Week 28 - BERT만 잘 써먹어도 최고가 될 수 있다?


NLP를 공부하시는 분들 중에 GPT나 BERT 같이 최근에 나온 무지막지하게 큰 언어 모델을 처음 공부하면 대부분 반응이 이렇습니다.
"와 쩐다... 성능이 엄청나네." (감탄)
"이거 뭐 이 정도면 NLP에서 더 할 수 있는게 있나.." (우울)
"스케일도 대단하네. 데이터도 미친듯이 많고, 몇십 억씩 들여야 이런 모델이 학습되네." (또 감탄)
"나/우리는 그렇게 쓸 돈도 데이터도 없는데. 뭐 이길 수가 없네." (또 우울)
특히 NLP 연구를 하는 분들이 공감을 많이 하실텐데, 그만큼 최근 몇 년간 NLP 연구의 트렌드는 "더 많이, 더 크게"였던 것도 사실입니다. 그래도 다행스러운 점은 이러한 모델들의 원리가 논문으로 공개가 되고, 심지어 몇십 억을 들여 학습한 모델을 오픈소스로 공개하기도 한다는 점입니다.
"거인의 어깨 위에 올라선 난쟁이는 거인보다 더 멀리 볼 수 있다"
지난 주 우리는 남의 덕을 보고 살자는 철학을 가진 전이 학습(Transfer Learning)에 대해서 배웠습니다. 오늘은 BERT를 잘 활용해서 구글이라는 거인의 어깨에 설 수 있는 방법에 대해 공부해보겠습니다.

BERT로 풀 수 있는 문제 유형
BERT 원 논문에서는 가장 대표적인 NLP 문제 11개에서 역대급 성능을 보여줍니다 (아마 2020년 지금까지의 후속 연구들까지 살펴보면 훨씬 더 다양한 NLP문제에 BERT가 쓰였을 것입니다).
저자들은 이 모델이 쓰일 수 있는 문제의 유형를 4가지로 나누어 소개합니다.
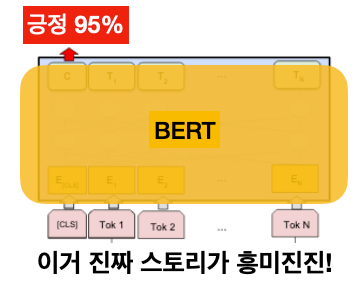
1) 문장 한 개 분류(Single Sentence Classification)
문장이 주어졌을 때 어떠한 라벨인지 예측하는 문제입니다. 전에 잠깐 다루었던 스팸 메일 찾기, 문서 카테고리 분류, 감성 분류 등이 이 부류의 문제에 속합니다.
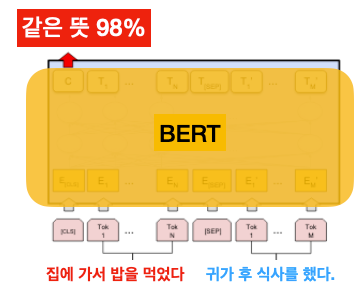
2) 문장 두 개의 관계 분류(Sentence Pair Classification)
문장 두 개가 주어졌을 때, 라벨을 예측하는 문제입니다. 대표적인 문제는 의역 예측(paraphrase detection)인데, 아래 예시에 나온 두 문장처럼 다른 단어가 쓰였지만 같은 뜻을 가지고 있는지 아닌지 예측할 수 있습니다. 이러한 기술은 상품 문의에서 같은 글들을 묶어 주는 등의 응용 사례로 쓰일 수 있겠죠. 아니면 두 문장이 주어졌을 때 서로의 주장을 보완하는지(entailment), 상충하는지(contradiction), 중립(neutral)인지 예측할 수도 있습니다.
