Week 9 - 글을 그림처럼 보는 Convolutional Neural Network (CNN)


속독 (速讀) 학원이 한창 유행하던 때가 있었죠. 정보가 넘쳐나는 현대에 빠르게 글을 읽고 이해하는 것은 정말 누구나 탐내는 능력일 듯합니다. 저도 한참 공부를 많이 하던 중학생 때 그런 능력을 가진 분들이 참 부러워, 학원까지는 가지 않고 인터넷으로 어떻게 하는지 찾아 따라 해 본 적이 있습니다.
글을 한 단어, 한 단어 읽지 말고 덩어리로, 그림처럼 보세요.
이게 뭔 소리지? 글은 글인데, 어떻게 그림처럼 보라는 거지? 제 뇌의 처리 능력이 부족해서 그런지, 저는 책을 어떻게 보든 글로 보이지 그림으로 보이지가 않더라고요. 그래서 결국 속독을 셀프 터득하는 것은 금방 포기하고 말았습니다.
몇 년이 지난 지금, NLP를 공부하다가 컴퓨터가 글을 그림처럼 볼 수 있다는 것을 배웠습니다. "역시 컴퓨터는 나보다 월등한 존재였구나..." 하면서 이 아이디어에 상당히 감탄했습니다. 그리고 저의 연구 논문뿐만 아니라, 현재 머신러닝 응용에도 계속 이 방법론을 활용하고 있습니다. 이게 어떻게 가능하냐고요? 계속 위클리 NLP를 읽어왔던 여러분은 이미 답을 알고 있습니다!

Computer Vision의 최강자, Convolutional Neural Network (CNN)
이제 저는 CNN이라는 약자를 보면 방송국보다는 이 모델이 먼저 떠오릅니다. Convolutional Neural Network는 Deep Learning의 아버지, NYU의 Yann LeCun 교수가 발명한 인공신경망 (neural network)의 일종입니다. 가장 큰 특징은 공간에 대한 이해도가 높은 설계를 가지고 있다는 점입니다.
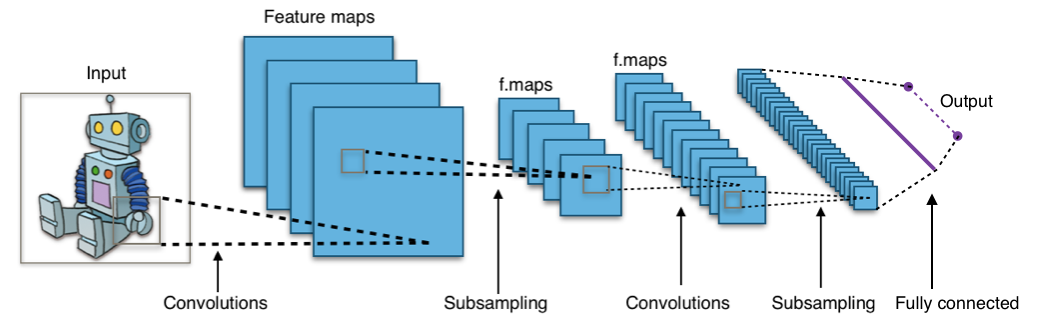
위 그림과 같이 이미지의 부분 부분을 현미경으로 줌 인하여 봅니다. 이것을 필터(convolution filter)라고 하는데, 이 필터를 이미지 전체를 훑으며 살펴보도록 움직여 전체 이미지에 대한 이해를 형성하는 구조를 가지고 있습니다. 저의 설명은 굉장히 요약한 것이니, CNN에 대해 더 알고 싶으면 이 블로그를 더 살펴보시길 바랍니다.
CNN은 Computer Vision (CV) 분야에 엄청난 혁신을 가져왔습니다. 사물 인식, 얼굴/표정 인식 등 주요 CV 문제들은 엄청나게 많은 학습 데이터로 거대하고 딥 (deep)한 CNN 모델을 만들면 인간이 눈으로 사물을 인식하는 만큼 잘할 수 있게 되었습니다. 최근 10년 간은 CNN으로 인해 CV 분야가 전성기를 맞게 된 게 아닐까 싶습니다.
