Week 18 - 기억력이 훨 좋은 딥러닝 언어 모델 등장! RNN LM


"시장에 가면~ 바나나도 있고, 닭다리도 있고, 수박도 있고, 아이스크림도 있고~" 이 게임 기억나시는 분 있나요? 정말 옛날에 술자리에서 랜덤 게임을 하면 정말 드문 확률로 이 고전 게임이 시작되기도 했는데... (제가 너무 아재인가요;;) 어쨌든 이 게임의 가장 중요한 포인트는 내 앞사람들이 고른 시장 아이템들을 순서대로 기억해야 한다는 점입니다. 운이 좋게 시작점에서 멀지 않게 앉았다면 2~3개만 외우면 되지만, 그 이후로는 점점 더 외울게 많아져서 저는 몇 차례 돌아 제 차례가 되면 그냥 술잔을 들고는 했습니다... 가끔 기계도 아닌 사람인 친구가 몇 개가 되든 끄떡없이 술술 다 기억해내는 경우가 있었죠 (그 친구는 지금은 뭐할라나).
저는 n=3 정도 되는 n-gram langauge model이고, 그 친구는 아주 성능이 좋은 딥러닝 언어 모델(neural language model)입니다.
지난주에 n-gram LM이 가지는 단점에 대해서 이야기했습니다. 못 본 단어에 대한 일반화( generalization) 그리고 기억력이 좋지 않다는 점(long-term dependency), 이 두 가지가 키 포인트였지요. 그리고 이를 극복하기 위해 RNN 모델이 쓰인다고 하고 마무리했습니다. 이번 주에는 RNN이 어떻게 딥러닝 언어 모델에 쓰이는지, 어떻게 학습되는지 이야기해보려고 합니다.

딥러닝 모델 RNN을 이용한 Language Model
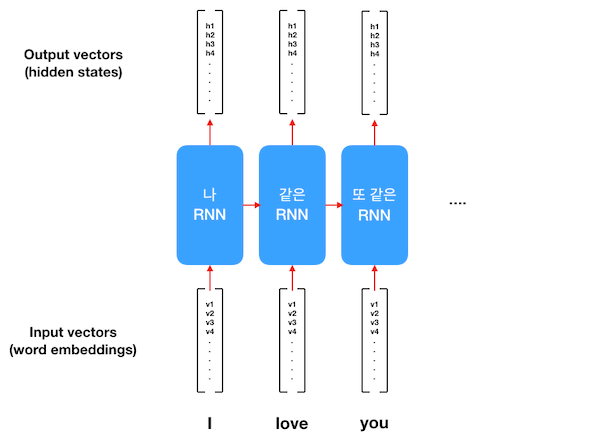
RNN은 "메모리를 저장하는 네트워크이다."라고 우리는 이미 배웠습니다. 왜냐하면 Hidden state라는 걸 가지고 있어서, 여태까지 들어왔던 인풋에 대한 정보를 저장하고 있습니다. 위 그림을 한번 봅시다.
일단 input vector로는 word embedding이 컨베이어 벨트처럼 하나씩 RNN으로 들어갑니다. 여기서 [v1, v2...]로 표현된 word embedding은 Week 3에서 설명한 N개의 실수로 구성된 N차원 vector입니다. word2vec 같은 pretrained word embedding을 사용해도 좋고, 데이터가 많다면 처음부터 학습해도 상관없습니다.
RNN에 word embedding 한 개가 들어가면 output vector가 하나 나옵니다. 바로 이게 RNN의 hidden state입니다. 역시나 M개의 실수로 구성된 M차원 vector입니다 (word embedding의 N과 크기가 다를 수 있어 M으로 표현합니다). 이렇게 각 단어가 들어갈 때마다 같은 모델에서 다른 hidden state들이 output vector로 나오게 됩니다.
그렇다면 어떻게 RNN을 LM을 만든다는 것일까요? 다시 LM의 정의로 돌아가 봅시다.
어떤 문장이 주어졌을 때, 이 문장의 그럴듯함을 확률로 계산하는 모델
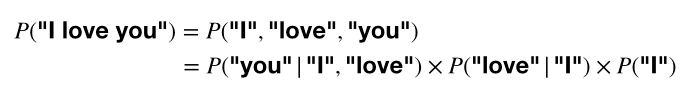
이런 결합 확률(joint probability)을 활용해 chain rule로 풀어서 쓸 수 있습니다. "I love"가 이미 있을 때, "you"가 올 확률; "I"가 이미 있을 때 "love"가 올 확률; "I"가 문장 처음에 쓰일 확률.
n-gram LM은 바로 이 chain rule을 단순화합니다. 기억상실증처럼 바로 직전 2~3개만 고려하죠. 하지만 RNN은 문장 끝까지 봅니다!

