Week 4 - <왕> minus <남자> plus <여자>= ?
<왕> - <남자> + <여자> = ?<마드리드> - <스페인> + <프랑스> = ? 다음 두 문제의 답은 무엇일까요? 이번 주에는 단어 간의 관계를 학습해 vector에 저장하는 word embedding이라는 아주 중요한 모델을 소개하려고 합니다

<왕> - <남자> + <여자> = ?
<마드리드> - <스페인> + <프랑스> = ?
다음 두 문제의 답은 무엇일까요?
"엥, 단어가 무슨 숫자? 어떻게 더하고 빼니?", "이거 무슨 IQ 테스트에 나오는 문제인가요?" 싶으신 분들이 많으실 겁니다. 하지만 우리의 언어 상식을 이용하면 충분히 답을 유추해낼 수 있지요. 우리는 각 단어 간의 관계를 여태까지 읽어온 수많은 글을 통해 이미 머리 속에 구축해왔으니깐요.
하지만 위클리 NLP의 Week 1을 읽으신 분들은 단어는 숫자로, 아니 Week 3에서 배웠다면 정확히 vector로 표현될 수 있다는 것을 알고 계시겠지요. 다만 우리가 배운 one-hot vector는 단어 간의 관계를 전혀 고려하지 않은 표현 방식이기 때문에 이 문제들을 풀기 적합하지 않다는 것!
이번 주에는 단어 간의 관계를 학습해 vector에 저장하는 word embedding이라는 아주 중요한 모델을 소개하려고 합니다

Distributional Hypothesis: 단어는 주변 단어들에 의해 정의된다
주변 사람들을 보면 그 사람이 어떤 사람인지 알 수 있다고 하죠? 단어도 마찬가지입니다. 예시를 한번 봅시다.
The baby is crawling on the mat.
만약에 baby 대신 TV라는 단어가 들어간다면 어떤가요? "The TV is crawling on the mat." 말이 안 되는 문장이 됩니다.mat (바닥 매트) 대신 story(이야기)가 들어간다거나, on 대신 with이 들어간다면 역시 문장이 어색해집니다.
baby, on, mat은 타겟 단어인 crawling에 대해 많은 것을 알려줍니다. crawling은 "기어가다"라는 뜻을 가진 동사입니다. 주어로는 baby, 전치사로는 on, 목적어로는 mat이 crawling과 잘 어울리는 단어들이고, 실제로 수많은 텍스트에 같이 등장할 것입니다.
이 정보는 문장을 읽기만 하면 알 수 있습니다. 그냥 crawling이 등장하는 수백, 수천, 아니 수만 개의 문장을 찾아서 보면 됩니다. machine learning에서는 이런 종류의 학습 방법을 unsupervised learning이라고 합니다. 따로 시간과 돈을 들여 데이터를 가공할 필요 없이 그냥 책이나 인터넷에 있는 텍스트 그대로만 가지고도 유용한 모델을 만들 수 있다는 것이죠.
그렇다면 Distributional Hypothesis를 가지고 어떻게 machine learning 모델로 만들 수 있을까요? Stanford에서 나온 GloVe와 2013년에 Google에서 나와 NIPS에 처음 소개된 word2vec은 각자 다른 방식으로 이를 구현합니다.
Word Embedding (word vector)란?
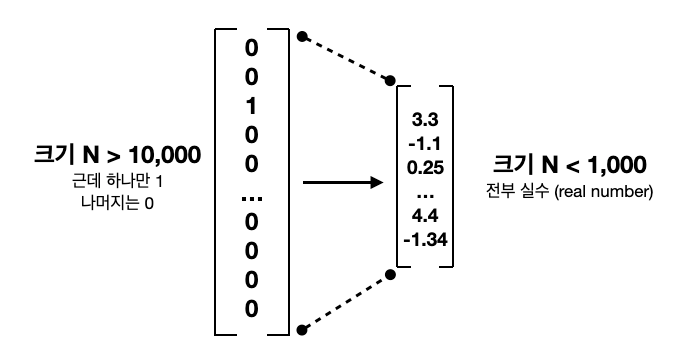
word2vec과 GloVe의 내용으로 들어가기 전에 word embedding이 무슨 의미인지 짚고 넘어갑시다. 지난주에 배운 one-hot vectors는 단어를 Nx1 column vector로 표현합니다. 다만 데이터가 클수록 단어의 개수가 몇천 또는 몇만으로 커질 수 있다고 했죠. 그리고 단어를 표기하는 1개의 row말고는 0으로 채워져 있기 때문에 아주 비효율적입니다.
