Week 56 - 외국어 천재 multi-lingual AI가 중요한 이유


새로운 언어를 배운다는 것은 또다른 하나의 세상을 여는 것과 같습니다. 하지만 언어 공부가 쉽지만은 않습니다. 영어만 공부해도 많은 시간이 들죠. 세상의 모든 이야기와 정보가 한국어로만 되어 있으면 얼마나 좋을까요. 하지만 옆 나라 일본에만 와도 말이 잘 통하지 않고 메뉴판의 문자를 읽을 수가 없습니다.
아시아, 유럽, 아프리카, 남미 등, 전세계에는 약 7천 개의 언어가 있다고 합니다. 가장 많이 사용되는 언어 10개는 순서대로 영어, 만다린 중국어, 힌디, 스페인어, 불어, 아랍어, 벵갈리, 러시아어, 포르투갈어, 인도네이시아어입니다.
이런 생각 해보셨나요?
“우리가 <위클리 NLP>에서 공부해왔던 모델, 시스템에 영어 말고 다른 언어에 사용 가능한가?”
여태까지 새로운 기술을 소개할 때 예시로 영어 또는 한국어만 사용해왔기 때문에 이러한 상상을 하시기 어려웠을지도 모르겠습니다.
모든 기술 분야가 그렇겠지만 더 많은 가치를 창출할 수 있는 것이 먼저 개발이 되고는 합니다. 그렇기에 글로벌 공용어인 영어를 다루는 NLP 모델이 먼저 발전하는 것은 당연합니다. 하지만 저는 미래에 더 많은 가치는 영어 외 다른 언어들에 있다고 생각합니다. 그래서 한동안 이 주제를 다루어보고 싶었습니다:
Multi-lingual NLP (다중 언어 자연어처리).
최근 연이어 나오는 소식만 보아도 이 주제가 얼마나 NLP에서 중요한지 알 수 있습니다:
- 구글 I/O 2022에서는 번역(Translate) 제품에서 여러 소수 언어 지원 추가 발표,
- Meta에서 200여 개의 언어를 번역할 수 있는 모델 공개,
- HuggingFace에 무려 46개 언어를 지원하는 언어 모델 BLOOM 공개.
이번 Week 56부터 이 후 몇 개의 포스트동안에는 Multi-lingual NLP에 대해 시리즈로 써보려고 합니다.
먼저, Multi-lingual NLP는 왜 중요한 것일까요? 단순히 세상에는 수많은 언어가 있다는 것 외에 몇 가지 이유가 있다고 생각합니다.

언어학적 탐구욕
여러 언어는 각자 독립적으로 발전해온 것이 아닙니다. 서로 알아 듣지 못하는 한중일 언어 간에도 공통된 뿌리, 한자(漢字)가 있습니다. 그렇기 때문에 한자어 기반으로 된 단어는 비슷한 발음을 갖습니다. 그래서 세 언어를 공부하다 보면 자연스럽게 한자를 중심으로 의미를 파악할 때가 많습니다.
비슷하게 라틴어(Latin)은 영어, 스페인어, 이탈리아어, 불어 등 유럽에서 파생된 여러 언어의 기반이 됩니다. 그래서 스페인어가 모국어인 친구들은 이탈리아에 가도 대부분의 메뉴를 읽을 수 있고, 어떤 이들을 영어를 좀 더 깊게 또는 효율적으로 공부하기 위해 라틴어를 먼저 공부하고는 합니다.
이렇게 다른 언어 간 공유되는 표현(representation)이 있다는 것은 학습에 있어서 무척 흥미로운 부분입니다. 여러 언어를 공부하다 보면 독립적으로 학습하는 것이 아니라, 세상을 이해하는 공통적인 개념들을 하나의 공간에 구조화하여 각 언어를 대응 시키는게 아닐까라는 생각이 들게 합니다.
“여러 개념들을 공간에 구조화한다” - 어디서 들어본 느낌이 드시지 않나요?
(Week 3: 벡터 공간, Week 4: <왕> minus <남자> plus <여자>= ? 복습하기)
이러한 언어 간 패턴은 AI 모델에게 데이터가 충분히 주어진다면 학습할 수 있을 것이라는 생각이 자연스럽게 듭니다. 한국어가 모국어인 사람이 스페인어가 모국어인 사람보다 일본어를 새로 배울 때 좀 더 유리하듯이, 스페인어보다는 한국어 데이터가 일본어 데이터를 함께 학습 시키는 것이 성능에 유리할 것 같다라는 가설을 세워볼 수도 있습니다.
