Week 5 - 얘랑 나랑 얼마나 비슷해?
여러분은 어떤 사람과 얼마나 비슷한지 숫자로 표현할 수 있으신가요? "친구 A보다 B가 나와 좀 더 비슷한거 같아.." 라는 어찌어찌 할 수 있을거 같은데, 아무래도 절대적인 숫자를 생각해내기는 것은 조금 애매한거 같죠? 하지만 지난 2주 동안 배운 vector는 다릅니다! 명확하게 두 개의 vector 간의 거리를 계산하는 방법을 배워봅시다.


여러분은 어떤 사람과 얼마나 비슷한지 숫자로 표현할 수 있으신가요? "친구 A보다 B가 나와 좀 더 비슷한거 같아.." 라는 어찌어찌 할 수 있을거 같은데, 아무래도 절대적인 숫자를 생각해내기는 것은 조금 애매한거 같죠?
하지만 지난 2주 동안 배운 vector는 다릅니다! 명확하게 두 개의 vector 간의 거리를 계산하는 방법을 배워봅시다. 그리고 지난 주 배운 word embedding을 예시로 왜 거리가 중요한지 알아보겠습니다.

NLP에서 Vector의 역할은?
Week 2에서 소개한 Bag-of-Word (BoW) vector 또는 tf-idf vector는 문장을 단어의 빈도수를 계산하여 N차원의 column vector로 표현한 것을 배웠습니다. 여기서 N은 전체 단어 (vocabulary)의 숫자라 단어가 많을수록 커진다고 했죠.
Week 4에서 나온 word embedding은 각 단어들을 GloVe나 skipgram 같은 알고리즘으로 각 단어들을 비교적 작은 100차원, 300차원 등의 vector로 줄여서 만들 수 있었죠.
핵심은 문장, 문서, 그리고 단어를 숫자들로 이루어진 vector로 만들어 N차원의 공간의 하나의 점으로 바꾸어 표현한다는 것 입니다.
두 개의 vector 사이의 거리를 재보자: Eucliedian Distance
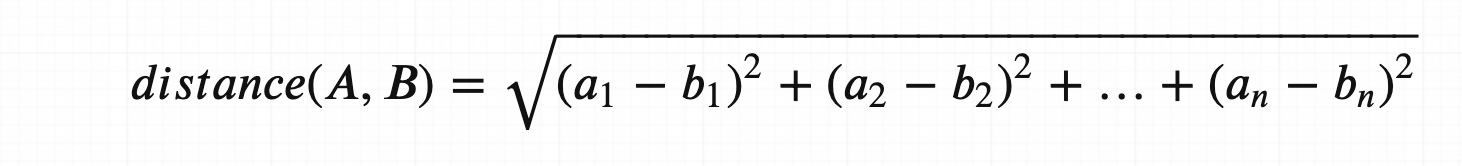
2차원에서 두 점 사이의 거리를 재는 것, 중학교 때 배우셨죠? 그걸 N차원으로 확대해봅시다. 수학은 같습니다, 그저 수식이 길어질뿐!
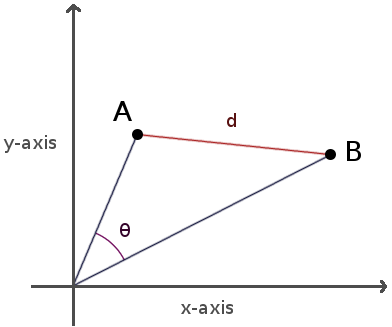
개념적으로 보았을 때에는 두 점 사이에 줄을 긋고, 그 줄의 길이를 계산하는 것 입니다.

두 개의 vector 사이의 각을 재보자: Cosine Similarity
Cosine similarity는 두 개의 vector들 사이의 각도를 계산합니다. 그렇기 때문에 크기(magnitude)는 무시되고, 방향의 차이만 계산됩니다.
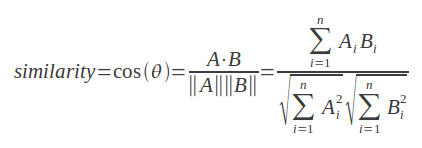
위 수식을 풀어서 이해하면, 만약 vector A와 vector B가:
- 같은 방향(0°)이라면 1,
- 완전히 반대 방향 (180°)이라면 -1,
- 서로 독립적(90°)이라면 0.
cosine distance는 cosine similarity랑 같은 걸 그냥 뒤집어서 생각한겁니다:
Cosine Distance = 1 - Cosine Similarity
만약 vector A와 vector B가:
- 같은 방향(0°)이라면 0,
- 완전히 반대 방향(180°)이라면 2,
- 서로 독립적(90°)이라면 1
그래서 뭘 쓰라고요?