Target 단어인 sentence를 예측하려고 할 때, bigram, trigram LM이 고려하는 과거 (초록색, 하늘색 밑줄) 그리고 RNN LM이 고려하는 과거 (분홍색) 입니다.
이것이 가능한 이유는 바로 hidden state라는 메모리 안에 여태까지 본 단어들의 정보가 모두 압축되어 들어가 있기 때문이죠. (이론 상으로는 그렇습니다. 한계가 있기는 합니다.)
RNN 학습시키는 방법?
위 설명을 이해하셨다면 RNN LM을 학습시키는 것은 쉽습니다. 바로 hidden state를 가지고 다음 단어를 예측하게 하는 것입니다. 가지고 있는 학습 데이터를 가지고 하나하나 가르치면 됩니다.
여기서 다시 나오는 중요한 개념은 vocabulary입니다. RNN LM은 세상 모든 단어를 예측할 수 없습니다. 그렇기 때문에 학습 데이터에 존재하는 단어들, 그리고 그중에도 빈도수가 어느 정도 되는 단어들을 가지고 vocabulary 리스트를 만듭니다. (이는 Week 1에서 one-hot vector를 소개할 때도 잠깐 나온 개념이죠. 각 단어에 숫자를 부여합니다.) 모델의 크기에 따라 몇 천 개에서 몇 십만 개의 단어를 vocabulary로 구성합니다. 빈도 수가 부족한 단어는 unknown token이라는 특별한 기호로 퉁쳐버립니다.
예를 들어, 2만 개 짜리 vocabulary를 만들면 RNN 모델은 다음 단어로 2만 개 중 1개를 예측해야 하는 겁니다. 여러 보기 중 한 개를 예측해야 하는 건 머신 러닝에서 분류 (classification)라고 부릅니다. Week 5에서 배운 "스팸 메일이냐 아니냐" 역시 classification 문제입니다.
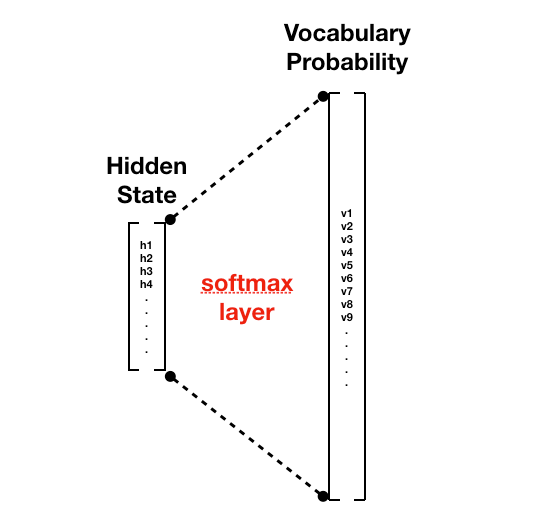
여러 개 중 하나를 선택하는 문제를 모델링하기 위해서는 소프트맥스(softmax layer)을 이용합니다. Softmax layer는 딥러닝 모델 중 가장 일반적인 fully connected layer에 마지막에 softmax function이란 함수를 사용한 것입니다. 이 함수는
softmax function은 어떠한 N개의 숫자가 있을 때, 어떠한 확률 점수(probability score)로 만듭니다. (확률 점수란 다 합하면 1.0, 각각 0 이상인 실수를 말합니다)
위 그림을 보시면, hidden state 벡터와 softmax layer를 연결해 vocabulary에 있는 단어의 숫자만큼의 벡터로 만듭니다. 이렇게 모든 단어에 대해 다음에 나올 확률을 계산한 것이 Vocabulary Probability입니다.
아래 그림은 Softmax Layer가 계산한 확률 점수의 예시입니다. RNN 모델이 "나는 자전거를"의 다음 단어로 "탄다"를 51%, "산다"를 22%, "고친다"를 20% 등으로 예측을 한 경우입니다.

