

영어 공부를 열심히 하면서 살던 중 어느 순간 컴퓨터가 번역을 자동으로 해줄 수 있다는 소식을 들었었습니다. 검색 시장으로 세계를 장악하던 G사가 만든 translate라는 제품. 간단한 거부터 해보았습니다. 오, 좀 하네? 그럼 지금 읽고 있었던 영어 지문도 넣어보았습니다. 흠 이건 무슨 소리지. 뭔가 단어 하나하나는 말이 되는 거 같으면서도 전체적으로 뭔 소리인지 모르는 한국어 문장이 나왔습니다. 조금은 실망하고 컴퓨터를 끄고 다시 영어 공부를 하러 돌아갔습니다.
그렇게 몇 년이 흘렀습니다. 지금 G사의 Translate 그리고 국산 N사의 파파고를 보면 그때와는 비교도 할 수 없을 정도로 꽤나 높은 품질의 번역을 보장합니다. 당연히 아직 사람 번역가를 완벽하게 대체할 수 있다고는 할 수 있다고는 없겠지만, 이렇게 빠른 속도로 발전하는 것을 보면 조만간 영어 공부를 그만 해도 되는 걸까 싶기도 합니다 (번외: 구글 번역기만 있으면 되나요).
기계번역(Machine Translation; 이하 MT) 은 어떻게 이렇게 빠른 속도로 발전할 수 있었을까요? 앞으로는 어떻게 될까요? 저는 사실 NLP를 처음 접한 게 학부 4학년 때 MT 입문 수업을 들었을 때였습니다. 그 이후 저는 이 분야에 발을 들였습니다.
MT가 NLP에서 굉장히 중요한 분야인 이유는: 첫 째, NLP에서 가장 확실한 응용 분야이기 때문에, 둘째, MT에서 나온 새로운 모델, 방법론이 다른 NLP 분야에서 이용되어 더 큰 발전을 이루어냈다는 점입니다. 즉, 일종의 NLP의 선도 분야라고 할 수 있겠죠. 앞으로 몇 주간은 MT에 관해 글을 써보려고 합니다.
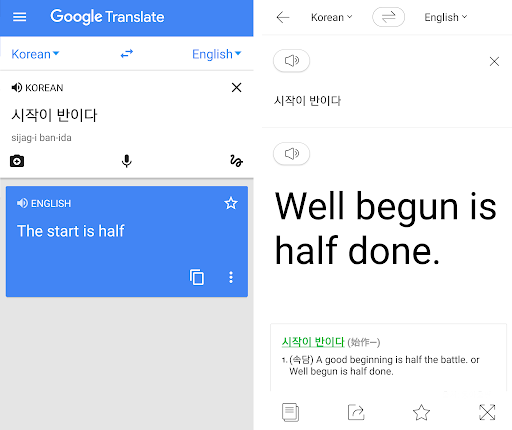

번역을 하기 위해 필요한 데이터: Parallel Corpora
우리 인간이 새로운 언어를 공부할 때, 당연히 모국어를 기준으로 새로운 언어를 배웁니다. 기존에 알던 나의 모국어(한국어)의 문장, 그리고 새로운 영어의 문장을 보고 공부를 합니다.
"야, 나 공부 정말 열심히 하고 있어." (source)
"Hey, I am studying very hard" (target)
이런 데이터를 우리는 parallel corpora라고 부릅니다. 그리고 Source에서 Target으로 번역을 한다고 표현하죠. 머신러닝을 사용하고 싶다면 데이터가 많아야 하는 것이 인지상정, 대부분의 MT 모델들은 이러한 두 문장이 쌍을 이룬 데이터가 많으면 많을수록 성능이 좋아지겠죠?
그런데 문제는 이러한 데이터는 만들기가 정말 비싸다는 점입니다. 아마 NLP 데이터 중에 가장 비싼 데이터 중 하나가 아닐까 싶습니다. 사람에게도 하나의 문장을 다른 언어로 완전히 번역하는 것은 꽤나 고급 기술이고, 그러한 기술을 가진 사람은 한정적이죠. 그렇기 때문에 MT 연구자들의 첫 고민은 이러한 데이터를 어디서 구하는 것입니다.