NLP 문제에서는 cosine similarity가 주로 쓰입니다. 왜냐면 vector를 단어의 빈도 수 (frequency)로 계산하는 경우가 많기 때문입니다. 어느 단어가 몇 번 등장하냐는 글 길이에 영향을 많이 받고, 데이터 안 모든 글이 같은 단어 수를 가지기는 힘듭니다.
예를 들어, 어느 긴 글에 "bank"라는 단어가 100번 등장 하고, 어느 짧은 글에는 20번 등장한다 했을 때, 이 두 글이 경제라는 비슷한 주제라는 것을 알아 내려면, 절대적 거리를 계산하는 euclidean distance보다는 각도를 계산하는 cosine similarity를 쓰는게 더 적합할 것 입니다.
(이게 항상 정답은 아니기 때문에 본인이 계산하려는 vector의 수학적인 성격을 잘 파악해서 결정하는 것이 중요합니다.)
그렇다면 cosine distance는 구체적으로 어떻게 쓰일 수 있는 것일까요? 우리가 이미 배운 word2vec의 예시를 통해 더 깊게 알아보겠습니다!
Word2vec 공간을 cosine distance로 explore 하기
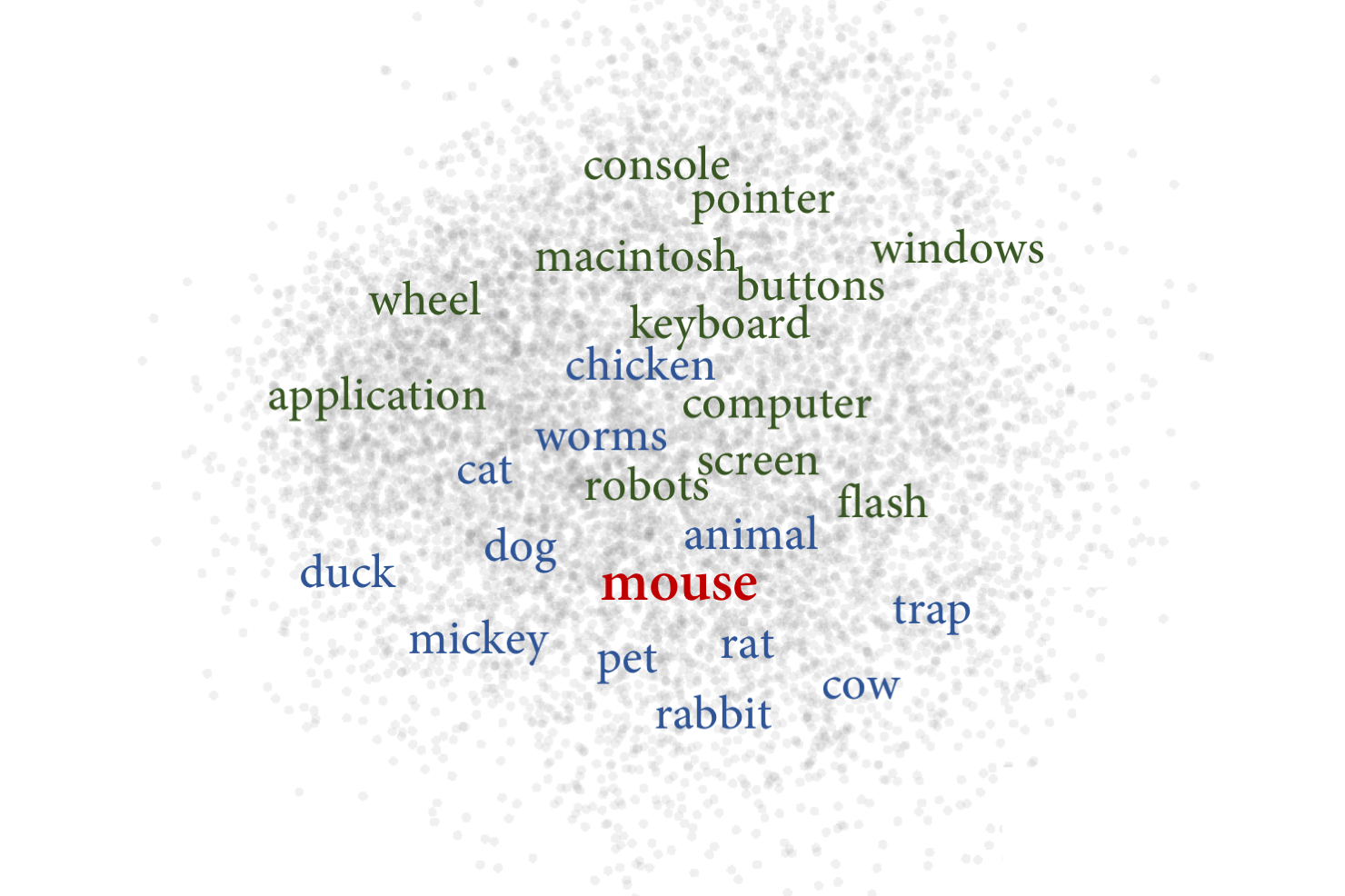
가장 많이 쓰이는 word embedding인 word2vec을 3D로 표현하면 어떻게 될까요? Tensorflow에 포함된 embedding projector라는 tool을 통해 살펴봅시다.
