AI 시대에서 "나"다움이란 무엇일까


나의 정체성을 추천 시스템이 정의해주는 건 편하지만 싫어
고등학교 때 나는 록 음악을 정말 많이 들었다. 교내 밴드 동아리에서 드럼을 치면서 Green Day, Muse, Oasis, Metallica에 입문했다. 주말에는 홍대에 가서 라이브 음악을 찾아들었다. 여름 방학에는 록 페스티벌에 가서 모르는 사람들과 부딪히며 슬래밍을 했다. 그때는 아이팟에 들어가는 플레이리스트가 나의 보물이었다. 아티스트 별로 정리되는 iPod의 UX가 너무나 좋았다.
하지만 지금 나는 Spotify로 음악을 듣는다. 프로그래밍을 돈벌이로 하는 어른이 된 나에게 음악은 컬렉션보다는 노동요에 더 가까워졌다. 가사가 없는 재즈, EDM, 클래식 등이 집중할 때는 최고다. 그래도 출퇴근 시간에는 내가 직접 좋아하는 아티스트를 검색해 찾아 듣긴 한다.
Spotify에서 빠져나올 수 없는 점은 쓰면 쓸수록 내 "취향"을 잘 분석해서 음악을 추천해준다는 것이다. 거의 무제한으로 새로운 음악을 추가해 플레이리스트를 만들어주거나 추천해주는데, 내가 선택하지도 않은 듣도 보도 못한 음악임에도 불구하고 전혀 이질적이지 않을 때가 많다. 심지어 Your Daily Mixes라는 나만을 위한 플레이리스트를 한 6개를 만들어주는데, 1번은 20대 중반부터 듣던 K-Pop, 2번은 청소년 때부터 듣던 K-Indie, 3번은 20대 초반에 많이 듣던 EDM 등 이런 식이다.
어렸을 때는 나의 음악 플레이리스트, 티켓을 사서 보러 간 인디 밴드, 우리 밴드가 커버 연주를 하던 음악이 "나"다운 것이라고 생각해 큰 자부심이 있었던 기억이 있다. 그렇기 때문에 어떤 음악이 좋은지 친구들과 목소리를 높이면서 토론하고 "강추 강추"하며 공유했을 것이다. 문득 이런 생각이 들었다.
근데 Spotify가 만들어주는 무제한 스트리밍 플레이 리스트를
나의 음악 취향이라 할 수 있는 건가?
사실 나는 오랜 시간 동안 왓챠에서 보여주는 예상 평점을 나의 영화 취향을 너무 잘 안다고 신기해하고 맹신해 온 사람이다. (심지어 그 회사에서 인턴도 한건 비밀) Spotify는 왓챠처럼 내가 본 영화 별점 컬렉션 같이 본인의 취향을 쌓는 기능이 없기 때문에 더 그렇게 느끼는 걸까? "Your Time Capsule", "Top songs of 20xx" 이런 류의 플레이스트 기능이 있긴 하다.
그리고는 Google Smart Reply가 등장했다.
AI가 나와 함께 글(이메일)을 쓰기 시작했다. Gmail에 새로운 기능이 추가되었다.
네이버나 구글 같은 검색엔진과 스마트폰 키보드에 쓰이던 자동완성이 드디어 작문의 영역까지 넘어온 것이다. 몇 달 써본 나의 후기는, 너무나 편하다는 것이다. 특히 업무 메일을 쓸 때는 상투적으로 써야 하는 것들이 꽤 있는데, 이 기능이 이보다 좋을 수는 없다고 느꼈다. 아마 구글은 곧 이 기능을 통해 사용자들이 이메일을 쓰는 시간이 얼마나 줄어들었는지에 대한 연구를 발표할 것이다.
자연어 처리(NLP)를 공부했던 나는 Smart Reply 출시하기도 전에 구글이 이 기능에 대해 발표한 논문을 읽었다. "아, 역시 구글이구나" 하면서도 어떤 기술을 써서 구현했는지 더 관심이 갔다. 하지만 출시 이후에는 사용자로서 느끼는 게 더 많았다.
