Week 1 - 컴퓨터에게 언어는 어떤 의미일까?
우리는 언어라는 것을 어떻게 인식하고 있을까요? 여러분에게 언어는 무엇인가요?


인간은 언어를 어떻게 인식하고 있을까요? 컴퓨터에게 언어는 어떤 의미일까요? 국어사전에 의하면 언어라는 것은 이렇게 정의되어 있습니다.
언어(言語) - 생각, 느낌 따위를 나타내거나 전달하는 데에 쓰는 음성, 문자 따위의 수단. 또는 그 음성이나 문자 따위의 사회 관습적인 체계 (표준국어대사전)
체계. 즉, 하나의 시스템이라는 것이 먼저 눈에 띕니다. 이 글을 눈을 통해 시각 정보로 받아들이지만 머릿속에는 일종의 정보 시스템이 있기 때문에 저의 생각이나 느낌을 글로 여러분께 전달할 수 있는 것일 겁니다. 어렸을 때, 처음 언어를 체계적으로 배울 때를 생각해봅시다.
먼저 우리는 알파벳 (abcd), 한국어는 자음(ㄱㄴㄷㄹ)과 모음(ㅏㅑㅓㅕ)을 먼저 배웁니다. 이러한 문자열 (character)이 모여, 음절 (syllable)이 되고, 더 나아가 단어(word)를 배웁니다.
문자열 (character) => 음절 (syllable) => 단어 (word)
여기서 뜻을 가지는 가장 작은 단위는 단어입니다. 많은 문자열이 모여도 단어로 이루어지지 않으면 어떠한 의미를 담지 못합니다.

모든 것을 숫자로 보는 컴퓨터
컴퓨터는 모든 것을 숫자로 봅니다. 처음 태어났을 때도 0101로 이루어진 이진법 숫자로 모든 계산이 이루어졌고, 지금도 그 시스템을 기반으로 발전해왔습니다. 이것을 디지털이라고 합니다.
우리가 눈으로 보는 것들은 이미지, 즉 픽셀로 표현되고, 귀로 듣는 것들은 음파로 표현이 됩니다. 픽셀과 음파는 모두 숫자로 표현이 된다는 공통점을 가지고 있습니다. 이 숫자들은 컴퓨터에게 입력 데이터가 됩니다. 예를 들어, 고양이 이미지 수천 장과 고양이 이미지가 아닌 것 수천 장을 주면 컴퓨터는 처음 보는 픽셀들을 보고 고양이인지 아닌지 예측할 수 있게 학습이 되는 것이죠.
그렇다면 언어의 가장 작은 단위, 단어는 어떻게 숫자로 표현이 될 수 있을까요?
일단 아는 단어를 다 써봐! Vocabulary 만들기
지금까지 제가 배운 단어는 대략 몇 개나 될까요? 표준 대국어사전에는 총 501,000여 개의 어휘가 수록되어있다고 하는데, 제가 일상생활에서 사용하는 건 많아봤자 천 개(?) 정도 밖에 되지 않을까 싶습니다. 책을 많이 읽으신 분들은 훨씬 더 많은 어휘 개수를 알고 계시겠지요.
일단 단어를 숫자로 표현하기 위해서는 알고 있는 모든 단어의 명단을 만들어야 합니다. 이는 보통 vocabulary라고 부릅니다. 그리고 순서대로 숫자를 하나씩 줍니다. 예를 들어, 내가 아는 단어가 총 5개 (hello, world, natural, language, processing)라 가정해보면 이러한 그림이 나옵니다.

이 숫자를 우리는 index 또는 id라고 부릅니다. 마치 반 아이들에게 번호를 주는 것처럼요. 선생님께서, "오늘 4월 3일이네, 칠판 지울 사람 3번 누구니?", "네~ natural입니다" 이런 거죠!
더 나아가 우리는 이것을 vector로 표현해봅시다. Column vector는 Nx1 matrix로, 앞으로 자주 등장할 것입니다. 숫자 N개를 기둥처럼 쭉 세워놓은 것이라고 생각하면 됩니다. 그러면 앞서 말한 index를 어떻게 column vector로 표현할 수 있을까요? 간단하게 해당하는 id 번째 열을 1로 채우고, 나머지는 0으로 채우면 됩니다.
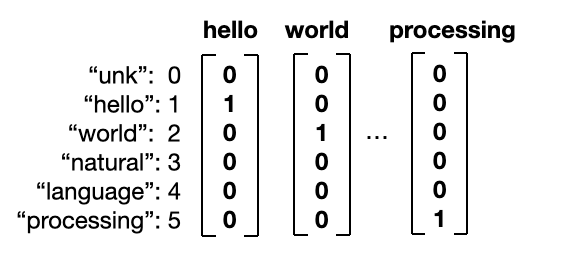
**여기서 index 0에 등장하는 unk는 모르는 단어 (unknown)를 뜻합니다. 나중에 새로운 단어를 보았을 때 모른다는 표시를 하기 위함이죠. 아, 컴퓨터는 숫자를 0부터 센다는 거는 알고 계셨죠?
이렇게 모든 단어를 vector로 표현하는 것을 one-hot vector라고 합니다. 모든 열 중에 단 한개의 숫자만 1이고, 나머지는 0으로 표현되기에 이러한 이름으로 불립니다.
자주 쓰이는 단어만 알고 싶다 ~ word frequency를 이용한 vocabulary 구성
대부분의 NLP task는 아는 단어를 모아 vocabulary를 구성하는 것부터 시작합니다. 가지고 있는 데이터를 전부 끌어모으는 작업이 먼저일 텐데요. NLP에서 이 데이터를 corpus라고 부릅니다.
먼저 corpus 안에 있는 전부 모아 단어를 셉니다. corpus가 크면 클수록 구별되는 단어의 개수가 늘어나겠죠? 크면 개별 단어의 개 수가 몇 천 개, 몇 만개가 될 때도 있습니다. 그렇다면 이 모든 단어를 모두 vocabulary에 포함하여 사용하는 것이 맞을까요?
때에 따라 다르지만, 주로 vocabulary를 구성할 때에는 각 단어의 빈도수 (word frequency)를 살펴봅니다. 주로 통계학적 분석을 하거나 모델을 학습시킬 것이기 때문에 한두 번 나오는 단어는 무의미할 것이라는 가정을 하는 것이지요. (물론 이 가정이 때로는 틀릴 경우도 있지만!) 그렇게 corpus에 사이즈에 따라 최소 빈도수 (minimum frequency)를 정해 몇 번 이상 나오는 단어만 사용하거나, 총 vocabulary size를 정하고 빈도 수가 큰 단어부터 포함시키는 식으로 vocabulary를 구성합니다.
이번 주에는 언어의 가장 기본이 되는 단어가 어떻게 컴퓨터에게 숫자로 표현되는지 알아보았습니다. 그렇다면 여러 개의 단어가 모인 문장 또는 문서는 어떻게 표현이 될까요? 다음주에 알아보도록 하겠습니다~