또한, 인간이 어렸을 때부터 두세가지 언어에 노출되어 배우는 경우(bilingual)와, 하나의 모국어를 기반으로 외국어를 하나하나 배워가는 경우는 다른 것처럼, AI 모델을 학습시킬 때도 여러 언어의 데이터를 한꺼번에 학습시킬 수도 있고, 데이터가 많은 주요 언어에 먼저 학습 시킨 후 다른 언어를 추가 학습시킬 수도 있습니다.
이렇게 인간이 여러 언어를 공부하는 것과 AI가 학습을 하는 것은 비슷한 점도 많기에, 여러 질문이 떠오릅니다.
- 인간이 언어를 공부하는 것과 AI가 언어를 공부한다는 것은 어떤 공통점/차이점을 가지고 있을까?
- 인간이 배우는 방법을 따라하여 AI 학습 방법을 개선시킬 수 있을까?
- 반대로 AI를 이용하여 인간이 외국어를 공부하는 것을 쉽게할 수 있을까?
- AI를 통해 비슷한 언어들의 문법, 단어의 언어학적 뿌리를 탐색할 수 있을까?
- 반대로 여태까지 진행된 언어학 연구를 이용해 AI 개발 방법을 더 효과적으로 할 수 있을까?
이러한 언어학적 탐구욕을 충족하기 위해 많은 Multi-lingual NLP 연구가 진행되었다고 생각합니다.
하나의 모델로 엔지니어링 비용 줄이기?
하지만 어떤 연구에도 실용성을 빼놓고 생각할 수는 없겠죠. AI 연구는 결국 실제 제품에 사용되어 우리의 일과 생활을 윤택하게 만들기 위함입니다.
여러분이 AI 모델이 들어간 제품 개발 리더라고 상상해봅시다. 만일 제품이 여러 언어를 지원해야 한다면 어떻게 해야 할까요?
가장 쉬운 방법은 각 언어마다 모델을 따로따로 학습시키는 것 입니다.
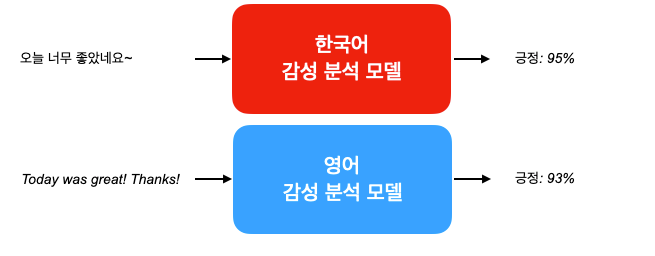
다만 이 시스템의 단점은 지원해야 하는 언어가 N개가 추가될 만큼 학습할 모델도 N개가 추가된다는 것 입니다. 그리고 학습을 위한 컴퓨팅 비용도, 모델을 서빙해야 하는 서버 비용도 그만큼 선형적으로 증가하겠죠. 만일 한꺼번에 10-20개의 언어를 다뤄야 한다면 큰 부담일 수 있습니다.
이를 타파하기 위해 한 개의 multi-lingual 모델로 통합하는 것을 고려할 수 있습니다.
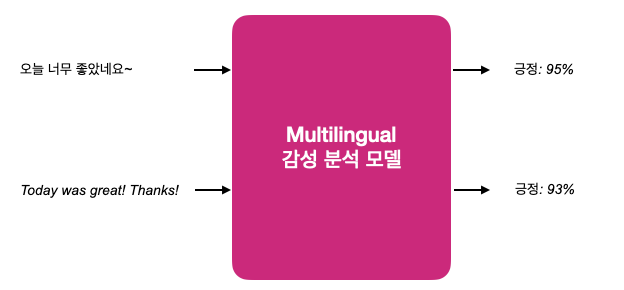
이렇게 하는 경우에는 하나의 언어를 추가하더라도 통합 모델 한 개만 유지해도 된다는 장점이 있습니다.
그렇다면 항상 하나의 multi-lingual 모델로 통합하는 것이 좋을까요?
