Week 22 - 딥러닝 기계번역 모델 seq2seq 깊게 파보기


지난주에는 최근 몇년 간 기계번역 분야의 비약적인 성장에는 딥러닝 기반의 neural machine translation (NMT)의 seq2seq 모델이 있다는 것을 소개하며 간단히 모델의 구조에 대하여 공부해보았습니다.
그렇다면 seq2seq 모델은 어떤 방법으로 학습이 되는 걸까요? 어떻게 번역된 문장을 생성할까요? 그리고 번역의 퀄리티는 어떻게 평가가 되는 걸까요? 공부하면 할수록 궁금한게 많아집니다.
이 질문들을 한 개씩 깊게 들어가면 정말 깊게 들어갈 수 있습니다. 각각 기계번역의 연구의 세부 분야로 전부 이해하기는 쉽지 않은 주제입니다. 그래도 여러분들이 최대한 이해할 수 있도록 쉽게 풀어써보도록 하겠습니다. 그게 위클리 NLP를 시작한 저의 목표이니깐요!
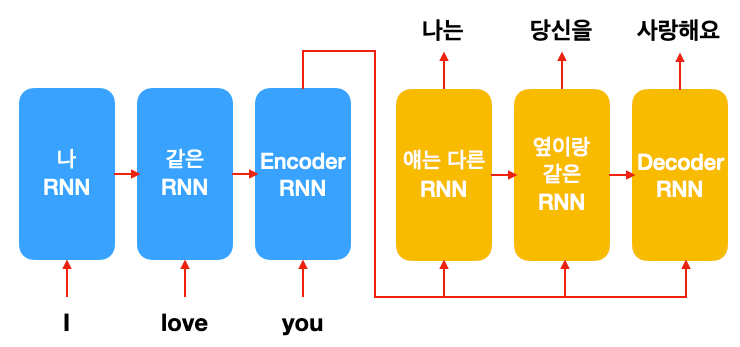

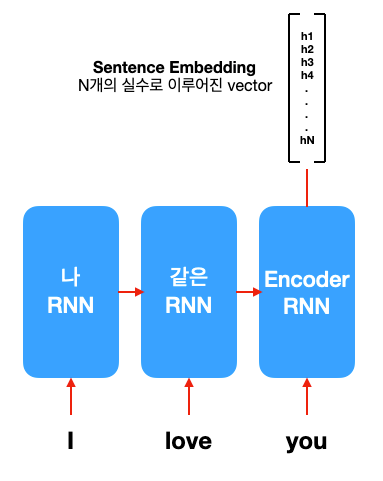
Encoder RNN: input 문장 읽고 이해하기
번역을 하려면 일단 주어진 문장을 읽고 이해해야겠죠. 위 그림에 파란색으로 표현된 encoder RNN은 번역해야 할 문장(input; source)을 한 단어씩 읽습니다. 하나의 단어가 들어갈 때마다 RNN의 hidden state가 바뀝니다. (RNN 복습하기) 이는 모델이 문장에 대한 이해를 단어를 한개씩 읽을 때마다 순차적으로 업데이트하는 것이라고 생각하시면 될 듯합니다. 모든 단어를 다 읽고 나면 encoder RNN의 최종 hidden state가 남습니다. 이는 word embedding처럼 Nx1 vector로 표현됩니다. 이 vector에는 번역해야 할 문장에 대한 모든 정보가 들어있기에, 문장 임베딩(sentence embedding)이라고 표현하기도 합니다.
이제 다 읽었으니 번역된 문장을 써야겠죠?
Decoder RNN: 한 단어씩 출력하기
Week 19에서 언어 모델을 이용해 문장을 생성하는 방법을 읽어보셨다면 이 부분은 이미 다 아는 부분입니다. RNN은 다음 단어를 예측하는 확률을 예측하고 단어를 하나씩 생성할 수 있는 능력이 있습니다. 여기서 모든 단어(vocabulary)에 대한 확률을 생성하는 함수는 softmax function이라고 배웠지요.
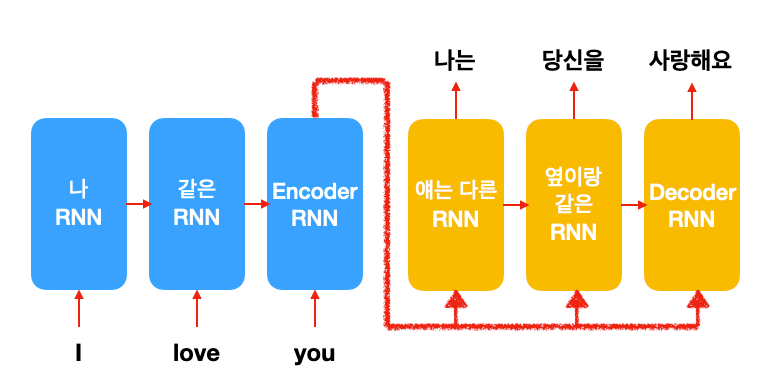
seq2seq 모델은 전에 배운 RNN LM과 거의 같습니다, 단 두 가지 빼고!
