Week 13 - 언어를 모델링한다? Language Model Basics


친구와 말을 하다 보면 특정한 단어가 생각나지 않을 때가 있지요.
"내가 주말에 카페에서 공부를 하고 있는데... 그 누구지.. 커피....."
"바리스타?"
"아 응, 바리스타가 말이야~"
이렇게 친구가 내가 생각하는 단어를 잡아줄 때 민망하기도 하면서 한편으로는 내 말을 잘 듣고 있구나 하는 느낌이 듭니다. 새로운 언어로 말할 때는 더더욱 다음 말해야 하는 단어가 무엇일지 생각하기 힘들죠. 내가 선택한 단어가 맞는 뜻인지, 이렇게 말해야 문법적으로 맞는지, 어순이 맞는지 등, 고려해야 할 것이 많습니다.
언어를 이해한다는 것은 무엇일까요. 철학적으로 들어갈 수 있지만 가장 기본이 되는 것은 위 예시처럼 다음 단어가 무엇인지 잘 생각하고 선택하는 게 아닐까 싶습니다. 한 언어에 능숙해지면 어떤 문장이 주어졌을 때 이게 말이 되는지 안되는지, 문법적으로 맞는지 (비록 문법은 의미 전달에 가장 중요한 건 아닙니다만) 등 딱 보고 자연스러운지 알 수 있습니다.
이번 주부터 몇 주간은 NLP에서 가장 가장 중요하다고 백번 강조해도 부족하지 않은 language modeling (LM)에 대해 알아보겠습니다.

Likeliness - 그럴듯함?
Likeliness를 직역하면 "그럴듯하다" 정도로 이해할 수 있습니다. 누가 어떤 일이 일어났다고 설명해줄 때, 우리는 "그럴듯하네." 또는 "말도 안 돼"라고 반응하고는 합니다. 우리가 문장을 읽을 때도 그렇습니다. 딱 읽고 자연스러운 문장은 "그럴 듯"하기에 술술 읽힙니다. 조금이라도 이상한 단어가 쓰이거나 문법이 틀리다면 우리는 바로 부자연스러움을 느낍니다.
이렇게 우리는 뇌에 이미 LM을 구축해놓았습니다. 몇십 년 동안 읽어온 책, 나눈 대화, 들고 본 TV, 영상 등의 매체를 통해 엄청나게 많은 데이터를 처리하며 하나의 언어에 대한 감과 지식을 쌓아왔던 것입니다. 그렇기 때문에 국어/논술 시험을 잘 보려면 독서를 많이 하라고는 합니다. 데이터가 많을수록 한 사람의 LM은 더 우수해질 테니깐요.
하지만 어떤 문장이 주어졌을 때 "얼마나 그럴듯한가요, 숫자로 표현해보세요."라고 한다면 계산할 수 있을까요? 아무래도 힘들겠죠. 우리의 뇌는 어떻게든 열심히 계산을 하고 있겠지만, 우리가 직접적으로 숫자를 생각해내기는 힘들 것입니다. 다만 분명한 건 그 숫자는 존재합니다. 왜냐면 두 문장이 주어졌을 때 어떤 게 더 그럴듯하냐고 물어보면 비교할 수 있기 때문이죠.
나는 밥을 먹는다!
나는 밥을 읽는다?
통계학 기초를 공부하신 분들은 likeliness (가능도) 라는 용어가 낯설지 않으셨을 겁니다. 확률과 비슷하지만 조금은 다른 가능도는 말 그대로 얼마나 가능한지의 정도를 나타낸 숫자입니다. 네, 맞습니다. 인간의 뇌에 자연스럽게 쌓아 올리는 LM을 모방하려면 통계학적인 접근을 해야 합니다. 이렇게 statistical langauge modeling을 소개하려고 합니다.

문장은 단어의 연속
Week 2에서는 NLP에서 어떻게 문장을 이해하고 표현하는지에 대해 배웠었습니다. 단어들의 하나의 문장을 구성한다고 보고, 하나의 가방 또는 조합으로 표현하여 머신 러닝 모델에 넣는다고 배웠습니다. LM 역시 이와 크게 다르지 않습니다. 문장을 단어의 연속으로 보는 것입니다.
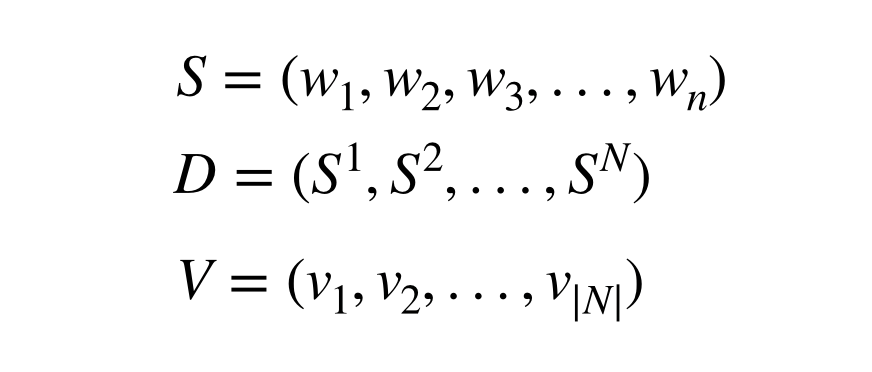
S (Sentence)는 단어 n개가 들어가 연속으로 들어 있는 리스트, w는 문장에 들어가 있는 단어, D는 N개의 문장이 포함된 데이터, 그리고 V는 가능한 모든 단어들의 리스트인 vocabulary입니다. Vocabulary라는 개념을 다시 리뷰하시려면 Week 1을 참고하시길 바랍니다.
한 문장이 그럴듯함은 어떻게 계산할 수 있을까요? 바로 단어들의 joint probability (동시 확률분포)를 계산합니다. 4개의 단어가 있다면 4개가 함께 발생할 확률을 계산하는 것이죠.
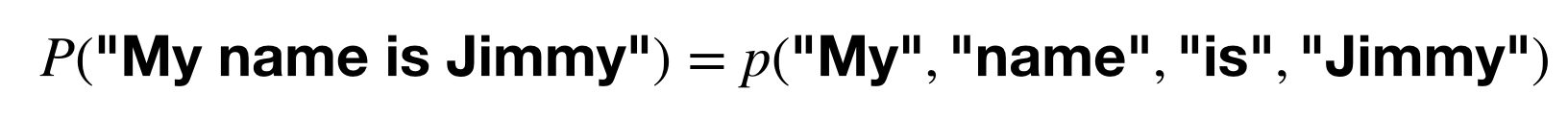
이걸 어떻게 계산하냐고요? 바로 가지고 있는 데이터로부터 계산하는 것입니다. 우리 인간이 평생 읽고 듣고 보면서 모은 데이터를 통해 단어에 대한 감을 익히듯이, NLP에서는 데이터(또는 corpus라고 부름)를 통해 language model을 학습합니다. 다행히도 컴퓨터는 지치지 않고 몇 분만에 수천 만, 수 억 개의 데이터를 읽고는 합니다.
이렇게 LM의 기본 개념을 알아보았습니다. 앞으로 몇 주간은 LM은 어떻게 학습되는지 좀 더 구체적으로 알아보고, LM이 어떤 분야로 응용이 되는지, 매우 유명해진 친구들 ELMO & BERT가 LM과 무슨 상관인지 천천히 설명해보도록 하겠습니다.

Reference
- Kyunghyun Cho, Chapter 5: Neural Language Models, Natural Language Understanding with Distributed Representation
- https://en.wikipedia.org/wiki/Language_model