Word embedding을 쌓아서 그림처럼
그렇다면 글을 어떻게 그림 (이미지)처럼 본다는 것일까요?
일단 이미지는 어떻게 생겨 먹은 데이터인지 생각해보아야 합니다.
앞에 Week 4에서 배운 word embedding은 단어를 N x 1 매트릭스, 즉 column vector로 표현했던 게 기억나시나요? 만약에 한 문장의 모든 단어들의 word embedding들을 전부 쌓아버리면 어떻게 될까요?
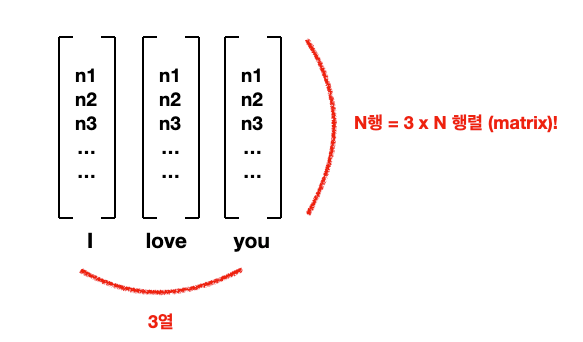
"I" 도 N x 1 column vector, "love"도 N x 1 column vector, "you"도 N x 1 column vector. 옆으로 쌓아 버리면 3 x N 매트릭스가 만들어집니다. 