1) input sentence embedding도 같이 input으로 넣는다
이는 seq2seq는 conditional language model이라는 개념 (지난 주 포스트에서 복습!)을 실제로 구현한 부분입니다. 인간이 번역 문장을 쓸 때 기존 문장을 여러 번 다시 읽어보는 것과 같은 원리입니다.
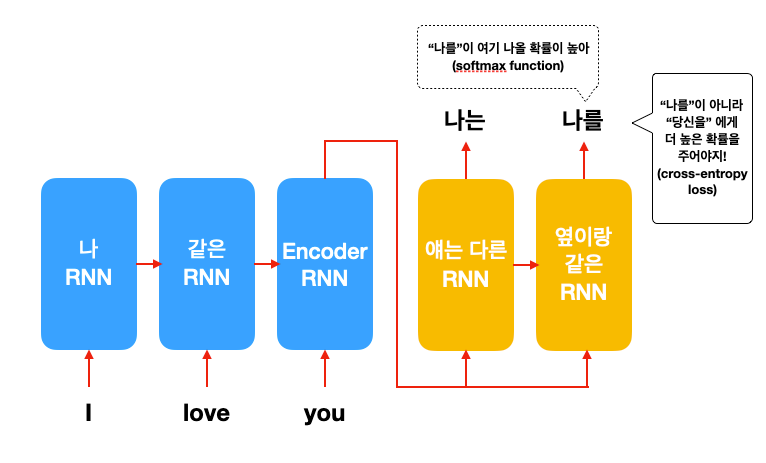
2) 랜덤으로 샘플링을 하지 않고 확률이 높은 단어를 고른다.
최종적으로 올바른 번역을 하려면 생각나는 단어 중에 제일 그럴듯한 거부터 적어 내야겠죠? 그렇기 때문에 seq2seq 모델은 가능한 모든 단어 중에 가장 높은 확률 점수를 받은 단어를 고릅니다!
정답을 보고 틀린 부분 학습하기
그렇다면 seq2seq 모델은 어떻게 학습을 할까요? 이는 우리가 RNN LM 편에서 배운 학습 방법과 같습니다. 바로 softmax layer가 생성하는 확률 점수와 현재 생성되어야 되는 단어 (정답)를 가지고 cross-entropy loss를 계산합니다.
두 번째 단어에서 "당신을"이 정답이라면, 올바른 모델이라면 "당신을"에 대해서 높은 확률을, 나머지 단어들에게는 낮은 확률을 주어야겠죠? 이걸 수학적으로 loss로 계산하여 모델을 개선시켜나갑니다 (Week 11: 모델이 데이터를 공부하는 방법).
"근데 이렇게 하면 decoder RNN만 개선되는 거 아닌가요?",
"그리고 앞 단어는 맞았는데 뒤에 나오는 단어를 틀리는 상황은 어떻게 학습되는 건가요?"
이러한 질문이 떠오르셨다면 굉장히 훌륭하게 모델을 이해하고 계시는 겁니다. 이는 바로 RNN의 학습 방법 중에 Back-Propagation Through Time (BPTT)라는 알고리즘을 사용해서 해결하는데요. 말 그대로 현재 틀렸지만 앞 단어나 encoder RNN 부분에서 잘못된 부분을 개선시키는 겁니다.
예를 들어, "I love you"에서 "나는 당신을 사랑해"를 번역할 시, 만약 뒤 부분인 "사랑해"를 쓰는 과정에서 오류를 범했다면, 실제로는 3번째 한국어 단어를 선택하는 과정에서 잘못한 것이 아니라 "I love you"를 이해하는 과정(encoder RNN) 또는 앞 단어를 잘 못 써서 ("너를" 말고 "나를"이라고 썼다거나) 오류가 범해진 것일 수도 있습니다. 이러한 오류도 잡기 위해 BPTT 같이 지금도 문제지만 과거에 무엇을 잘못했나 좀 더 반성하는 방법이 필요한 것이지요.
seq2seq 모델 학습을 좀 더 자세히 알아보려면 machinelearningmastery.com의 1) BPTT, 2) Teacher Forcing 블로그 포스트 또는 아래 reference에 있는 Deep Learning 책을 좀 더 참고하시길 바랍니다!