word2vec과 GloVe은 둘 다 하나의 단어를 몇천 차원, 몇만 차원이 아닌 몇십, 몇백 차원으로 낮추려는 게 목표입니다. embed라는 "단단하게 박다"라는 뜻인데, 더 적은 숫자들로 하나의 단어에 대한 정보를 담으려는 word vector들을 embedding이라고도 표현합니다. "듬성듬성하다 (sparse)"의 반대말인 "빽빡하다 (dense)"라는 단어도 같이 많이 쓰입니다. word embedding의 모든 row는 0이 아닌 어떠한 숫자로 채워지기 때문입니다.
간단한 counting을 이용한 GloVe
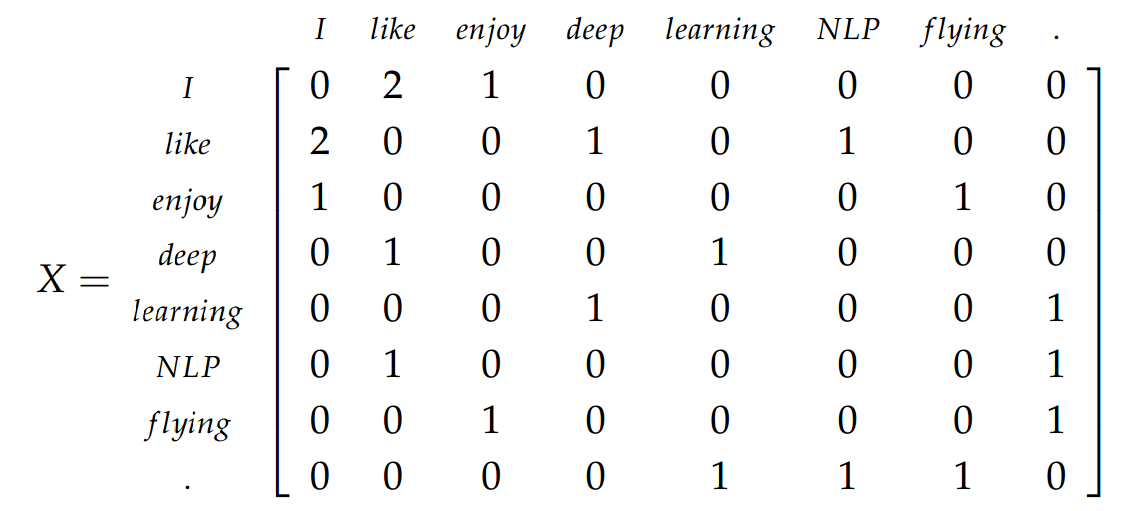
GloVe는 아주 직관적인 방식을 택합니다. 같은 문장에 한 단어가 어떤 근처 단어들과 몇 번 같이 나오는지 세보는 것입니다. 이것을 co-occurrence matrix라고 합니다. 이렇게 세 개의 문장을 가진 corpus를 가지고 생각해봅시다.
"I enjoy flying."
"I like NLP."
"I like deep learning."
**참고로 NLP에서는 가지고 있는 텍스트 데이터를 corpus라고 부릅니다. 앞으로도 자주 나올 용어이니 꼭 기억해주세요.
첫번째 행을 보면 "I"와 같이 두번 나오는 "like"가 있는 열은 2라는 숫자를 가집니다. 반대로 NLP나 flying이라는 단어는 같이 나오지만 근처가 아니거나, 아예 같이 나오지 않기에 0으로 표시됩니다.