happy라는 단어를 검색하면 이러한 결과를 보여줍니다.
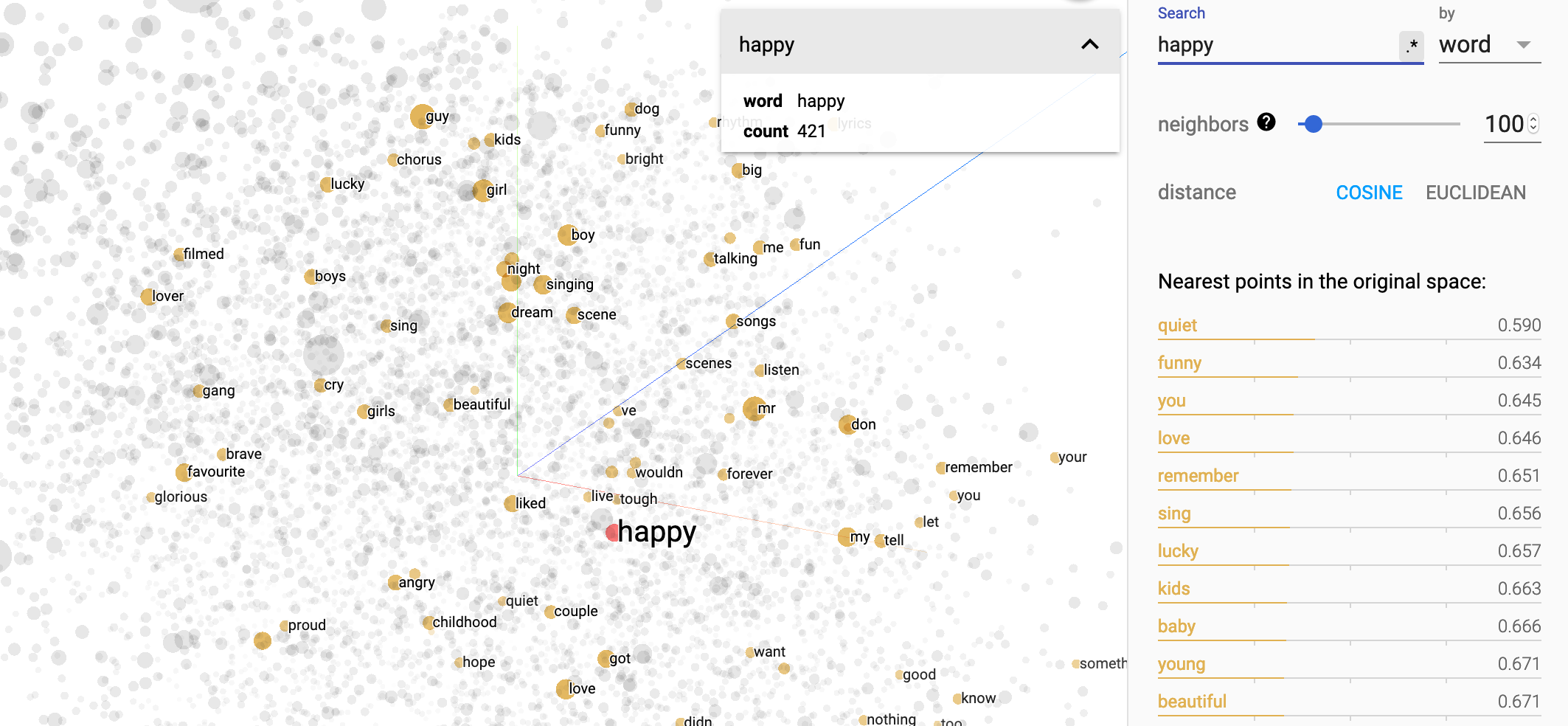
위 결과를 보면 happy의 가장 가까운 단어들 (Nearest points in the original space)을 quiet, funny, you, love, remember 등 다른 비슷한 단어들이 나옵니다.
