Week 29 - 드디어 인간을 끝장낼 AI가 나왔다? GPT!


아래 답변은 사람이 아니라 AI 모델이 자동으로 생성한 글입니다. (영어에서 한국어로 번역)
Q : 40 대 초반에 노안이있었습니다. 어떻게해야합니까?
A : 예전에는 신문을 읽는 것과 같이 좀 더 가까운 작업을 위해 돋보기를 가지고 있었을 것입니다.
Q : 40 대 초반이라 사람들이 돋보기를 사용하는 것이 이상하다고 생각할 것 같아요. 다른 대안이 있습니까?
A : 노력할 수 있다면 안과 의사를 만나 노안을 치료할 수 있는지 확인해야합니다.
Q : 안과 의사는 노안을 치료하기 위해 어떤 방법을 사용해야합니까?
A : Monovision 렌즈 임플란트 또는 LASE (small incision lenticule extract)와 같은 새로운 기술의 혜택을받을 수 있으며 수술이 필요하지 않습니다.
Q : 그러한 절차는 비싸지 않습니까?
A : 그것이 얼마나 많은 돈이 있는지에 관한 것입니다. 그렇게 노력할 수 없다면 독서 용 안경이나 이중 초점을 고려하는 것이 좋습니다.
출처: https://github.com/nakosung/ai-dungeon-cli
미국 프로그래머들의 커뮤니티인 해커 뉴스에 Feeling unproductive? Maybe you should stop overthinking이라는 글이 많은 추천 수를 받아 상위에 올라왔습니다. 그리고 며칠 후에 저자가 사실 이 글은 사람이 쓴 것이 아니라 GPT3로 생성한 글이라고 알려 많은 이들을 놀라게 했습니다.
2020년 5월, GPT3라는 모델이 세상에 공개되었습니다. 언론에서는 드디어 인공지능이 인간의 일자리를 다 대체할 것이라고 떠듭니다.
GPT가 어떤 원리를 가지고 작동하는 것인지 궁금하시죠? 사실 <위클리 NLP>를 열심히 읽고 공부하신 독자 분들이라면 이미 GPT를 이해하기 위한 퍼즐을 모두 갖추고 있습니다. 이번 글은 함께 이 조각들을 맞추어 보겠습니다.

GPT는 또 하나의 언어 모델(Language Model)이다
지난 몇 달간 계속 Language Model(LM)에 대해서 이야기해왔습니다. LM의 가장 기본 개념이 무엇이었는지 기억나시나요?

바로 여태까지 나온 단어들을 토대로 다음 단어를 예측하는 것입니다. 이는 수많은 텍스트 데이터를 통해 통계학적인 모델을 학습시키는 방식으로 이루어졌다고 배웠습니다. 아주 간단한 n-gram LM, 그리고 딥러닝을 이용한 RNN LM도 다루어보았는데, GPT의 본질은 이 모델들과 똑같습니다. 다음 단어 예측하기!
잘 학습된 LM은 그럴듯한 글을 생성할 수 있다
다음 단어를 예측할 수 있다는 것은 다음 단어를 생성할 수도 있다는 것을 의미합니다. 이미 우리는 RNN LM이 만든 트럼프 봇의 예시를 살펴보며 함께 배웠습니다. 예측된 단어를 받아 적고, 다음 단어를 또 예측해 받아 적고 하는 식으로 글을 생성할 수 있습니다. 아래 예시처럼요.