전체 corpus에서 40,000개의 단어가 있다고 가정합시다. 40,000 x 40,000 매트릭스를 만들고 전부 0으로 초기화시킵니다. vocabulary를 보았을 때 crawling의 번호(index)가 200이고 , baby의 번호가 150이라면, 200행, 150열 그리고 150행, 200열을 숫자를 하나씩 증가(+1)시켜줍니다. 이런 식으로 전체 corpus를 계산하면, 200번째 열은 crawling이라는 단어와 vocabulary에 모든 다른 단어들과의 빈도수 통계가 나올 것입니다.
하지만 40,000 x 40,000 매트릭스는 너무나 큽니다. 같이 한 번도 나오지 않는 단어도 많을 것이기에 0이 꽤나 많은 sparse matrix이기도 하고요. 이러한 비효율을 어떻게 해결할 수 있을까요?
여기서 dimensionality reduction이라는 기술이 등장합니다. 이름 그대로 차원을 줄여주는 Dr. Strange 같은 느낌의 알고리즘인데 정확히 말하면 40,000 x 40,000를 300 x 40,000으로 압축시켜줍니다. 흩어져있는 밀가루 분자들을 단단한 반죽으로 만들어 버리는 겁니다.
GloVe는 Singular Value Decomposition (SVD)라는 알고리즘을 사용합니다. 선형 대수 (linear algebra)를 좋아하시는 분들이 있다면 꼭 공부를 해보시기를 권합니다. 자매품으로는 Principle Component Analysis (PCA)가 있습니다. 이러한 Dimensionality reduction 알고리즘들은 NLP 뿐만 아니라 추천 시스템 등 machine learning에서는 엄청나게 중요하고 유용하게 쓰이는 기술 중의 기술입니다!
그렇게 300 x 40,000 행열로 압축이 되면 각 열 (300x1)이 하나의 단어를 대표합니다. 앞에 소개 했듯이 각 단어가 dense한 vector로 압축되어, 예를 들어 crawling이라는 단어를 300개의 숫자로 표현할 수 있게 되는 것이죠!
neural network를 이용한 word2vec
word2vec은 continuous bag-of-words (CBOW) 또는 skipgram 알고리즘을 통해 학습시킬 수 있습니다. 기발하게도 저자는 주변 단어와 타깃 단어의 관계를 예측 문제 (classification)로 바꾸어 버립니다.
(1) CBOW - 주변 단어들을 모두 합쳐서 본 후 타깃 단어를 맞추기
(2) skipgram - 타깃 단어를 보고 주변 단어를 맞추기
아래 예시에서 fox가 target이라면, CBOW 같은 경우 ["the", "quick", "brown", "jumps", "over"]을 가지고 "fox"을 예측하려고 하고, skipgram에서는 "fox"을 가지고 "the", "quick", "brown", "jumps", "over"를 각각 예측하려고 하는 거죠. (CBOW가 좀 더 직관적이지만 실제로 skipgram으로 학습된 embedding이 실험 결과 상 더 효과가 좋습니다.)