편하기도 하면서도 나의 글이 정말 표준화되고, 밋밋해지는 느낌을 받았다. 이메일이 입체적이여 봐야 얼마나 그럴까 싶기도 하지만, 업무 상 커뮤니케이션에 꽤나 큰 부분을 차지하는 이메일은 다른 동료들이나 외부 업체 사람들이 나를 알게 되는 가장 큰 통로기도 하다.
더 재밌지만 무서운 것은 이 스마트 자동 완성(Automatic Text Generation)의 영역은 이메일에서 멈추고 있지 않다. 채팅, 댓글, 이야기, 시, 프로그래밍 코드 등 다양한 분야에서의 연구가 시도되고 있다. 재작년 NLP 학회에서 페이스북의 어떤 연구자가 발표한 자동 시 생성 (Automatic Poetry Generation)에 대해서 우리 지도교수님이 "그건 시가 아니야. 네 여자 친구한테나 가서 읽어줘 ("That's not poetry. Only read it to your girlfriend.")라고 공개적으로 비판해서 그 커뮤니티에서 화제가 되었던 기억이 난다.
그날은 그런 비판을 했음에도 불구하고 홍콩과기대 연구소에서는 올해 기사에 자동으로 댓글을 생성하는 연구를 발표했다. 신문 기사나 제품이 처음 발표되었을 때 독자 댓글이나 유저 리뷰가 아무것도 없을 때를 위한 기술이라고 하는데 (무플 방지 선플 운동), 재밌기는 하지만 최근 여론 조작 사건들을 생각했을 때, 이것이 악용되었을 때 얼마나 끔찍할지 걱정이 된다.
머신러닝 AI의 본질은 정규 분표(normal distribution)이다
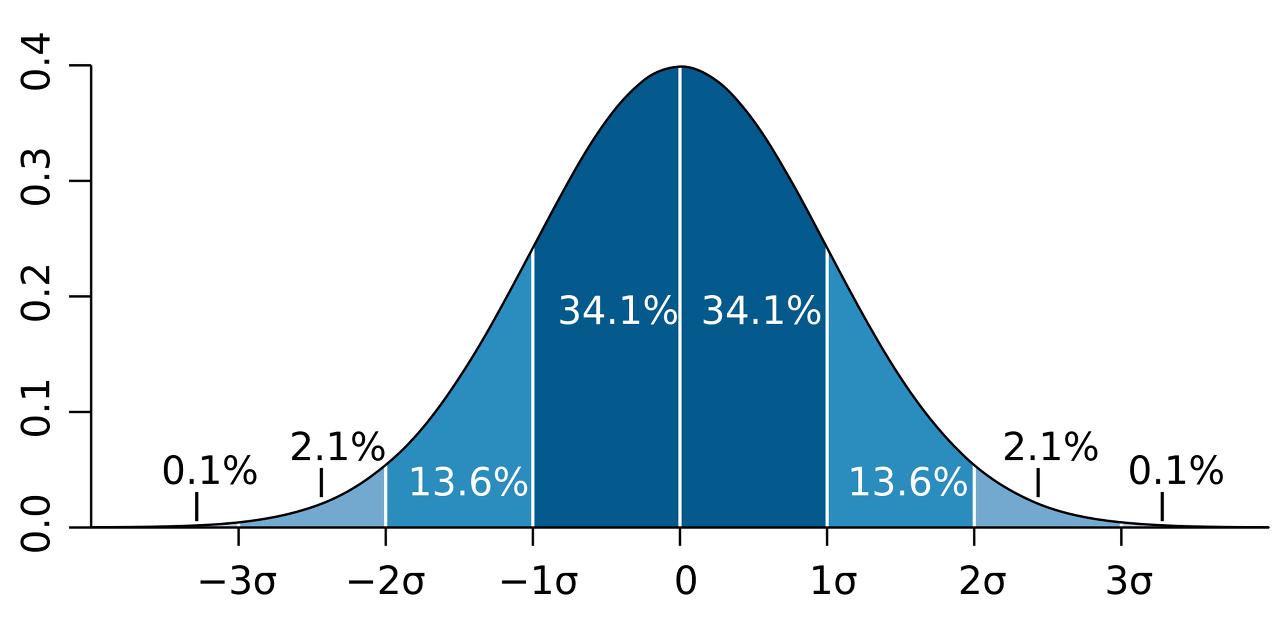
여태까지 소개한 추천 시스템, 언어 생성 AI 모두 다 데이터를 기반으로 한 확률, 통계 기계다. 머신 러닝의 본질은 최대한 많은 데이터를 받아들이고 분석하여 결국 확률로 치환하는 것이고, 데이터가 많이 쌓이고 쌓일수록 "normal"한 것을 정의할 수 있게 된다. 한 사람의 취향을 완벽하게 이해하지 못하더라도 시스템이 관찰한 불완전한 데이터 (검색 기록, 클릭, 별점 등)만으로도 그 사람만의 확률 곡선을 그릴 수 있다. 그러고 나서 그 사람이 "normal"하다는 가정을 하고 무엇을 추천해줄지 결정해준다. 그렇다면 꽤나 높은 확률로 우리 취향에 맞을 음악이, 우리가 쓰려고 했던 그 단어들이 튀어나온다.