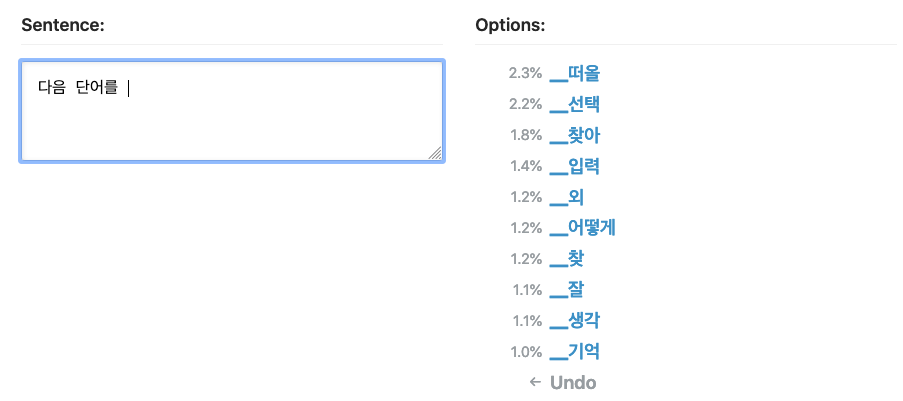
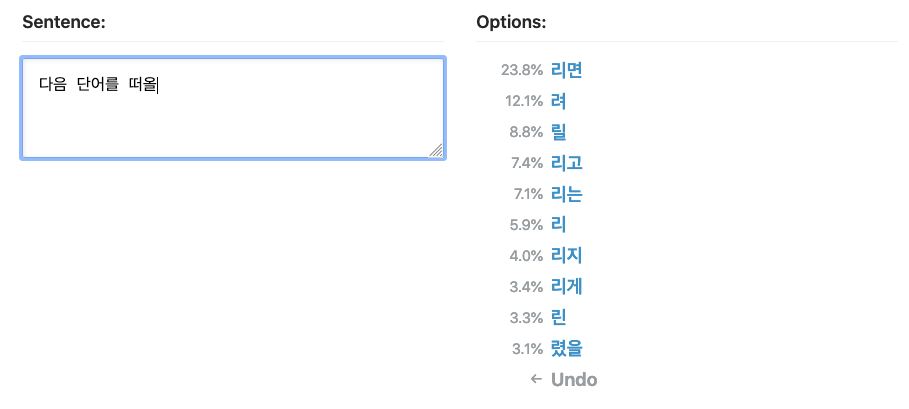
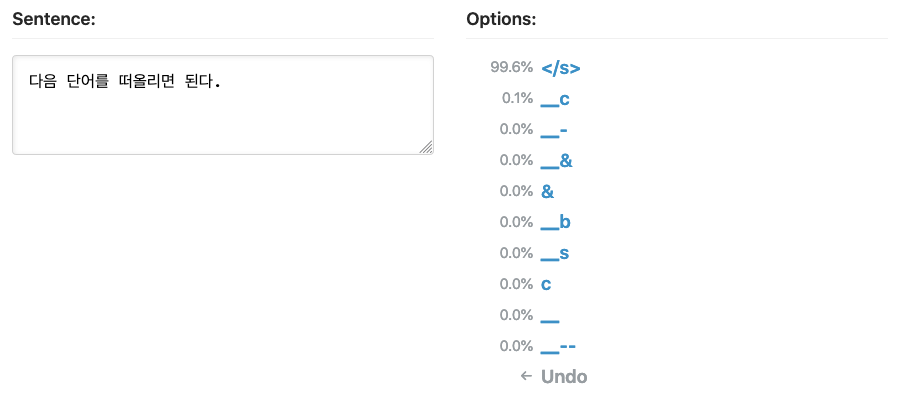
"다음 단어를"이라는 운만 띄워주면 한 단어씩 생성해서 결국 "다음 단어를 떠올리면 된다"라는 문장이 완성됩니다. 계속 더 가면 문단이 되는 것이고, 더 가면 글이 됩니다.
GPT는 무엇의 약자지?
이쯤 되면 궁금해야죠? (한 번도 생각하지 않았다면 반성(?)을...)

1) Generative
GPT는 생성 모델인데, 이는 데이터 전체의 분포를 모델링하는 머신 러닝 기법을 뜻합니다. 단순히 새로운 글을 생성할 수 있다는 것은 생성 모델의 여러 특성 중 하나입니다. (조금은 어려운 머신러닝 콘셉트이라 다른 분의 블로그 포스트로 설명을 대체합니다)
2) Pretrained
GPT가 다른 모델보다 월등하게 좋은 성능을 보이는 가장 큰 이유는 어마어마한 학습 데이터의 양입니다. GPT3 모델은 무려 5000억 개의 단어(token)를 포함한 데이터 셋을 보고 학습되었습니다. 대부분의 데이터는 인터넷에서 크롤링한 Common Crawl입니다. 인터넷 데이터는 정말 방대하지만 질이 낮기 때문에 그중 더 높은 퀄리티의 데이터만 확보하기 위해 필터링 작업을 거쳤다고 합니다. 그리고 더 질 좋은 텍스트가 있는 책과 위키피디아 데이터도 추가하였습니다. 처음에 확보한 데이터의 용량만 45TB였고, 필터링 이후의 데이터는 570GB라고 합니다. 메모장에서 txt 파일을 저장해 보신 분들은 이게 정말 얼마나 많은 텍스트인지 감이 오실 겁니다.