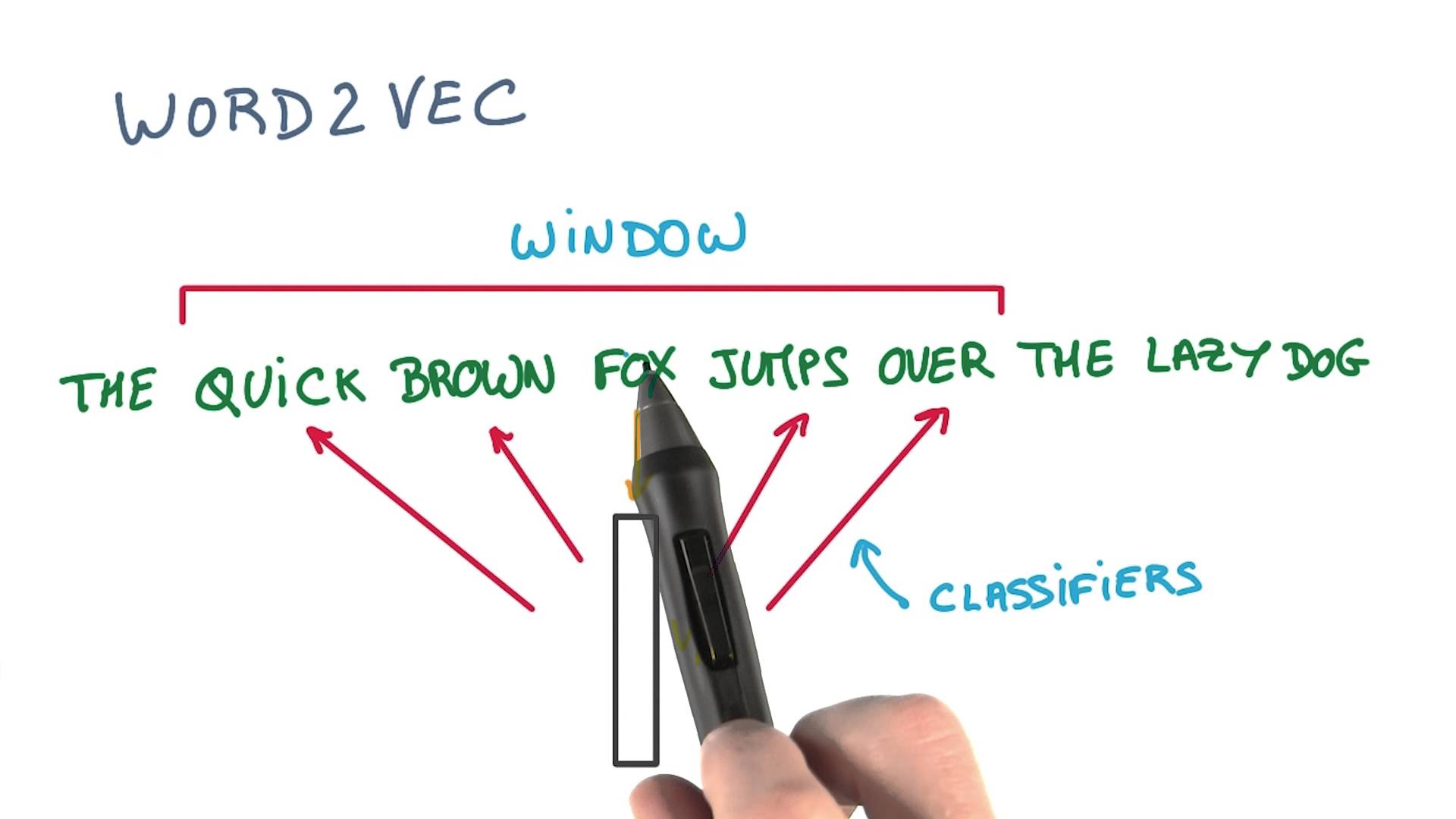
예측을 위한 classification model은 neural network로 구현이 되고, stochastic gradient descent (SGD)로 학습이 됩니다. input은 Nx1 word embedding으로 들어갑니다. 처음에는 무작위의 숫자로 embedding이 초기화되지만, 학습이 점점 될수록 word embedding은 주변 단어들과의 관계에 대한 정보가 encoding 됩니다.
아직은 technical detail을 전부 이해하는 것은 어렵겠지만, Glove와 궁극적으로 같은 word embedding을 다른 방식으로 학습 시키는 것이라고 이해하시면 됩니다! 더 깊게 들어가실 분은 reference의 원 논문을 참고해주세요!
<마드리드> - <스페인> + <프랑스> = <파리>!
word2vec 또는 glove로 학습된 word embedding들은 단어를 N차원에 사는 vector로 바꾸어준 것 입니다. 그렇기 때문에 서로 더하고 뺄 수 있게 되는 거죠? 더 놀라운 것은 이 더하기, 빼기를 통해 단어들의 의미적 관계 (semantics)과 문법적 관계 (syntactic)를 알아낼 수 있다는 것입니다.