다른 단어도 해볼까요?
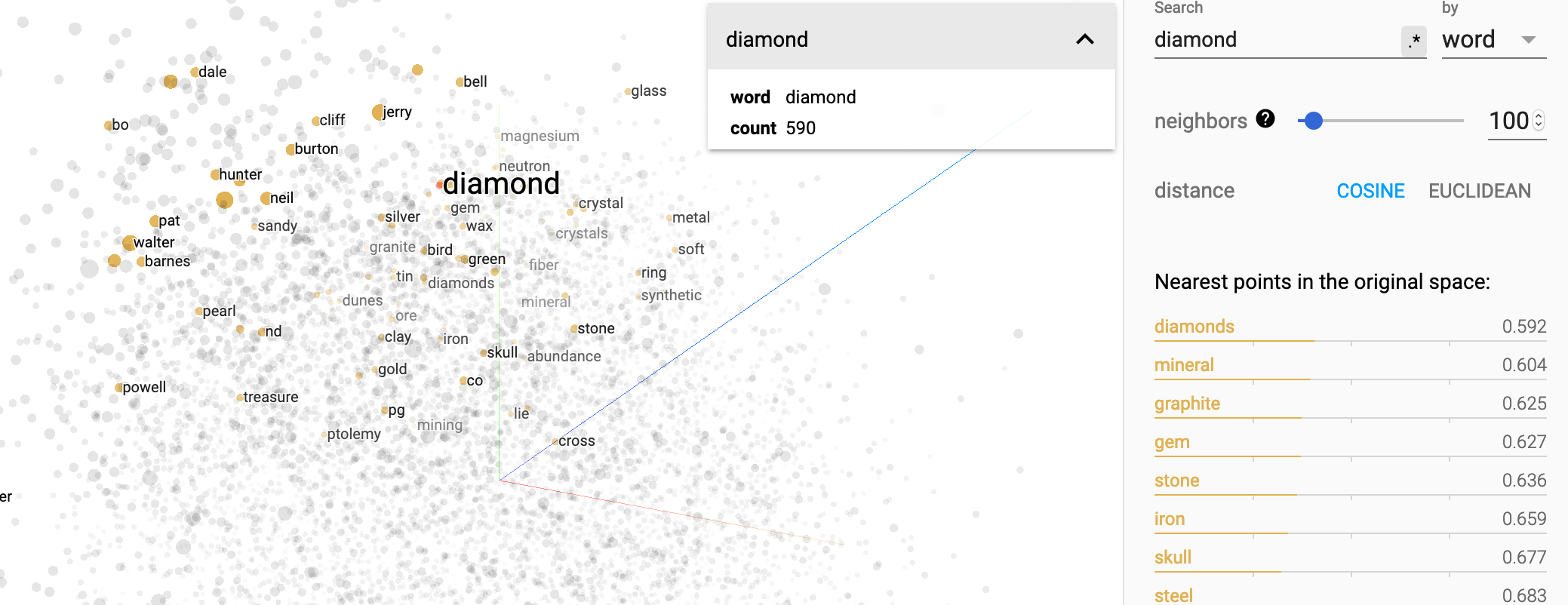
diamond와 가까운 단어로 diamonds, mineral, graphite, gem, stone, iron 등이 나옵니다. 주변 단어들을 통해 단어의 의미를 파악하는 skipgram 알고리즘의 원리를 기억하신다면 왜 이런 결과가 나오는지 감이 오실 겁니다!
embedding projector를 이용하여 이 단어 저 단어 검색 해보시길 바랍니다! visualization tool을 가지고 노는게 상당히 재밌기도 하고, word2vec과 cosine distance를 이해하기 참 좋은 방법입니다. 저는 embedding 관련 프로젝트를 할 때 꼭 이 tool을 이용하여 결과를 공유하곤 합니다.
이처럼 cosine distance는 vector들 간의 유사성을 계산하기 위해 쓰입니다. word2vec 뿐만 아니라 document embedding, item2vec 등 다양한 모델과 데이터에서 활용될 수 있습니다!
오늘 배운 cosine distance는 NLP/ML을 공부하실 때 아주 자주 나오는 중요한 콘셉트입니다. 질문이 있으시다면 코멘트로, 더 깊게 알고 싶으시면 아래 reference들을 참고해주시기 바랍니다.