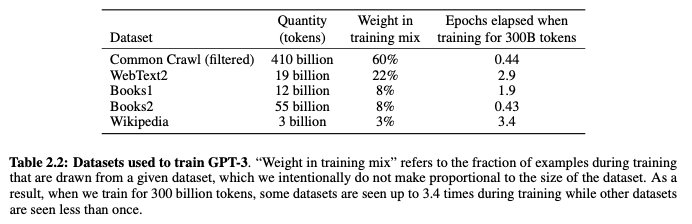
많은 데이터로 미리 학습시켜놓은 모델을 Pretrained Model이라고 전이 학습(Transfer Learning)을 공부할 때 배웠습니다. GPT3 역시 이렇게 엄청나게 많은 데이터로 학습되어 다른 NLP 문제들을 푸는 쓰일 수 있다는 의미로 Pretrained라는 단어를 이름에 지니고 있습니다.
**참고로 보통 Pretrained 모델을 학습시킬 때는 학습 데이터를 여러 번 보면서 학습되는데, GPT 같은 경우 너무 많아 모델이 대부분 한 번만 본다고 합니다. 안 그러면 학습에 너무 오래 걸리기 때문이죠.
3) Transformer
트랜스포머는 우리가 기계 번역(MT)의 발전을 배우면서 공부한 모델입니다. RNN에 관심 기법(Attention mechanism)을 쓰다가, RNN을 빼고 Attention만 남긴 모델이 트랜스포머였죠. 지난주까지 배운 BERT 역시 T가 Transformer였습니다. BERT와 GPT의 가장 큰 차이점은 기계 번역에 쓰인 트랜스포머의 다른 부분을 사용한다는 점입니다.
기계 번역 모델이 기본적으로 Encoder-Decoder로 구성된다는 점 Seq2Seq 모델을 공부하면서 배웠습니다. 한국어에서 영어로 번역을 한다면 한국어는 Encoder로 들어가고, 영어는 Decoder로 나옵니다.
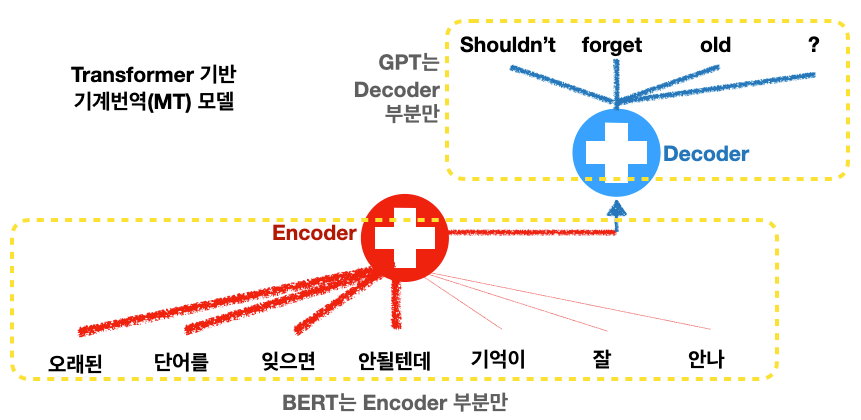
전체 문장을 다 보고 중간에 들어가는 단어를 예측하는 BERT와는 다르게, GPT는 기존의 언어 모델과 같이 다음 단어를 예측해야 하기 때문에 Transformer Decoder를 사용합니다. 왜냐하면 Encoder는 문장 전체를 보지만 Decoder는 예측해야 하는 단어와 그 이후를 못 보게 설계되었기 때문입니다 (masked self-attention). 미래(다음 단어)를 예측해야 하는 문제인데, 미래를 미리 보여준다면 모델이 배울 수가 없겠죠? 연습 문제를 답안지를 보면서 푸는 것과 같습니다.