물론 RNN을 처음 만들어서 확률을 계산하면 엉망일 수밖에 없습니다. 학습 데이터를 통해 모델을 점점 개선시켜 나아가야 하죠. 모델이 데이터를 공부하는 방법은 Week 11에서 배웠듯이, 어떠한 cost function이 필요합니다. 머신러닝 모델은 cost function에서 나오는 숫자를 줄여나가면서 학습을 한다고 배웠었죠.
Softmax 같은 경우에는 cross-entropy function 이라는 짝이 있습니다. Cross-entropy function은 NLP 뿐만 아니라 모든 머신 러닝 관련 분야에서 굉장히 중요한 cost function이기 때문에 깊이 더 공부하시는 것을 추천드립니다.
아래 그림과 같이 모델이 다음 단어를 예측한 확률 분포가 있으면, 이와 학습 데이터에서 나오는 정답과의 차이를 수치화한 함수입니다. 만약 모델이 잘 학습이 되었다면 이 함수의 값인 cost가 0에 가까울 것이고, 만약 아직 갈 길이 멀다면 cost 값이 클 것 입니다.
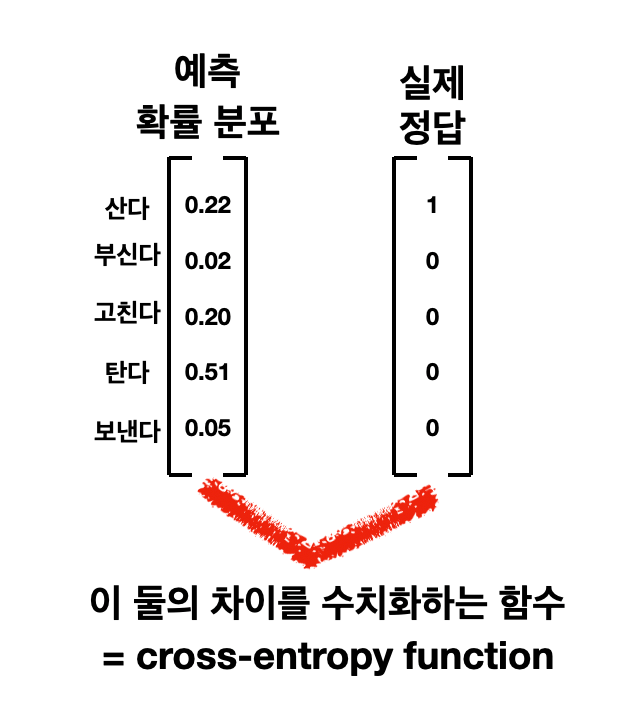
여기서 실제 정답은 아무 글이나 활용하여 만들 수 있습니다.
예를 들어, "I love you"와 "This is a sentence"라는 두 문장이 있다면:
(input x, output y) # x가 주어졌을 때, y를 예측하기
([], "I")
(["I"], "love")
(["I", "love"], "you")
([], "This")
(["This"], "is")
(["This", "is"], "a")
(["This", "is", "a"], "sentence")
이렇게 7 개의 학습 데이터가 만들어질 수 있습니다. 이렇게 따로 labelling을 필요로 하지 않고 자동으로 생성해낼 수 있기에 language modelling은 비지도 학습(unsupervised learning)으로 구분하기도 합니다.
이렇게 RNN을 이용하여 Neural LM이 다음 단어를 예측하는 방식으로 학습된다는 것을 알아보았습니다. 사실 수학적인 내용을 매우 매우 간단하게만 설명하고 넘어간 부분이 많습니다. 또한 RNN 역시 다양한 종류가 있습니다. 오늘 설명한 RNN의 원리는 가장 단순한 초기 버전으로 개념 이해를 돕기 위한 것입니다. 실제로는 Week 10에 소개해드린 LSTM과 GRU이 많이 쓰입니다. 하지만 기본 컨셉은 같습니다. 그저 RNN을 더 강력하게 만들기 위해 고안된 모델들입니다. 이러한 수학적인 내용과 더 많은 RNN들의 종류를 알고 싶은 분들을 위해 아래 reference를 넣어 놓았으니 참고하시길 바랍니다!

Reference
- Kyunghyun Cho, Chapter 5: Neural Language Models, Natural Language Understanding with Distributed Representation
- Jurafsky & Martin, Chapter 9: Sequence Processing with Recurrent Networks, Speech and Language Processing
- Abigail See, Lecture 6: Language Models and Recurrent Neural Networks, Stanford CS224N: Natural Language Processing with Deep Learning.
- Deeplearning.ai Coursera course, Softmax regression, Training a softmax classifier,<Improving Deep Neural Networks: Hyperparameter tuning, regularization and Optimization>
- Udacity course, Cross Entropy, "Deep Learning"
- Naoki Shibuya, Demystifying Cross-Entropy, Medium article
- 한글자료: 위키독스, 순환 신경망 (RNN), https://wikidocs.net/48558



