Week 19 - 언어 모델을 가지고 트럼프 봇 만들기?!


최근 윤종신 아티스트님이 구글 코리아에서 강연을 했던 것을 들었는데, 그 중 아주 인상 깊은 부분이 있었습니다. 청중 한 분이 “AI가 너무 발전해서 윤종신의 음악의 패턴을 분석해서 ‘윤종신스러운’ 새로운 곡을 쓸 수 있다면 어떠실 것 같아요? 그런 세상이 올까요?” 그러자 윤종신 님은 너무 태연하게, “제가 과거에 했던 행태를 (비슷한 음악 기법) 가진 것은 충분히 나올 것 같고... 곡은 만드는 방법은 이미 17~18세기 때부터 해왔던 것이기 때문에, 멜로디 같은 음악 작업은.. 근데 그 데이터를 활용하는데 그 활용 비용은 나한테 내겠죠? 물론 사람의 뇌도 또 그만큼 진화하겠죠!"
기존의 곡들을 가지고 비슷한 스타일의 새로운 글을 쓰기. 화가의 기존 그림 스타일을 분석해서 다른 그림에다가 이식해보기. 여태까지 트럼프가 쓴 트윗을 모아다가 트럼프가 썼을 법한 글을 생성하기. 이러한 AI의 활용방법이 최근에 굉장히 큰 주목을 받고 있습니다.
근데 우리가 여태까지 공부했던 언어 모델(Language Modelling)이 이러한 봇(?)을 만드는데 활용될 수 있다는거 아셨나요? 오늘은 지난주에 배운 Neural LM을 평가하는 방법을 먼저 짚어보고, 이 모델을 이용하여 어떻게 새로운 글을 생성할 수 있는지 배워보겠습니다.

LM은 어떻게 평가할까?
먼저 지난번에 어떠한 머신 러닝 모델이든 평가(evaluation)이 제일 중요합니다. 이 모델이 잘 학습되고 있는지 알 수 있어야 합니다. 만약 시험 점수를 받아 보지 않고 공부만 한다면 내가 현재 잘하고 있는지, 방법을 바꿔야 할지, 아니면 그대로 쭉 가야 할지 판단할 수 없겠죠? LM을 학습시킬 때도 똑같습니다.
LM은 perplexity라는 이름만 들어도 꽤 혼란스러운(?) evaluation metric을 학습에 쓰이지 않는 데이터 (held-out test data)에 계산하여 평가합니다. perplexity는 2^entropy로 계산하고 낮은 게 더 좋은 metric입니다. entropy는 information theory에서 나오는 개념인데, 불확실성이 클수록 커집니다. 화학 시간에 분자들의 활동이 많아지면 entropy가 높아진다고 배우는데 조금 다르면서도 비슷한 개념입니다. 다음 단어를 예측할 때 불확실성이 크다면 entropy가 높아집니다.
반대로 확실하다면 entropy가 낮아지겠죠. 이게 무슨 뜻일까요?
The king is married to the ____.
잘 학습된 LM이라면 다음 단어는 queen이 올 확률이 높게 예측되어야겠죠? 아마 softmax layer에서 queen라는 단어에 99% 이상의 probability score가 나와도 납득이 될 겁니다.
I like ____.
이 예시는 어떤가요? 다음 단어로 들어가도 될 단어들이 엄청나게 많죠? you, her, Mary 같이 사람을 지칭하는 단어일 수도 있고, pizza, drawing, game 등 사물이 들어갈 수도 있습니다. 이렇게 모호하기 때문에 불확실성이 높고, softmax layer에서도 각 단어에 확률을 나누어 비슷하면서도 낮은 probability score를 넣을 것입니다.
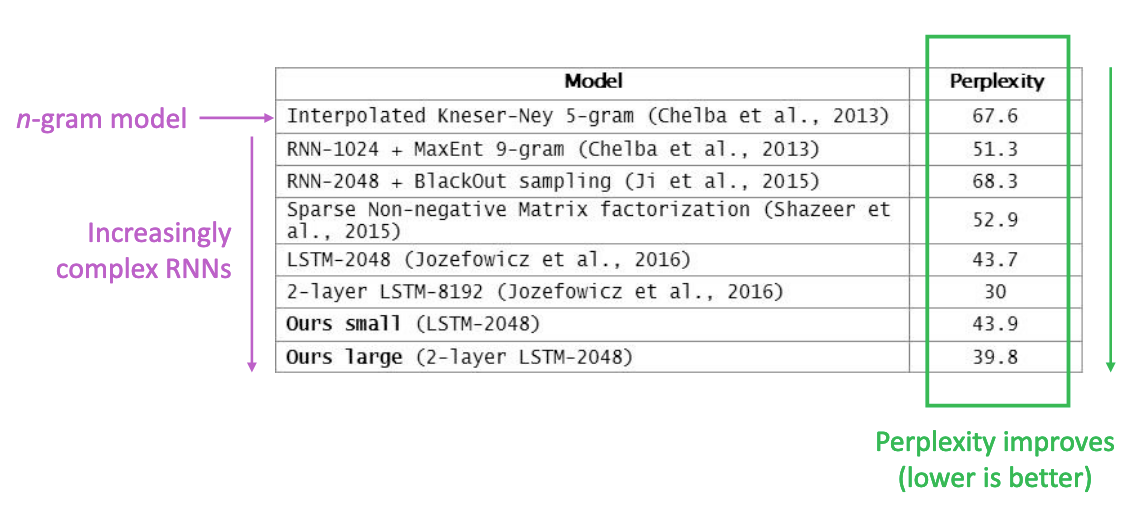
이처럼 LM을 평가할 때는, 비교적 entropy가 낮은 모델이 좋다, 즉 perplexity가 낮은 모델이라고 좋다고 통용적으로 쓰입니다. 아래 테이블을 보시면 n-gram LM부터 시작해서 그리고 점점 복잡하고 발전하는 RNN-based neural LM들의 perplexity가 줄어드는 것을 알 수 있습니다.
Text Generation
평가라는 매우 어렵고 복잡하지만 중요한 이야기를 해보았으니 본격적으로 재밌는 부분으로 넘어가보도록 하겠습니다.
언어 모델은 학습을 시킨 후 글을 새로 쓰는데 쓰일 수 있습니다. 여기서 재미난 점은 생성되는 글은 주어진 학습 데이터와 같지는 않지만 굉장히 유사해진다는 점입니다.
아래 예시부터 보시죠.

