Week 27 - 전에 배운걸 잘 써먹어야 산다 Transfer Learning


운동 신경이 좋은 친구들은 새로운 스포츠를 배워도 몇 번만 해보면 금방 어느 정도 잘하고는 합니다. 평소에 책을 많이 읽던 친구들은 따로 준비하지 않아도 독해 시험에서 좋은 점수를 받습니다. 음감이 좋은 친구들은 곡을 한번 듣고도 바로 비슷하거나 더 듣기 좋은 연주를 해냅니다. 벌써 2개의 외국어를 할 줄 아는 친구는 또 다른 언어를 배운다 하더니 얼마 만에 그 나라에서 자유롭게 회화를 합니다.
이런 얄밉지만 재능 있는 친구들 주변에 한 명씩은 있죠? 근데 잘 생각해보면 특출 나지 않더라도 누구나 원래 알던 지식이나 경험으로 새로운 일을 해냅니다. 인간은 적응의 동물이라 새로운 일이 주어졌을 때 빠르게 전에 있던 신경을 재활용합니다. 그렇기 때문에 우린 하루하루가 다른 매일을 살아갈 수 있는 것이겠죠? 근데 머신러닝 모델 역시 그럴 수 있다는 것! 바로 오늘의 주제 Transfer Learning(전이 학습; TL)에 대해서 이야기해보겠습니다.

이걸 잘하면 저것도 잘하지 않을까?
동물을 좋아하는 A가 있고, 식물을 좋아하는 B가 있습니다. A의 일은 사진을 보고 200 종류의 동물 중 하나로 분류하는 것입니다. B는 식물 사진을 보고 분류하는 일이죠. 어느 날 매니저가 와서 A와 B에게 이제는 강아지 사진만 줄 거고, 강아지 종류를 분류하는 게 일이라고 이야기합니다. 확률적으로 A와 B 중 누가 더 이 일을 잘할 수 있을까요?
이처럼 TL의 첫 번째 핵심은 각 문제 간의 유사성입니다. 만약 전혀 상관이 없던 일을 하던 사람에게 새로운 일을 하라고 하면 처음부터 다시 배워야 하고, 비슷한 일을 하던 사람은 금방 따라잡을 수 있겠죠.
TL이 가장 흥하기 시작한 분야는 이미지 처리(Computer Vision)입니다. 이미지 넷(ImageNet) 같이 엄청나게 많은 종류의 물체의 사진이 있는 데이터를 가지고 딥러닝 모델인 Convolutional Neural Network(CNN)을 학습시킵니다. 여기서의 문제는 주어진 이미지의 종류를 분류하는 일이죠. 업계에서는 더 많은 데이터, 더 큰 모델로 매우 좋은 성능의 이미지 분류 모델을 완성합니다.
그런데 말입니다, 연구자들은 이 막대하게 큰 딥러닝 모델들이 사물 인식에 필요한 기초 개념들을 스스로 파악하고 내부 파라미터(parameter)들에 어떤 형식으로 저장하고 있다는 것을 파악합니다. 딥러닝은 다양한 층의 파라미터로 구성이 되는데 어떤 층은 선과 꼭짓점에 대한 파악을 하고, 어떤 층은 색과 패턴에 대해서 배운다고 합니다. 이런 식으로 딥러닝 모델이 스스로 최종 문제(ex. 사물 종류 분류)를 위해 중간 단계의 개념들을 구조화하는 것을 representation learning이라고 합니다.

그리고 이렇게 학습된 파라미터들이 다른 이미지 처리 문제들에 매우 유용하다는 사실을 알아냅니다. 예를 들어, MRI 같은 의료 이미지 사진을 분석할 때 아무것도 학습되지 않은 모델로 시작하는 것이 아니라, 강아지, 차, 사람 등을 구별하는 문제로 학습을 해놓은 모델을 가져다 오면 더 효과적인 결과를 만들 수 있습니다. 이는 사물 인식 모델이 이미지의 선이나 면 같은 것에 대한 개념을 이미 모델 속에 학습하여 구조화해놓았기에 비슷한 문제인 의료 이미지를 볼 때 역시 큰 도움이 되기 때문입니다.
데이터가 적을 때는 무조건 TL!