그렇기 때문에 엄연히 말하자면 이것들은 우리의 취향이 아니다. 수천명, 또는 수만명의 다른 사람 중 비슷한 사람들의 데이터를 분석해서 나온 통계, 확률 AI 시스템의 결과이다. 어떻게 보면 우리를 흉내내고 있는 것이라고 볼 수도 있겠다. 꽤나 흉내를 잘 내기 때문에 우리는 그것이 나라고 착각한다.
가장 큰 문제는 우리들의 취향이
AI 시스템의 추천을 통해 형성되고 있다는 점이다.
원래 AI 시스템은 우리들의 취향을 분석하기 위해 만들어졌다. 하지만 점점 우리들은 이 시스템에 의존하는 존재가 되어가고 있고, 매일 무제한으로 추천되는 기사, 음악, 단어들은 우리들을 저 정교 분포의 가운데로 몰아넣고 있다. "나"다움은 점점 사라지고 시스템이 피딩(feeding) 해주는 것만 소비하는 존재가 되어가고 있는 것이다. 우리는 인스타그램, 페이스북, 유투브, Spotify, 넷플릭스 등에서 먹여주는 것들에서 벗어나지 못한다.
그러나 창의적이고 새로운 것들은 아마 저 곡선의 꼬리 (2.1%, 0.1%라고 쓰여있는)에 분포해있을 것이다. 하지만 현재 대부분의 AI 시스템은 확률적으로 낮다고 하여 저 부분을 잘라낸다. (어떻게 생각해보면 대부분의 사람들도 그럴지도 모른다) 전설적인 Queen이 처음에 6분짜리 Bohemian Rhapsody를 들고 갔을 때 메이저 음반 제작 회사에서 출시를 거부했다. 하지만 용감한 그들은 다른 용감한 제작자를 찾아 성공했고, 그들은 New Normal이 되었다.

모든 새로운 것들은 그러한 용감한 사람들로부터 시작된다.
하지만 AI 시스템은 용감하지 않다. 왜냐면 용감한 건 확률적으로 낮기 때문이다.
결국 AI 시대에서 "나"다움을 지키려면 조금 더 용감해져야 하는 거 아닐까. 편한 것에서 벗어나서 새로운 경험을 자꾸 시도해봐야 하지 않을까. 여행을 갈 때도 블로그만 보지 말고 방향 없이 걸어보고, 생소한 장르의 음악을 들어보기도 하고. 실패하는 경우가 있더라도, 평소에는 확률적으로 하지 않을 짓을 가끔은 해보는 것이다.
또한 나 같은 AI 개발자들은 이러한 시스템의 한계점을 인지하고 해결하려는 노력을 해야겠다. 연구를 하던 후배와 Youtube 추천 알고리즘이 너무 질린다는 불평을 하면서 했던 얘기가 기억난다.
"어떻게 하면 새로우면서도 낯설지 않고, 짜릿하면서도 편안한 것을 찾아주는 추천 시스템을 만들 수 있을까?"
1조짜리 질문이 아닐까 싶다.