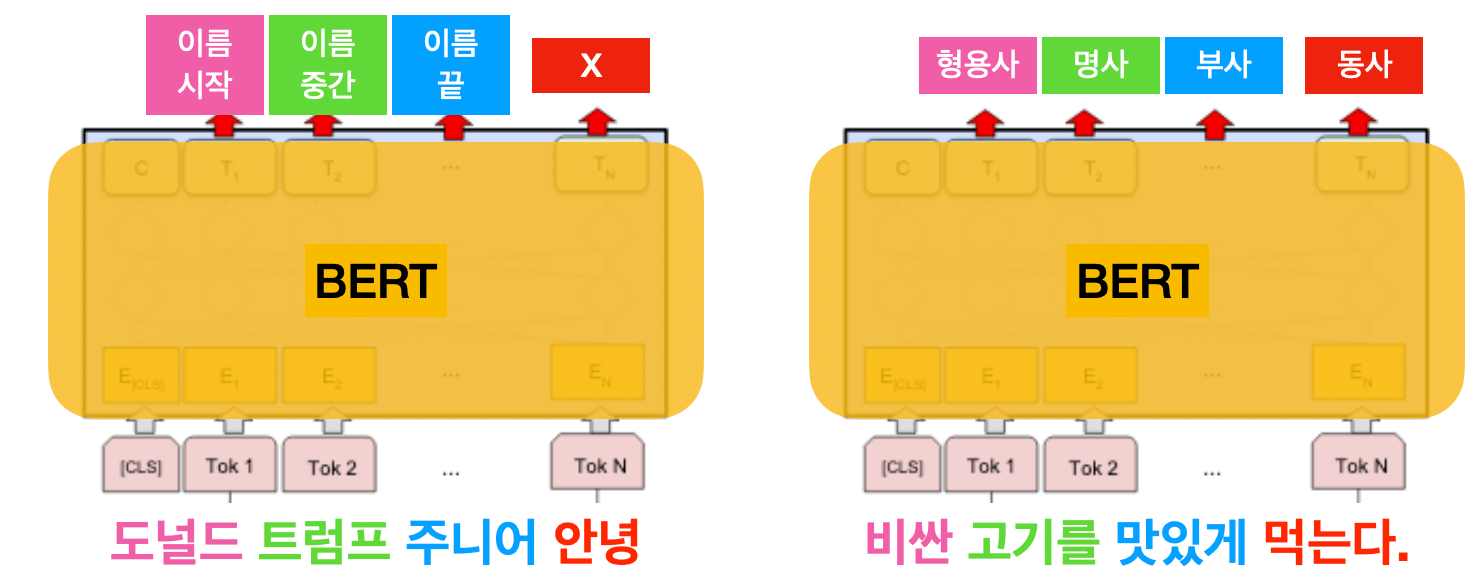
3) 문장 내 단어 라벨링(Single Sentence Tagging Task)
한 문장 내 들어있는 단어에 대한 레이블을 예측하는 문제입니다. 대표적인 예는 개체명 인식(named entity recognition)인데요. 아래 예시와 같이 문장이 주어졌을 때, 이름의 시작/중간/끝을 라벨로 예측을 합니다. 이러한 머신러닝 모델을 학습시키면 위키피디아 같은 데이터에 없는 사람/조직 이름도 인식할 수 있습니다. 또다른 대표적인 문제는 품사 태깅(Part-of-Speech Tagging)이라고 해서 문장의 문법품사를 예측하는 문제입니다.
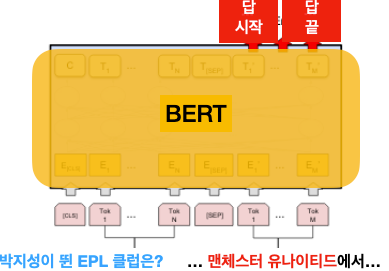
4) 묻고 답하기(Quesiton & Answering)
BERT에게 질문과 본문이 주어졌을 때, 본문 속에 답이 있는 부분을 예측합니다. 예를 들어, 박지성의 위키피디아 페이지와 질문인 "박지성이 뛴 EPL 클럽은?"이 주어졌을 때, 본문 중에 "... PSV 에인트호번과 잉글랜드 프리미어리그의 맨체스터 유나이티드, 퀸스 파크 레인저스에서 활동하였다...." 밑줄이 그어진 부분을 예측하는 문제입니다.