어렸을 때부터 영어 책을 많이 읽고 자란 C가 있습니다. 그리고 영어 공부는 거의 해본 적이 없지만 토익 점수를 받기 위해 준비를 시작한 D가 있습니다. 같은 점수를 받기 위해 C와 D 중 누가 TOEIC 문제집을 더 많이 풀어야 할까요?
아마도 C는 기출문제 한두 권만 풀어도 금방 시험의 유형에 대한 감을 잡고 좋은 점수를 얻을 수 있을 것입니다. 하지만 D는 영어 공부를 거의 해본 적이 없기 때문에 엄청나게 많은 토익 문제를 보아야만 좋은 점수를 받을 수 있겠죠. 게다가 만약 전형이 바뀌어서 토익이 아니라 토플이나 텝스를 봐야 한다면, D보다는 C가 더 적은 노력으로 다른 시험을 대비할 수 있을 겁니다. D는 또 처음부터 새로운 시험의 문제집을 엄청나게 많이 보아야겠죠.
TL의 두 번째 핵심은 데이터 효율성입니다. 만약 머신러닝 엔지니어가 되었을 때, 매니저가 이러이러한 기능을 가진 모델을 만들어달라고 한다면, 먼저 물어볼 것은 데이터의 개수입니다. "한 몇 백 개 정도로 시작해볼 수 있겠죠?"라고 한다면, 일단은 당황하지 말고 (매니저한테 일단 무조건 가능하다고 하지 말고 - 중요!) TL을 고민해보아야 합니다. 만약 이미지 데이터라면 ImageNet 같은 많은 데이터로 학습된 큰 CNN 모델을 찾아볼 수 있겠네요.
이처럼 많고 유사한 데이터로 미리 학습된 모델을 Pretrained Model이라고 합니다. Pretrained Model을 잘 선택해서 활용하면 더 적은 데이터로도 같거나 뛰어난 성능을 이루어낼 수 있습니다. 그렇기 때문에 최근 머신러닝 모델들은 백지부터 시작하는 경우가 거의 없습니다. 그 분야에서의 pretrained model이 무엇이 있는지 잘 파악하고, 거기서부터 시작해야 합니다. 특히 요즘은 지난주 소개한 BERT와 같이 구글이나 페이스북 같은 대기업에서 엄청나게 많은 데이터와 컴퓨팅 파워로 학습된 모델을 공개하기 때문에 어떠한 것들을 사용할 수 있는지 파악하는 것이 매우 중요합니다.
NLP에서의 TL은?
그렇다면 NLP에서 활용할 수 있는 Pretrained Model은 무엇이 있을까요? 다행히 우리가 지금까지 차곡차곡 배운 개념들입니다. 대표적인 두 가지가 Word Embedding 그리고 Language Model입니다.
1) Word Embedding
각 주변 단어들을 이용해서 한 단어의 문법적, 의미적 정보를 하나의 Vector에 담아내는 Word Embedding에 대해서 Week 4에서 다루었습니다. 그리고 Week 9에서 글을 그림처럼 보는 CNN 모델을 다룰 때, GloVe나 Word2Vec 같은 Pretrained Word Embedding을 활용하면 마치 국어/영어 사전을 들고 시작하는 것과 같은 것이라고 했었죠. NLP에서 가장 기초적인 TL 방법이 바로 이 word embedding을 활용하는 것입니다.
2) Language Model
그다음이 바로 Language Model을 활용하는 것입니다. 기존에 배운 N-gram LM이나 RNN LM 같은 경우에는 어떻게 TL을 할 수 있는지 명확하지 않았는데, ELMO와 BERT 같은 모델들이 나오면서 이야기가 달라집니다. 이 모델들은 Sentence Embedding을 계산할 수 있기 때문입니다. 단어 한 개를 1개의 vector로 표현한 것이 word embedding인 거처럼, 문장 전체를 1개의 vector로 표현하면 sentence embedding입니다. LM이 많은 데이터를 보면서 학습한 모델이 새로운 문장을 보았을 때, 그 이해를 압축시켜서 하나의 vector에 담아내는 것이라고 일단은 이해하시면 될 것 같습니다.