첫 단어를 잘 못 쓰면 어떡하지? 걱정이 많은 분들을 위해..
2) Random sampling을 하지 않고 제일 확률이 높은 한 단어를 고른다.
decoder RNN은 순차적으로 앞에서부터 한 단어씩 생성합니다. 그런데 만약 첫 번째 단어를 잘 못 고르면 어떻게 되는 걸까요?
그렇다면 뒤 단어를 아무리 잘 골라도 번역 자체가 틀리겠죠? 생산하는 확률 점수는 완벽하지 않기 때문에 충분히 가능한 시나리오입니다. 위와 같은 참사(?)를 막기 위해 Top-K Beam Search라는 방법이 도입됩니다. 가장 높은 단어를 한 개만 고르는 게 아니라 2,3 등도 고려하는 것입니다. 그리고 두 번째 단어를 생성할 때 1, 2, 3등 단어를 모두 첫 단어로 고려해서 넣습니다.
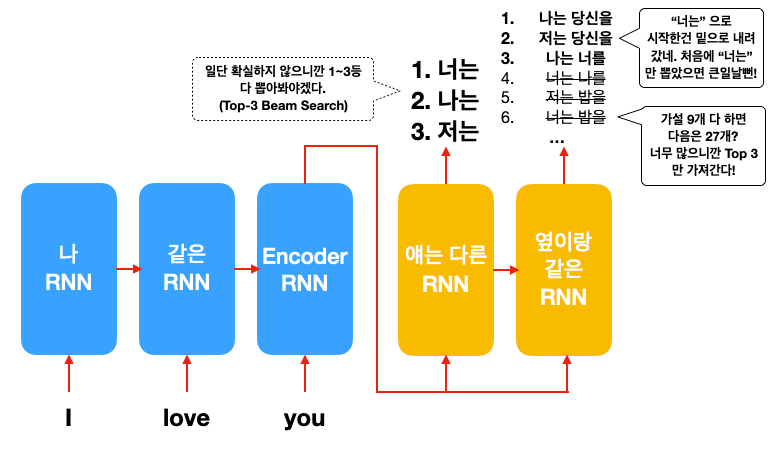
근데 문제는 가설의 개수는 기하급수적으로 늘어나기 때문에, 문장이 길어질수록 계산해야 할게 많습니다. 그렇기 때문에 우리는 모든 가설을 다 고려하지 않고, 제일 그럴 듯 한 3 개만 남겨둡니다. 그렇게 마지막까지 3 개의 가설이 남을 것이고, 그중에서 가장 그럴듯한 한 개를 최종 번역 문장으로 결정합니다. (여기서 3은 임의의 숫자입니다. K는 직접 골라야 하는 hyper-parameter입니다. 너무 크면 계산해야 할게 많겠죠?)
번역 퀄리티 계산하기
최종으로 생산된 번역의 퀄리티는 어떻게 측정할까요? 그때그때 사람이 보고 판단하면 아주 좋겠지만, 그건 너무나 비싸기 때문에 자동으로 모델의 퀄리티를 계산하는 방법이 필요합니다. 현재 연구 커뮤니티에서 쓰이고 있는 숫자는 BLEU score 인데요. 얼마나 정답과 단어가 공통 단어가 많으냐에 따라 점수가 결정됩니다. 직관적으로 이게 번역 퀄리티와 무슨 상관이냐며 논쟁의 여지는 있지만 아직까지는 큰 대안이 없어 계속 사용되는 것 같습니다. 그래서 어떤 연구들은 결과물의 일부분을 사람 번역가에게 퀄리티 측정 (human evaluation)을 하게 한 후 점수를 발표하기도 합니다.
오늘은 조금은 technical 한 부분이 많아 어렵지 않았을까 싶은데요. 조금은 수박 겉핥기처럼 지나간 거 같은 느낌이 없지 않습니다. 그렇기 때문에 좀 더 자세히 각 부분의 내용을 알고 싶은 분들은 꼭 아래 reference들을 참고해서 읽어보시는 것을 추천드립니다.
Reference
- Kyunghyun Cho, Chapter 6: Neural Machine Translation, Natural Language Understanding with Distributed Representation
- Deep Learning, Chapter 10: Sequence Modeling: Recurrent and Recursive Nets, Ian Goodfellow, Yoshua Bengio and Aaron Courville, http://www.deeplearningbook.org/contents/optimization.html