만약 문장에 10개 단어가 있고, embedding의 사이즈가 300이라면 10 x 300 매트릭스가 되겠죠? 그러면 가로 10, 세로 300의 길쭉한 이미지라고 생각하시면 됩니다.
아래 이미지 처럼 각 word embedding을 heatmap 이미지처럼 표현할 수도 있습니다.
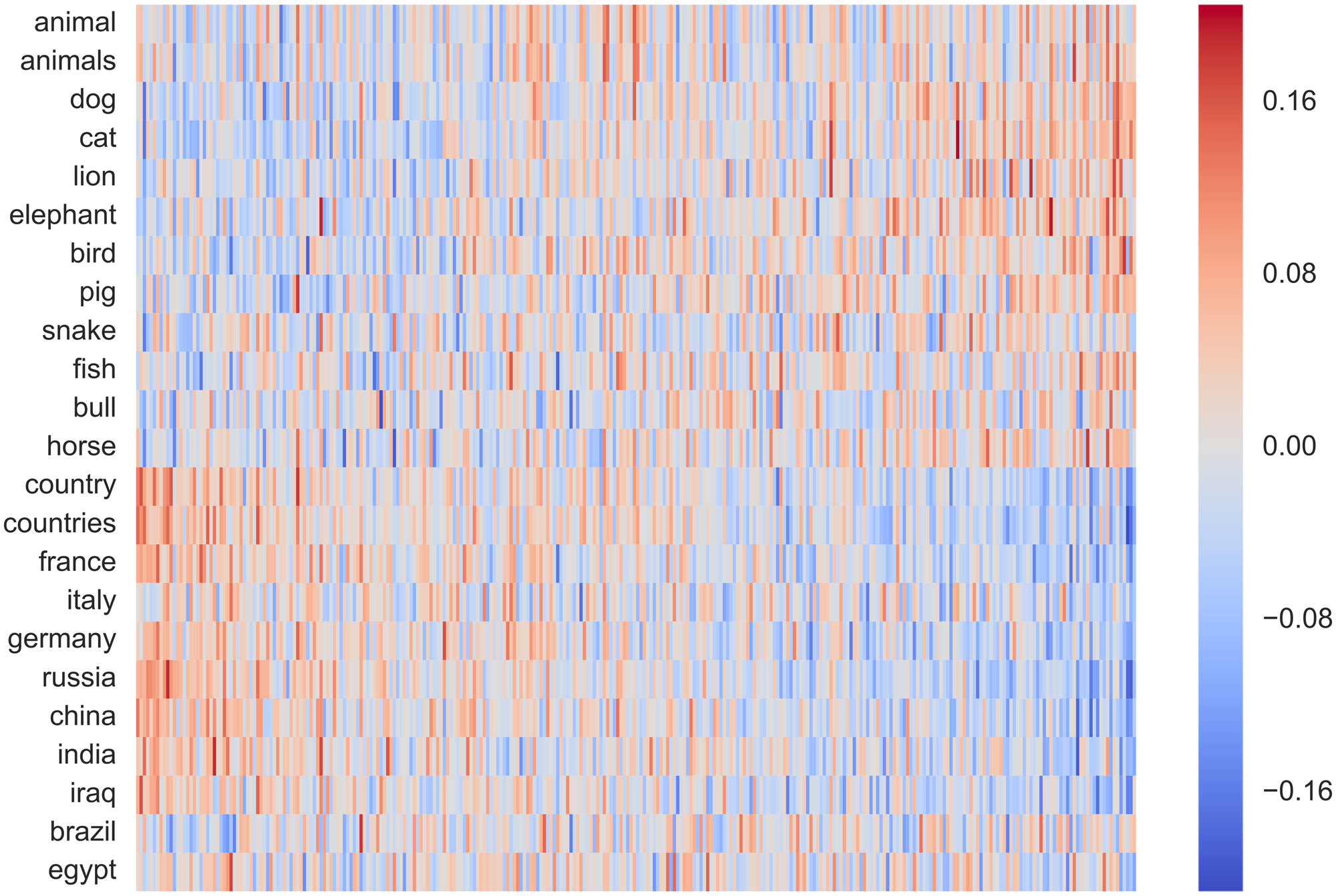
이처럼 word embedding을 활용하면 어떠한 문장도 2차원 매트릭스로 표현 가능합니다! 그러면 CNN을 쓸 준비가 다 되었습니다!
NLP에 Computer Vision 기술을 부워보자
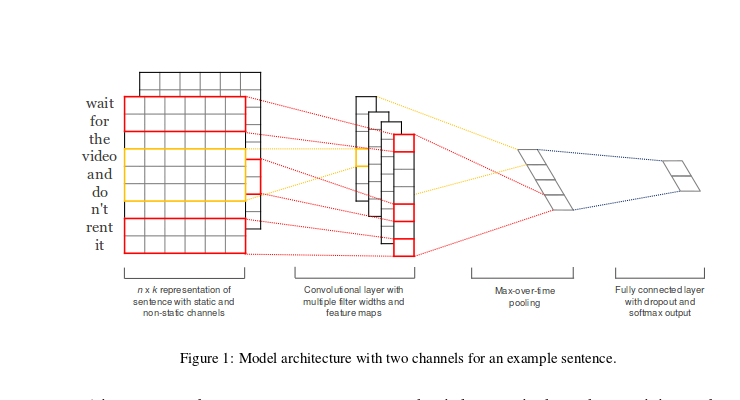
단어를 보는 CNN (이하 WordCNN)이 이미지를 보는 CNN과 조금 다른 점은 2D 필터가 아니라 1D 필터를 쓴다는 점입니다.