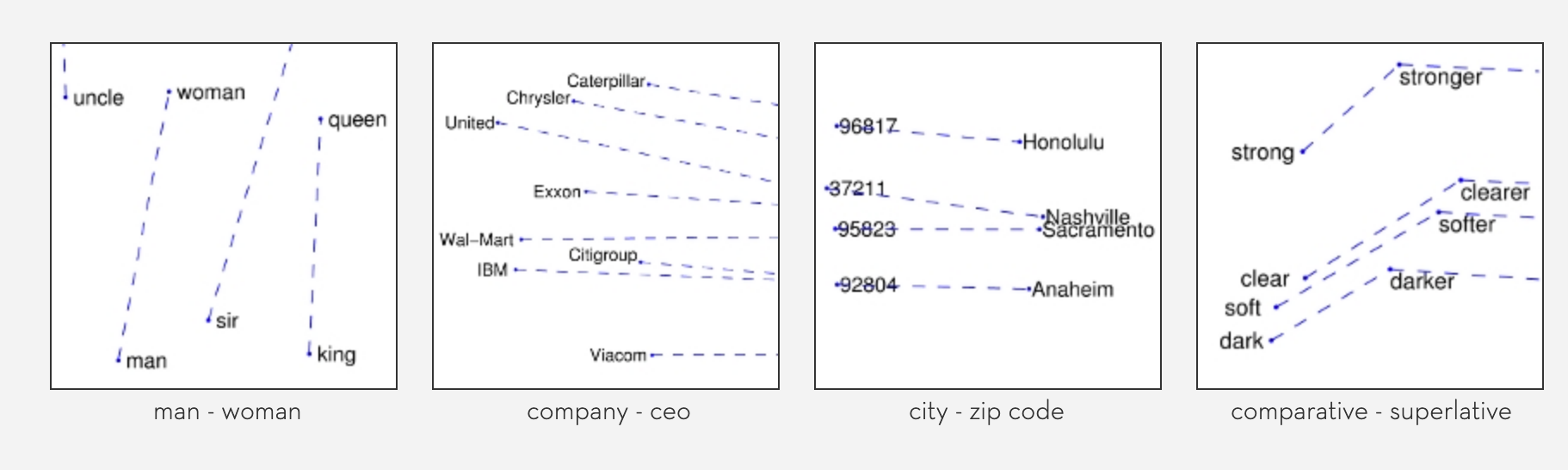
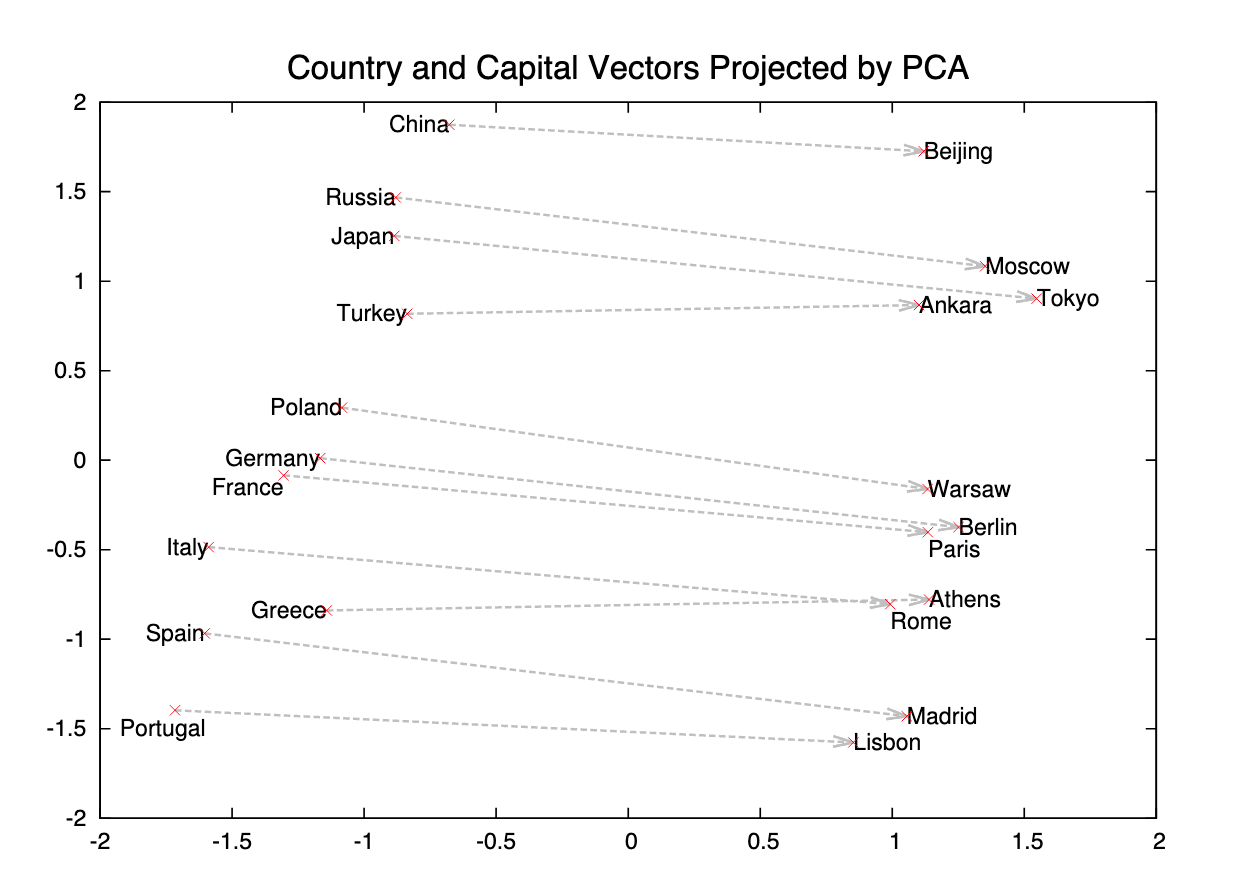
위 예시와 같이 단어의 성별 관계, 회사와 CEO 이름의 관계, 도시와 ZIP code의 관계, 그리고 형용사의 변형 (ex. dark, darker, darkest)까지 vector의 방향성에 encoding이 되어있다는 것을 알 수 있습니다.
또한 이러한 word embedding들을 다른 NLP task의 input으로 사용하였을 때, 엄청난 성능 증가를 기대할 수 있습니다. 왜냐하면 word embedding은 엄청난 양의 corpus로 학습되어 각 단어에 대한 정보를 꽤나 정확하고 깊게 담아낼 수 있거든요. 수능 국어를 잘 보려면 어렸을 때부터 독서량을 늘려야 된다는 전문가들의 조언과 일맥상통합니다.
이번주는 NLP의 혁명적인 변화를 가져온 word embedding에 대해 배워보았습니다. 혁명이란 단 한번 일어나서 끝나는 게 아닙니다. 처음 나왔을 때 파급력도 크겠지만, 그 이후에 우리의 일상 속에 점점 스며들여 나중에는 혁명의 어젠다가 마치 당연한 진리인 것처럼 되어야 진정으로 성공한 혁명이겠지요. 고작 6년 정도 된 word embedding이라는 연구는 2020년 현재 NLP의 진리가 되었습니다. 이를 바탕으로 더 크고 대단한 성과가 이어지고 있습니다.
앞으로도 word embedding를 바탕으로 나온 많은 연구에 대한 소개가 <위클리 NLP>에서 나올 예정이니 놓치지 않게 이메일 구독을 하시고, 모르는게 있다면 꼭 댓글이나 이메일로 공유해주시길 바랍니다!
다음 주에는 이어서, 이러한 vector 간의 유사성을 어떻게 계산하는지, 그걸 통해 어떻게 word embedding의 vector space를 더 자세히 살펴볼 수 있는지 배워보겠습니다.

Reference
- Mikolov et al., 2013, Distributed Representations of Words and Phrases and their compositionality, NIPS 2013
- Pennington et al., 2014, GloVe: Global Vectors for Word Representation