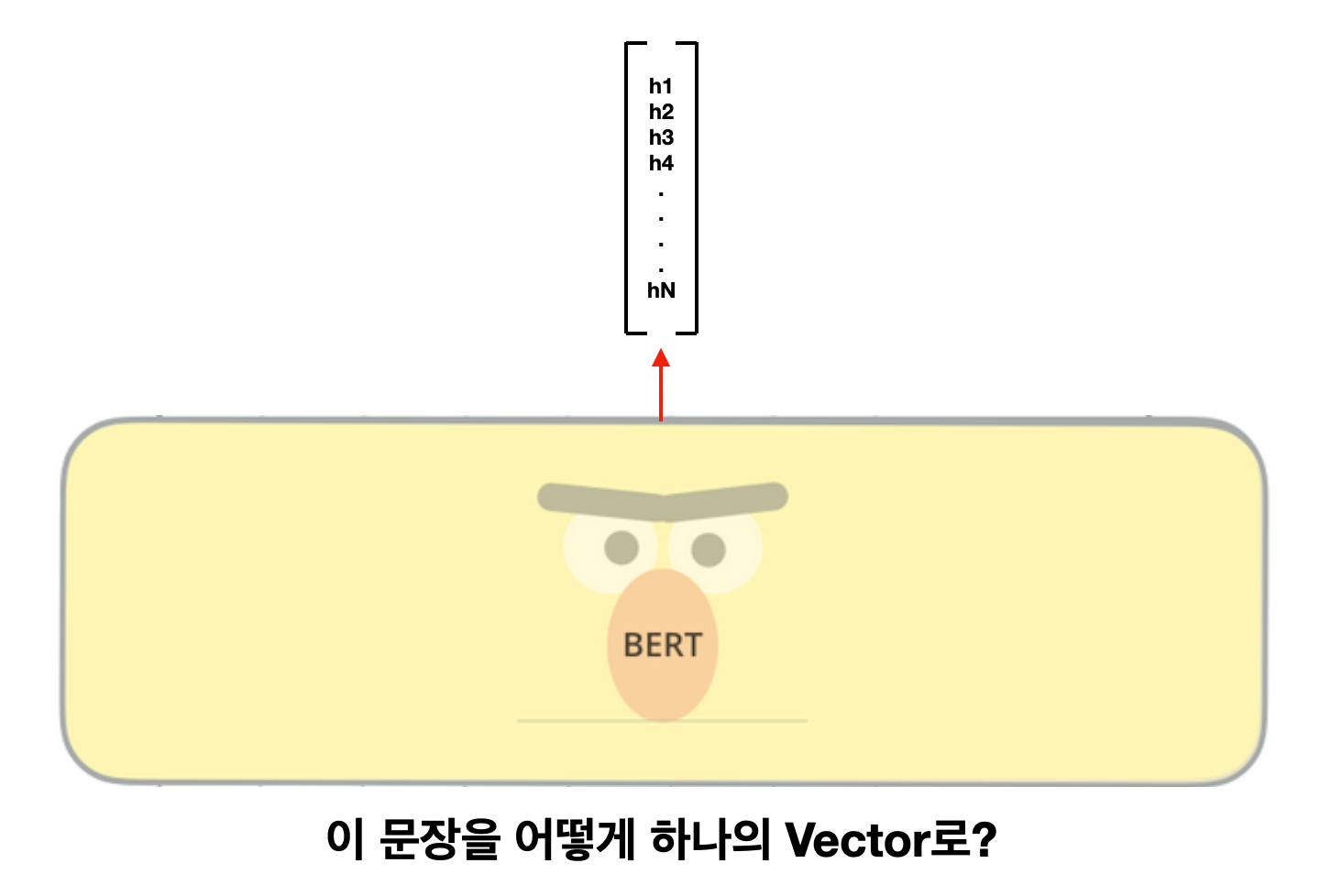
오늘은 조금 어려운 내용을 들고 와서 설명해보았습니다. 이해가 안 되는 부분이 있다면 꼭 댓글로 남겨주세요. 다음 주에는 좀 더 구체적으로 BERT를 가지고 어떻게 Transfer Learning에 쓸 수 있는지, 왜 사람들이 그렇게 BERT에 열광하는지 알아보도록 하겠습니다.

Reference
- Arden Dertat, Applied Deep Learning - Part 4: Convolutional Neural Networks
- Tajbakhsh et al., 2017, Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning?, IEEE Transactions on Medical Imaging