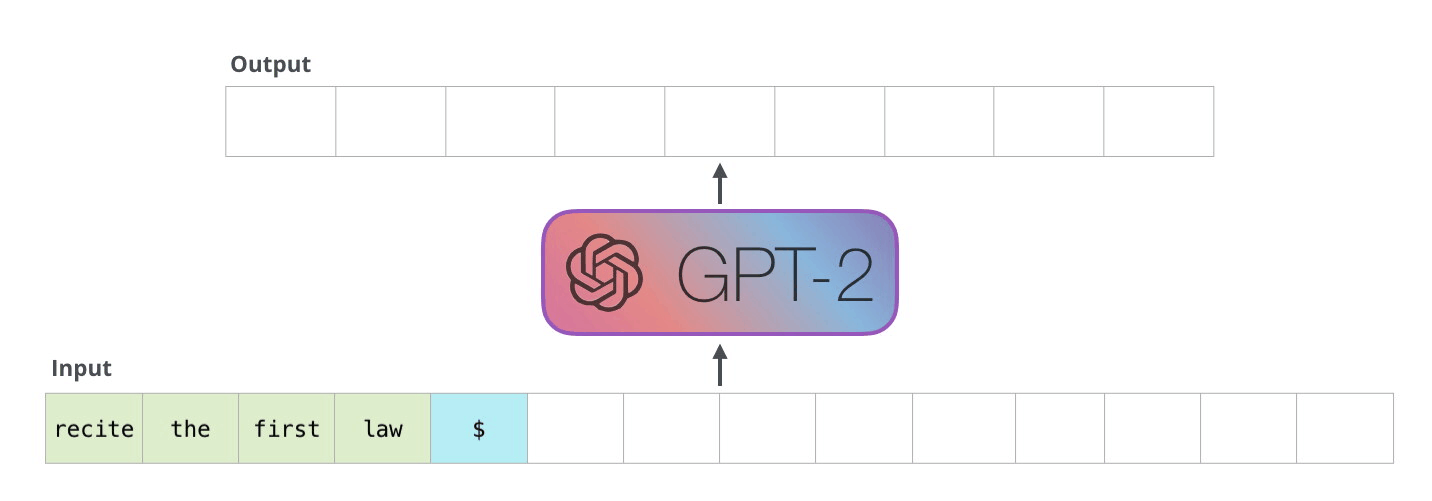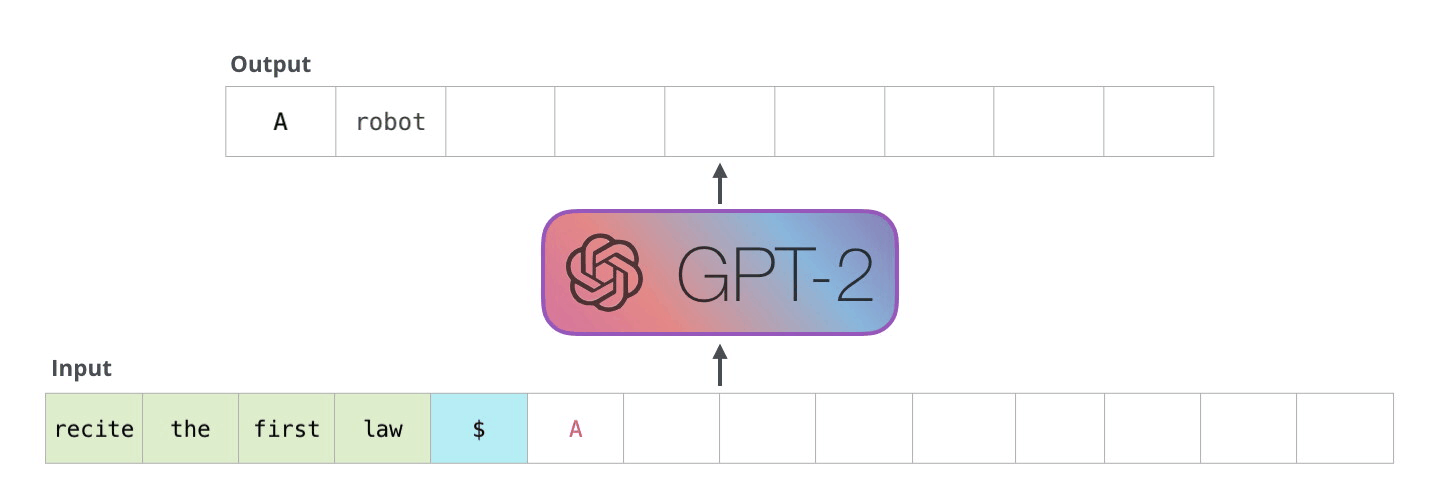