BERT에 쓰이는 Transfer Learning(TL) 기법 2가지
여러분이 풀고자 하는 문제가 이 네 가지 유형 중의 한 개인가요? 그리고 어느 정도의 데이터를 확보하셨나요? 그러면 일단 BERT를 활용해보는 것을 추천합니다.
BERT를 써먹는다는 것은 무슨 뜻일까요? 바로 지난주에 배운 전이 학습(TL)을 이용한다는 것인데요. 이미 엄청나게 많은 텍스트 데이터를 통해 학습하여 BERT라는 모델에 축약된 지식을 내가 가진 적은 양의 데이터에다가 적용한다는 것 입니다. 대표적으로 두 가지 TL 기법이 사용됩니다.
1) 피쳐 뽑기(Feature Extraction)
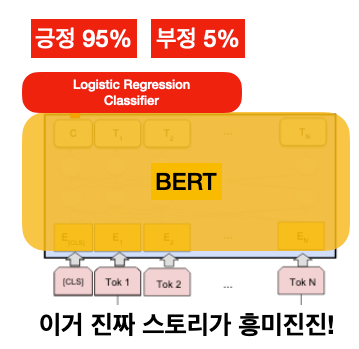
BERT를 위 그림처럼 블랙박스 함수라고 생각하고 BERT가 내뱉는 vector를 다른 머신러닝 모델의 input으로 씁니다. 마치 우리가 Bag-of-Word Vector로 Input으로 쓰는 것처럼요. 아주 간단한 모델인 로직 스틱 회귀(Logistic Regression)를 써도 되고, 또 다른 딥러닝 모델을 써도 괜찮습니다. 이 경우에는 BERT의 파라미터(노란색)는 고정되어 변하지 않고, 빨간색으로 얹힌 새 모델만 가진 데이터를 가지고 학습이 됩니다.
2) 재학습(Finetuning)
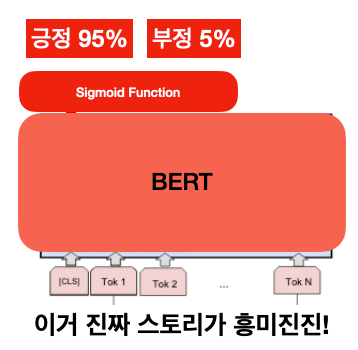
이 방식은 데이터가 조금 더 많이 있을 때 쓰면 좋은 방식입니다. BERT의 파라미터 역시 주어진 데이터를 통해 재학습 시키는 것인데, BERT 뿐만 아니라 그전부터 다양한 머신러닝 문제에서 TL의 힘을 빌릴 때 많이 쓰이는 기법입니다.
여기서 핵심은 아무런 머신러닝 모델을 붙일 수 있는 게 아니라 Sigmoid function이나 multi-layer perceptron(MLP)처럼 Back-propagation이 가능해야 합니다. 안 그러면 같은 cost function으로 기존 BERT 모델이 재학습되지 않기 때문입니다. (이 부분에 대한 이해를 좀 더 하려면 Reference를 참고하시길 바랍니다)
오늘은 BERT를 활용하는 방법에 대해서 배웠습니다. 가장 중요한 점은 내가 풀려는 문제가 이 모델에 적합한지를 파악하는 것, 적은 양이라도 어느 정도의 데이터를 확보하는 것, 그리고 어떻게 그 데이터에 BERT를 적용할 것인지 알아내는 것입니다. BERT가 정말 많은 NLP 문제들에 강력한 성능을 보여주어 유명해졌지만 만능 열쇠는 아니라는 점을 알아야 합니다.
BERT의 가장 큰 약점 중의 하나는 다른 LM처럼 텍스트를 생성(Text Generation)하기 힘들다는 점입니다. 왜냐면 다음 단어가 아니라 중간에 있는 단어를 예측하는 방식으로 학습이 되었기 때문인데요. 2020년에 이 방면의 괴물로 나타난 모델이 있습니다. 바로 GPT입니다. BERT의 강력한 사촌 GPT, 다음 주에 다루어보도록 하겠습니다.
Reference
- Develin et al., 2018, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- NLP in Korean, How NLP Cracked Transfer Learning (한국어 심화 설명)