제가 홍콩과기대에서 수강한 MT 수업을 가르친 교수님은 90년대 초반 홍콩의 정치적인 특수성을 잘 이용하였습니다. 바로 홍콩 의회의 모든 문서는 영어와 중국어 두 버젼이 쓰여야 했기에, 따로 돈을 들이지 않아도 쓸 수 있던 parallel corpora였습니다. 이런 식으로 EU 정부, 캐나다 퀘벡 주의 문서 등 공문서를 가지고 데이터를 모으는 경우가 많았었습니다. 또한, 책의 번역본을 사용하는 경우도 있었고요.
현재는 인터넷 세상이 되었기 때문에 조금은 수월해졌습니다. TED 같이 강연들을 비영리로 제공하는 단체들은 강연의 번역 자막 역시 무료로 공개하기 때문에 연구자들이 많이 쓰고 있고, 유튜브 자막을 비롯해서 인터넷의 다양한 곳에서 데이터를 모을 수도 있을 것 같습니다. 얼마 전 상장한 한국의 스타트업인 Flitto처럼 crowdsourcing으로 데이터를 모으는 방법도 있겠네요. 연구자들을 위해서는 이미 오픈소스로 공개된 데이터도 꽤 있습니다.
문장을 좀 잘라서 생각해보자: Phrase-based MT
우리가 영어 공부를 할 때 많이 익히는게 있죠. 바로 어휘(vocabulary), 사전(dictionary), 그리고 구절(phrase)!
study: 공부, language: 언어, machine: 기계
according to: ~에 의하면, play with: ~와 놀다
MT의 시초는 이렇게 문장을 구절 여러 개로 나누어 각각을 번역하는 식의 접근을 하였습니다. 이러한 접근 방식을 Phrase-based Machine Translation이라고 합니다. 이는 번역을 단계별로 접근한 방법론이라고 볼 수 있습니다. 간단하게 정리를 하자면 대략적으로 이런 과정을 거칩니다.
(1) 구절(phrase) 또는 단어(word) 간 대응 되는 사전(dictionary)을 만든다.
(2) 사전에 수록된 어휘(vocabulary)에 따라 문장을 나눈다.
(3) 나눈 부분을 번역한 후 순서를 알맞게 바꿔준다.
일단 (1) 과정부터 보자면, 우리가 언어를 공부할 때 단어나 숙어를 기계적으로 하나하나 암기하는 방법 뿐만 아니라 MT 모델이 데이터를 통해 통계학적인 접근을 해 dictionary를 자동으로 생성하는 방식으로 합니다. 모든 단어나 구절의 일대일 대응을 찾는 것은 정말 많은 노동이 필요한 작업이기 때문이죠.
Parallel corpora가 있기 때문에 같은 단어 또는 구절이 여러 문장에 반복되어 같이 나온다면 같은 뜻이라고 유추할 수 있습니다.
예를 들어, "공부"라는 한국어 단어가 source 문장에 나타나고, "study"라는 영어 단어와 여러 문장에 걸쳐 같이 나온다면, "공부 = study"라는 것을 자동으로 유추할 수 있습니다. 이 과정에서 이러한 관계를 1:1 매칭이 아닌 (한 영어 단어에 대응되는 여러 한국어 단어가 있을 수 있기에) 확률 점수로 저장합니다. (ex. play = 놀다 80%; 연극 20%)
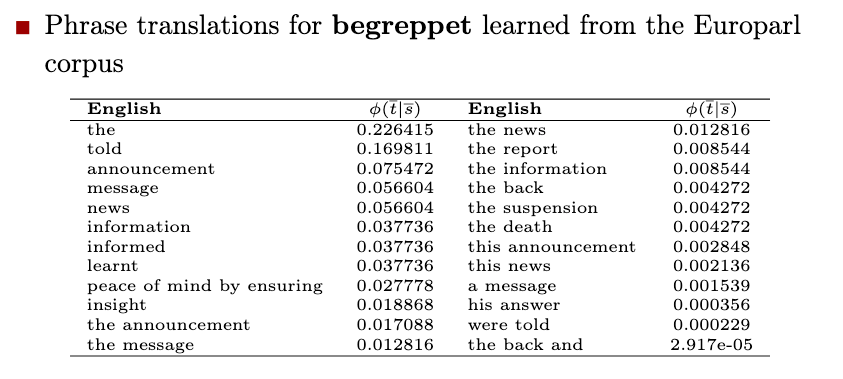
(2) 과정에서는 위와 같은 (1)에 배운 dictionary를 사용해 문장을 구절로 나눕니다. 단어들의 빈도수를 이용해 통계 모델을 만든다면 "according to", "New York" 같이 자주 같이 나오는 n-gram들은 한 개의 구절로 묶어 학습할 수 있습니다.