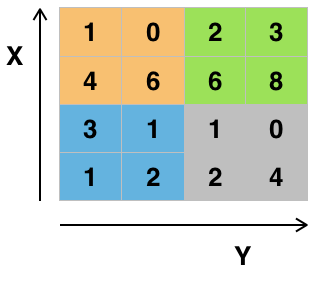
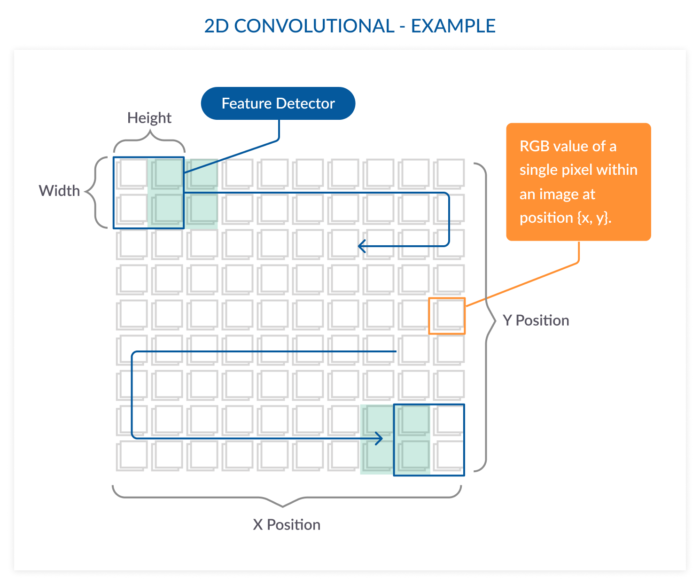
이게 무슨 차이점이 나면, 이미지에 사용되는 2D 필터는 아래 사진처럼 x축과 y축의 공간 관계를 고려합니다. 우리가 눈으로 사진을 훑는 것과 비슷하지요.
근데 NLP에 사용하는 CNN은 아래와 같이 하나의 축만 고려하는 1D 필터를 사용합니다.
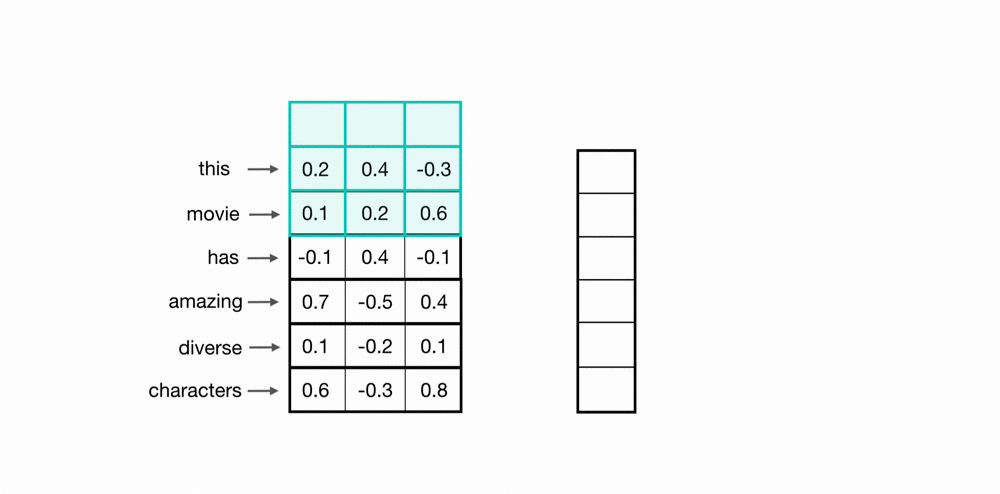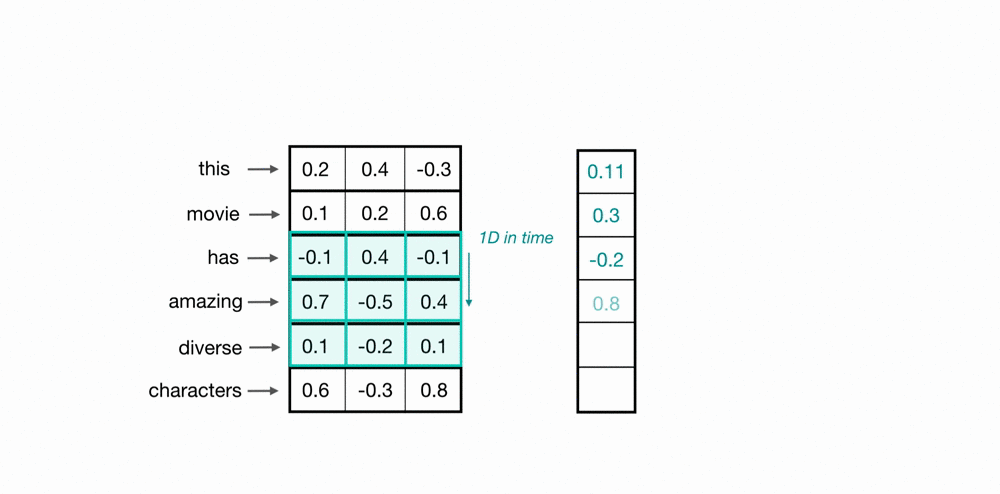