모든 엔지니어링 결정에는 장단점이 있습니다. 만일 여러 언어의 데이터가 섞인다면 단 한번만 학습하면 된다는 장점이 있지만, 서로 영향을 줄 수 있어 AI 모델 개발에 복잡성이 증가합니다.
예를 들어, 잘 돌아가던 영어와 한국어가 통합된 모델이 있을 때, 일본어 데이터를 추가하였더니 한국어와 일본어는 성능이 좋아졌는데 영어에서는 성능이 떨어질 수도 있습니다. 만일 영어가 제품에 가장 중요한 언어라면 이렇게 되서는 통합 모델을 사용해서는 안되겠죠?
특히 학습, 평가 데이터가 변하지 않는다면 그나마 쉽지만, 실제로는 주기적으로 변화하는 경우가 많습니다. 그럴 때에는 통합 모델의 성능을 그때그때, 각 언어마다 잘 관리하는 것이 중요해지고, 무엇보다 복잡해집니다.
그렇기 때문에 “multi-lingual 모델은 하나로 통합되니깐 엔지니어링 비용이 줄어들겠네!"의 단순한 문제가 아닐 확률이 높습니다. 시스템의 복잡성 및 크기에 따라, 언어에 따라, 가지고 있는 데이터마다, 개발 팀 구성원의 역량에 따라, “케바케”로 결정해야 할 듯 싶습니다.
데이터가 부족한 언어 커버하기
그렇다면 왜 multi-lingual 모델이 주목을 받는 것일까요?
NLP 모델, 특히 언어 모델의 대부분의 학습 데이터는 인터넷에서 모아 사용하고 있습니다 (Week 29: GPT 편 참고). 인터넷은 압도적으로 영어 (61.7%)로 된 텍스트가 많습니다. 한국어는 17위로 0.5% 밖에 되지 않습니다.

NLP 학계에서는 데이터가 적은 언어들을 low-resource language라고 부릅니다 (반대는 high-resource). 많은 사람들이 사용하지 않아 인터넷에서 공개적으로 얻을 수 있는 학습 데이터가 적은 언어들을 지칭하는 것이죠.
하지만 상황에 따라, 풀고자 하는 문제에 따라 low-resource language가 다를 수도 있습니다. 예를 들어, 어떤 서비스는 한국인 유저가 많아 한국어 데이터가 많은데, 해외 유저가 많지 않아 영어, 일본어 데이터가 적을 수도 있습니다. 만일 서비스에 특화된 NLP 모델을 개발하고자 한다면 한국어가 high-resource고 영어와 일본어 데이터가 상대적으로 빈약한 low-resource라고 할 수 있습니다.
Multi-lingual 모델은 이러한 low-resource language 문제에 해결책이 될 수도 있습니다. 당장 데이터를 모으는 것이 힘들다면, 많은 데이터로 미리 학습된 high-resource 모델을 잘 재학습시키는 것이 적은 데이터만 가지고 학습시키는 것보다 성능이 좋을 확률이 높습니다.
또한 low-resource 언어는 라벨된 데이터를 얻기가 힘들어, 지도 학습(supervised learning)을 하기 힘들 수도 있습니다. 라벨링 작업을 위한 크라우드워커를 찾기가 힘들기 때문입니다. 이럴 경우에는 라벨되지 않은 데이터를 얻어 multi-lingual 모델에 비지도 학습(unsupervised learning)을 하여 성능을 올릴 수도 있습니다.
지난 Google I/O 2022에서 번역(Translate) 제품이 이러한 방법을 활용하였다고 발표하였죠.
이처럼 Multi-lingual 모델은 필요한 어떤 언어의 데이터가 부족할 때 요긴하게 사용될 수 있습니다.
이번 글에서는 Multi-lingual NLP는 왜 중요한 것인지 다루어 보았습니다. 아직 실질적인 연구나 방법에 대해서는 깊게 들어가지 않았는데요. 앞으로 나올 몇 개의 글에서 시리즈로 다룰 생각입니다.
저도 공부를 하면서 쓰고 있기 때문에 혹시 더 알고 싶은 주제가 있거나 추천하는 논문/자료가 있다면 댓글로 알려주시면 감사하겠습니다!