"나는 너와 라면을 먹었다" =>"(나는) (너와) (라면을) (먹었다)"
(나는) (너와) (라면을) (먹었다)" => "(I) (with you) (ramen) (eat)"
만약 여기까지만 한다면 이러한 불완전한 번역으로 끝나겠죠? 이는 바로 언어마다 주어 (subject)와 동사 (verb), 그리고 목적어 (object)의 순서가 다르기 때문입니다. 이를 어순이라고 하는데, 세상 언어에는 한국어 같은 SOV형 또는 영어 같은 SVO형이 대부분이지만 아닌 언어들도 간혹 가다 있습니다.
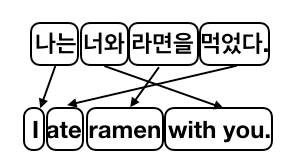
이걸 Word alignment라고 하는데요. 이 순서 역시 hidden markov model (HMM) 같은 확률 모델로 만들어서 학습 후 virterbi algorithm 등의 방법으로 순서를 찾아냅니다.
여기서 좀 더 나아가면 의존 구조 분석(dependency parsing)이 사용되기도 합니다. 어떤 부분이 주어고, 동사고, 목적어고, 그 관계가 어떻게 되고 등등 문장을 분석하는 것인데요. 만약 단어가 늘어날수록 가능한 순서가 너무나 빠르게 (단순하게 모든 조합을 생각하면 factorial급으로) 늘어나기 때문에, dependency label을 가지고 조금은 쉽고 효율적으로 순서를 찾아보려는 방법입니다.
마치 우리가 영어 문장 작문을 할 때, "여기는 동사가 나와야 되고 다음은 목적어가 오는게 맞겠지"라고 생각하면서 쓰는 것처럼 말이죠. 문제는 이러한 분석을 자동으로 하려면 별도의 dependency parsing 모델이 필요하다는 점인데 그건 아예 다른 주제라 나중 글에서 다뤄보겠습니다.
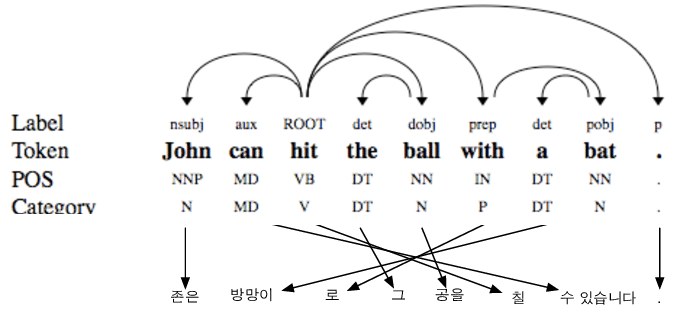
뭔가 상당히 복잡하고 어렵습니다. 마치 난 영문법 책이랑 영한사전을 붙들고 열심히 공부했는데, 막상 작문을 하려니까 생각할게 너무나 많고 한 단어 한 단어 번역하다 보니 순서도 틀릴 거 같아 무서워 한 마디도 못하는 나 자신을 보는 것 같습니다.
근데 미국에서 어렸을 때 유학 갔다 온 사촌 동생이 명절 때 오더니 제 책을 보고 술술 문장을 번역합니다. 어른들은 역시 조기 유학이 답이라며 박수를 치십니다. 동생을 데리고 방에 들어가 어떻게 했냐고 물어봅니다. 그랬더니 동생이 "난 그냥 평소에 말하는 대로 한 건데?"라 합니다. 주어가 뭐고 목적어가 뭔지 공부한 적도 없다고 합니다. 저는 울면서 문법책을 창문 밖으로 던집니다.
네, 맞습니다. 그 사촌 동생이 바로 딥러닝을 이용한 neural machine translation입니다. 갑자기 G사, N사의 기계 번역 서비스가 비약적으로 발전됐다고 느끼셨던 날이 있었다 했죠? 그게 다 phrase-based MT에서 neural MT로 갈아치워 졌기 때문입니다. 다음 주에 이어서 쓰도록 하겠습니다!

Reference
- Christopher Manning, NLP CS224n Lecture 4: Phrase-Based Machine Translation
- Dekai Wu, Introduction to Natural Language Processing, HKUST 2016 from my memories.