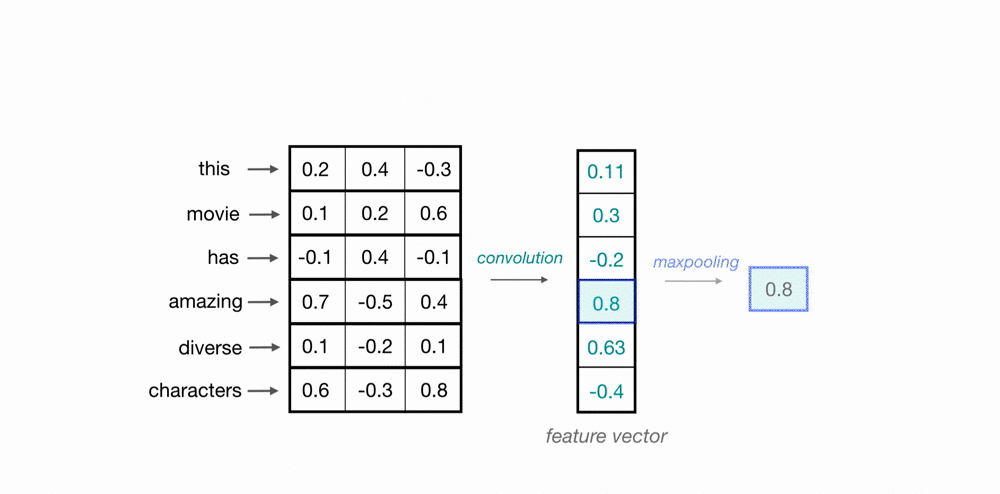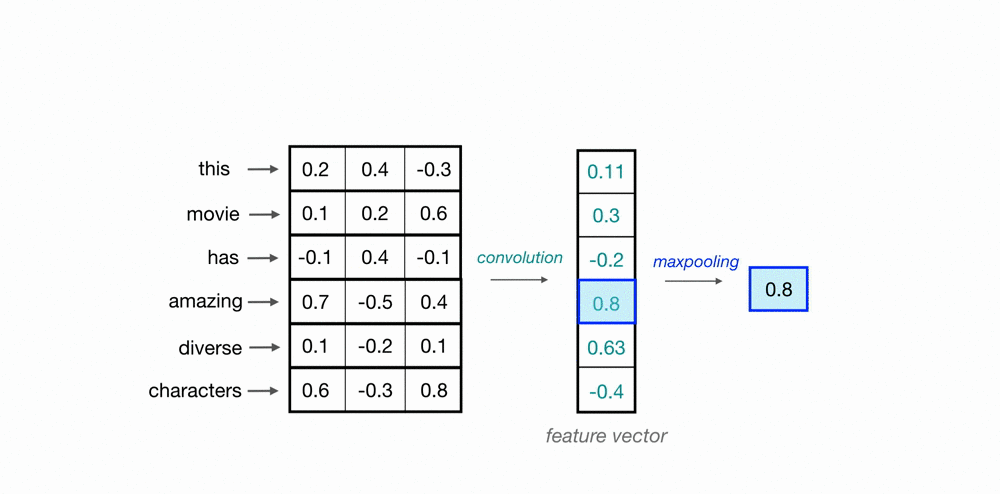
이는 애초에 word embedding은 이미지의 위, 아래나 왼쪽, 오른쪽처럼 어떠한 공간적인 관계를 가지고 설계된 게 아니기 때문입니다. 그렇기 때문에 위의 예시처럼 1D CNN은 한번에 단어 전체의 vector 3개 숫자를 고려합니다. (위에는 하나의 단어를 column vector가 아니라 누워있는 row vector로 표현했네요).