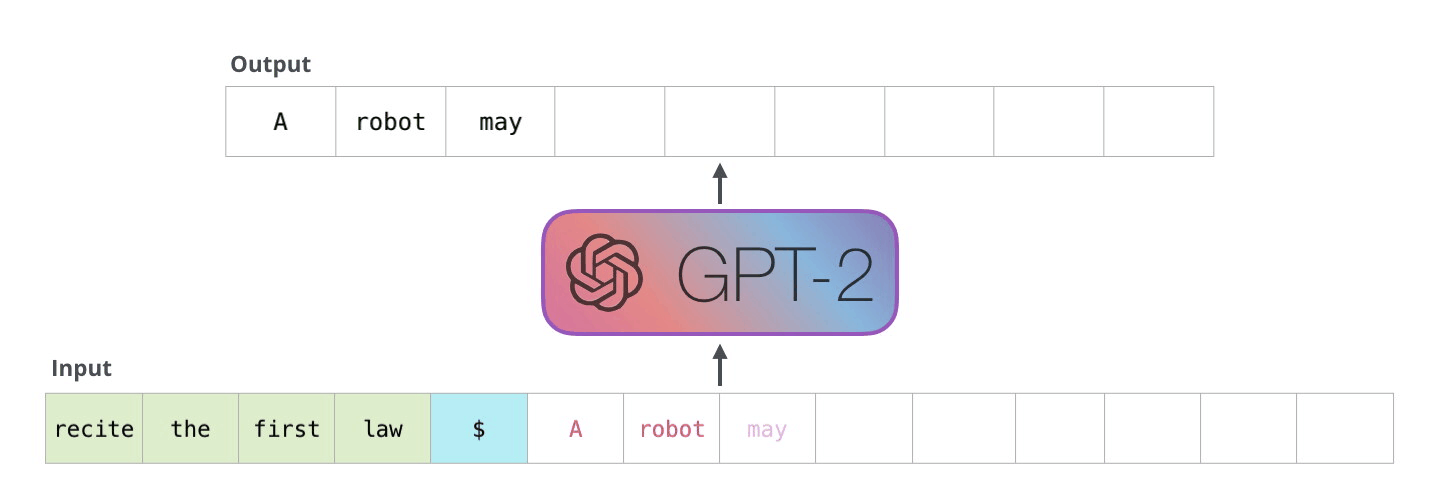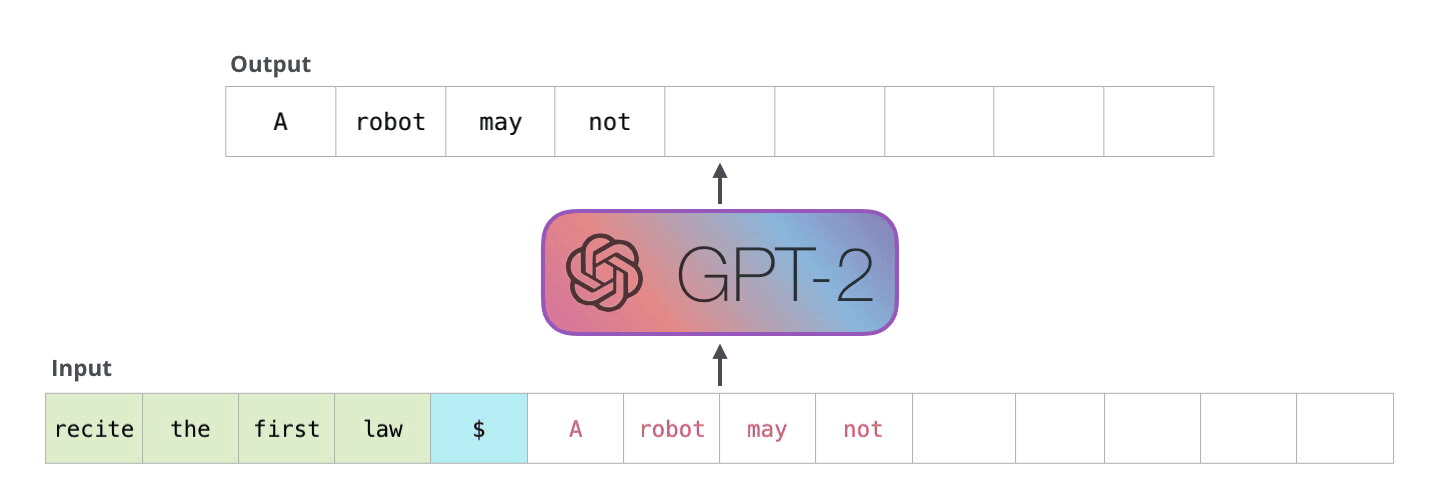
GPT1, 2, 3의 차이는 뭐지?
