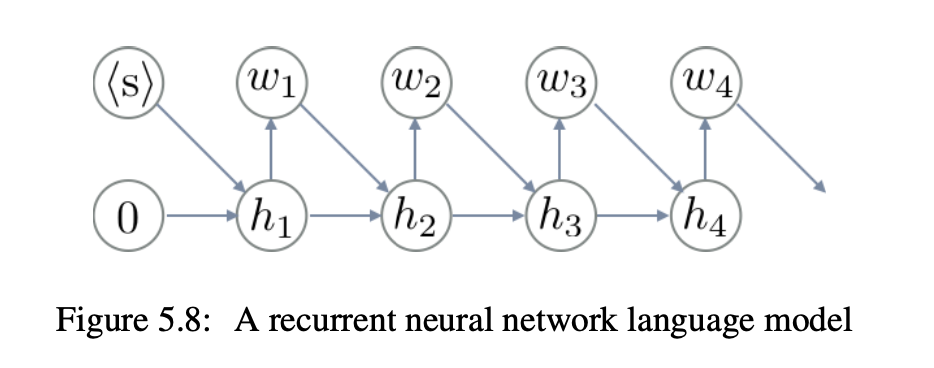
다음 주에는 Neural LM의 시초인 RNN LM에 대해서 공부해보도록 하겠습니다. 이렇게 간단한 카운팅으로 시작한 n-gram LM이 발전하여 RNN LM이 되고, 나중에는 2020년 8월 세상을 놀래킨 GPT-3까지 발전하는 NLP 기술의 원리를 차근차근 여러분께 알려드리려고 노력하고 있습니다.
오늘은 이 글뿐만 아니라 word embedding (week 3)와 RNN (week 7)를 꼭 복습하시면서 읽으시기를 추천드립니다.

Reference
Kyunghyun Cho, Chapter 5: Neural Language Models, Natural Language Understanding with Distributed Representation