NLP 커뮤니티에서 꽤 유명한 이 블로그 글은 세익스피어 뿐만 아니라 위키피디아, Latex 논문, linux 코드 등 다양한 학습 데이터를 가지고 글을 생성해보고 분석도 해놓았습니다. 그리고 이를 이어서 오픈소스로 트럼프 봇까지 나왔는데요. 예시 몇 개 보시고 얘기해보죠.
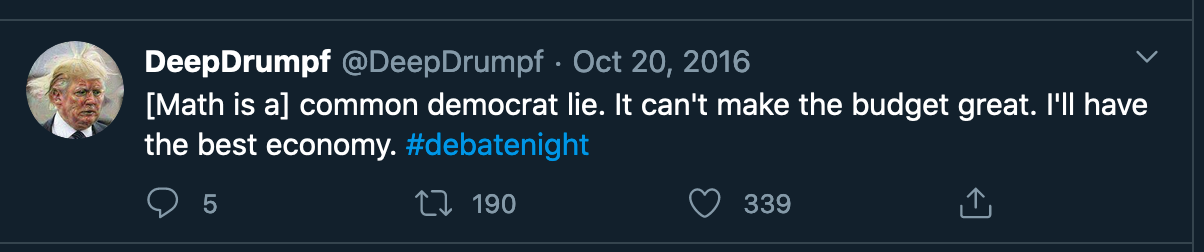

[Math is a], [I will bring jobs]는 처음에 주어진 단어들이고 그 이후의 단어들이 RNN 모델에 의해 생성된 글입니다. 트럼프가 지난 대선 때까지 트위터에 업로드한 글을 모아 학습 데이터를 만들어 RNN model을 학습시켰다고 하는데 말이 안되면서도 그럴듯해서 웃기네요 ㅎㅎ
도대체 어떻게 LM을 가지고 글을 생성해낼 수 있는 걸까요? 이는 LM이 확률 분포가 매번 생성되는 probabilistic model이라는 점을 이용한 것입니다. 지난 주에 공부한 Neural LM은 소프트맥스 함수(softmax function)를 통해 확률 점수(probability score)를 만들어주고 그걸 통해 다음 단어를 예측한다고 배웠죠? 바로 이 확률을 이용하여 샘플링(sampling)을 하는 것 입니다.

샘플링(Sampling)은 본질적으로 중학교 때 배운 철수와 영희의 빨간 구슬, 파란 구슬이 들어있는 주머니에서의 뽑기와 같습니다. 다른 점은 각 구슬에는 가능한 단어들이 쓰여져 있고, Softmax function이 매번 주머니에서 어떤 구슬을 집을지 확률을 결정한다는 것 입니다.
구슬을 하나 집을 때마다 한 단어가 생성되고, 그리고 단어가 추가됨에 따라 또 확률 분포(주머니)가 바뀝니다. 이렇게 구슬짚기를 반복하면 한 단어 한 단어씩 글이 생성되는 것입니다.
첫번째 트럼프봇 트윗을 예시로 든다면, [Math is a]라는 첫 세 단어가 주어졌을 때, 다음 단어로 “common”이 뽑혔고, 그리고 [Math is a common]이 주어졌을 때, 다음 단어로 “democrat”이 뽑힌 것입니다. 이렇게 글이 끝날 때까지 단어를 뽑습니다.
참 재밌죠? 근데 이건 뭐 몇 번 재미로 해보기 좋지, 무슨 실용성이 있을까 싶으신가요? 최근에 많은 이들을 놀라게 한 GPT 모델 역시 근본적으로는 이와 같은 방식으로 글을 생성하는 것입니다. 엄청나게 많은 데이터, 엄청나게 큰 모델로 더욱 더 정확하고 그럴듯하게 다음 단어를 예측하는 것일 뿐이죠.
하지만 GPT 같은 최신 모델을 공부하기 전에 더욱 더 많이 쓰이는 것부터 공부해보겠습니다.
바로 NLP의 가장 대표적인 킬러 어플리케이션인 기계 번역 (machine translation; MT)의 큰 혁신이 이런 text generation에서부터 시작되었습니다. 다음 주에는 MT라는 새로우면서도 매우 연관된 주제를 다루어보려고 합니다.

Reference
- Jurafsky & Martin, Chapter 9: Sequence Processing with Recurrent Networks, Speech and Language Processing
- Abigail See, Lecture 6: Language Models and Recurrent Neural Networks, Stanford CS224N: Natural Language Processing with Deep Learning.
- The unreasonable effectiveness of Recurrent Neural Networks, Andrej Karpathy Blog
- Aerin Kim, Perplexity Intuition (and its derivation), Medium blog