2018년, OpenAI는 첫번째 GPT를 Improving Language Understanding with Unsupervised Learning라는 논문으로 공개하였습니다.
2019년 두번째 모델이 공개되었습니다: Language Models are Unsupervised Multitask Learners. 당시에 OpenAI는 너무 성능이 좋아 위험한(?) 모델이라 오픈소스로 모델 자체를 공개하지 않겠다는 선언을 하였습니다. 스팸, 가짜 뉴스 등에 악용될 수 있기 때문이라고. (개인적으로는 BERT 네이밍과 함께 NLP 학계 최고의 마케팅 수법으로 꼽습니다)
그리고 2020년 세번째 모델이, Language Models are Few-Shot Learners라는 논문으로 공개되었습니다. OpenAI는 공개하기 너무 위험하다던 GPT2보다 훨씬 더 성능을 보인 GPT3를 놀랍게도 유료 API로 제공될 것이라는 계획을 발표했습니다. (아마 OpenAI라는 조직이 비영리 단체에서 영리를 추구하는 회사로 변경된 것이 우연은 아니겠찌요)
그렇다면 세 버젼에는 무슨 큰 차이가 있을까요?
답은 사이즈입니다. 기본적인 모델 구조나 학습 원리는 모두 같으나, 트랜스포머의 사이즈가 무려 GPT3는 175 Billion (1750억)이라고 합니다. GPT2와 비교하면 무려 100배가 큰 사이즈지요.
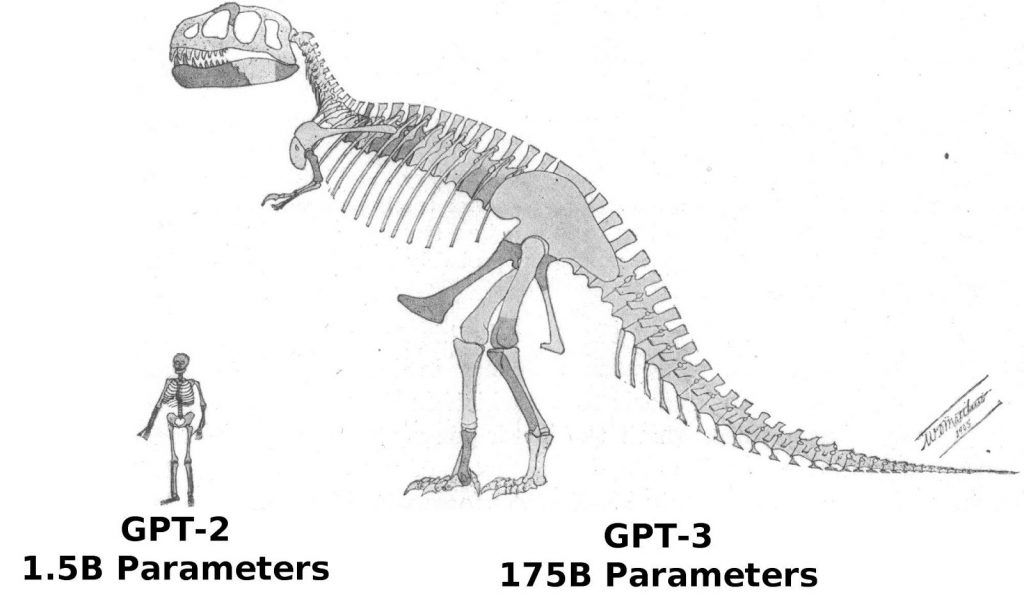
그리고 앞에 말한 것처럼 학습 데이터 역시 막대하게 커졌고요. 이처럼 스케일이 높이는 것이 엄청난 성능을 가져오긴 하나, 한 개의 모델을 학습시키는데 120억 원이라는 돈이 든다니 결국 쩐의 전쟁인가 싶기도 합니다.
오늘은 GPT의 원리에 대해서 배워보았습니다. 규모가 엄청난 언어 모델이라는 건 알겠습니다만, 왜 근데 사람들이 이렇게 난리를 치는걸까요? 이걸 가지고 뭘할 수 있는 것일까요? 다음 시간에 더 이어서 얘기해보겠습니다.
Reference
Improving Language Understanding with Unsupervised Learning (a.k.a. GPT)
Language Models are Unsupervised Multitask Learners (a.k.a. GPT2)
Language Models are Few-Shot Learners (a.k.a. GPT3)