**1D Convolution을 더 깊게 이해하고 싶으신 분은 위키독스의 이 블로그를 참고바랍니다.
WordCNN은 위 논문에서 감정 분석 (sentiment classification), 질문 유형 분석 (question type classification), 객관/주관 유형 분석 (subjectivity)에서 뛰어난 성능을 보여줍니다. 그 이후에 수많은 논문에서 다양한 문제들에 활용이 되었습니다 (저의 abusive language detection 연구도 ^^).
나도 덕 좀 보고 살자 ~ pretrained word embedding
Week 4에서 word2vec, 그리고 GloVe를 소개해드렸습니다. 얘네들은 어떻게 데이터가 있을 때 단어에 대한 정보를 vector 속에 학습할 수 있을지에 대한 알고리즘입니다.
Pretrained embedding은 알고리즘들을 이용하여 엄청나게 많은 (진짜 엄청나게 많아서 학습이 진짜 좋은 컴퓨터에서도 몇날며칠이 걸리는) 데이터로 학습한 결과물입니다. 자비롭게도 Google, Stanford, Facebook 등이 누구나 가져다 쓸 수 있게 공개해놓았습니다.
Pretrained word embedding은 데이터가 없거나 적은 대부분의 우리들에게 단비 같은 존재입니다. 시험을 보러 가기 전에 우리 두뇌에 미리 국어사전을 장착한 것과 같은 원리이지요! 각 웹사이트에 들어가서 다운로드 받으실 수 있는데, 그냥 말그대로 몇 만개의 단어 마다 100개 또는 300개의 숫자가 들어있습니다.
실제로 WordCNN 원 논문을 비롯하여 pretrained word embedding을 사용했을 때 성능이 올라갑니다. 특히 학습 데이터가 적을 때 더더욱 효과적이기에 이제는 웬만하면 가져다 놓고 시작하는 것이 상식 중의 상식이 되었습니다.
이는 머신러닝에서 transfer learning이라고도 하는데, 자세한 건 다음에 다루고 오픈소스로 다운로드 받을 수 있는 pretrained embedding의 대표적인 3개를 소개해드리겠습니다.
1. word2vec ~ skipgram으로 Google News (100B 단어)로 학습한 Google의 word vector.
2. GloVe ~ Matrix factorization으로 학습된 Stanford의 word vector. 위키피디아 6B 단어 버전, Common Crawl 420B 단어 버전, 또는 Twitter 27B 단어 버전 3 가지 모두 공개
3. FastText ~ skipgram의 업그레이드 버전으로 학습된 Facebook의 word vector. 영어뿐만 아니라 157개 국어 버전을 공개한 것이 큰 장점.
위클리 NLP에서 처음으로 딥러닝 모델을 다루어 보았는데 어떠신가요?
CNN 같은 모델은 그 자체가 꽤나 공부해야 할 내용이 많은 주제이기 때문에 깊게 공부하실 분들은 꼭 추가로 시간을 내 다른 튜토리얼이나 논문들을 읽어보시기를 추천합니다.
저는 좀 더 NLP 문제 자체에 대한 설명에만 집중하고 머신러닝 모델 자체에 대해서는 비교적 간략하게 콘셉트만 소개해드리고 넘어가는 식으로 하려고 합니다. 혹시 이해가 안 되는 부분이 있다면 댓글로 꼭 달아주시길 바랍니다!
앞으로 딥러닝 모델들이 더 많이 등장할 예정입니다. 이제 정말 NLP와 딥러닝은 떼놓을 수 없는 관계가 돼버렸습니다.




