

사람이 많은 카페에서 친구와 같이 얘기를 하다가 잠깐 멈추면 주변이 얼마나 시끄러운지 그제야 깨닫게 되는 때가 종종 있습니다. 천장에서 나오는 음악, 양 옆에서 각자의 대화를 큰소리로 즐겁게 나누는 다른 사람들, 바리스타가 커피를 내리면서 나는 소음 등 정말 내가 어떻게 친구 말을 알아듣고 있었나 싶을 때도 있습니다.
이렇게 우리는 웬만한 소음 환경에서는 다른 사람의 말을 잘 알아들을 수 있는 능력을 가지고 있습니다. 이게 생각보다 대단한 능력인데, 저는 정말 말귀 못 알아듣는 사오정 같은 친구와 술집에서 얘기할 때, 그리고 키보드 치기 귀찮아 음성인식을 이용해 카톡을 쓸 때 더더욱 그렇게 느끼고는 합니다.
들리는 소리를 우리가 이해할 수 있는 언어, 즉 문자 텍스트 형식으로 바꾸는 기술을 자동 음성 인식 (Automatic Speech Recognition; ASR)이라고 합니다. 요즘은 구글 어시스턴트 같은 인공지능 비서 또는 유튜브에 나오는 자동 자막 생성 같은 제품을 통해 이미 많이 접해보셨을 거라 생각합니다. 이 ASR 기술이 우리가 지난 몇 주간 배운 언어 모델(LM)의 가장 성공적인 응용이라고 하는데, 어떤 원리로 돌아가는 건지 궁금하시지 않나요? 오늘 이 글에서 음성인식의 원리를 최대한 알기 쉽게 풀어써보려고 합니다.

Noisy Channel Model이란?
일단 우리는 Noisy channel model이라는 개념을 짚고 넘어가야 합니다. 아래 그림과 같이 message를 보내는 사람(sender)과 받는 사람(receiver)이 있을 때, 중간에 message가 어떠한 noise (소음) 때문에 변형되는 경우를 봅시다.
이는 신호 처리 (signal processing)에서 자주 쓰이는 모델인데요. 전화선 같은 통신 채널을 통해 어떤 신호를 보낼 때 중간에 여러 소음들 때문에 원본과 똑같은 메시지를 다른 쪽에서 받는 것은 불가능합니다. 그렇기 때문에 최대한 소음을 제거해 원본이 어떤 내용인지 알아내려고 합니다. 이 과정을 decoding (해독)이라고 부릅니다.
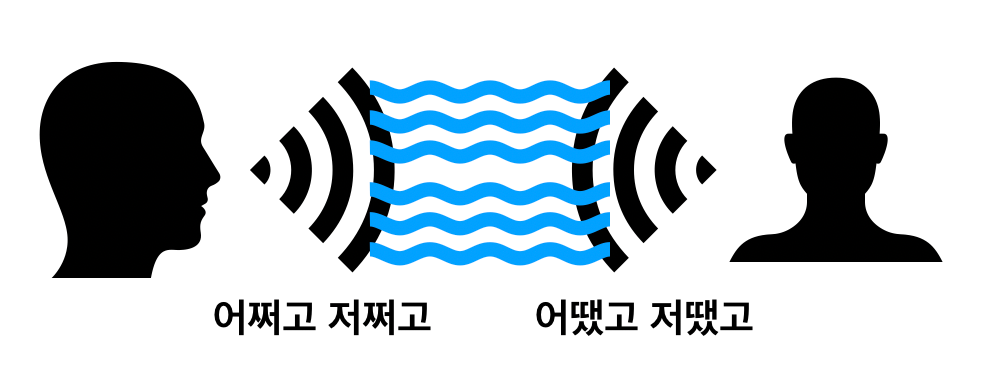
예를 들어, 말하는 사람 (sender)는 "어쩌고 저쩌고"라는 얘기 했는데, 주변 소음 때문에 듣는 사람 (receiver)는 "어땠고 저땟고"라고 알아듣습니다. 듣는 사람은 어찌 됐든 최선을 다해 원본과 가장 가까운 메시지를 decoding 해내려고 하는 거죠.
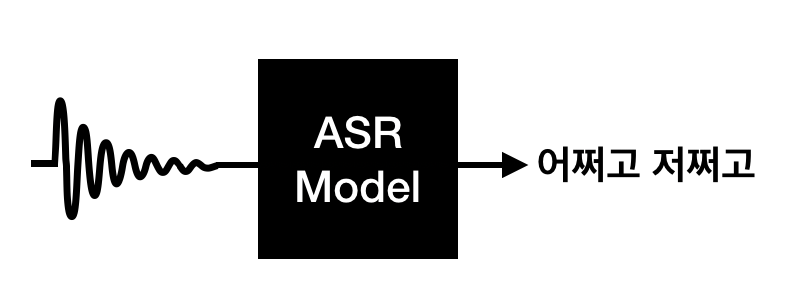
ASR 기술은 이 noisy channel model을 기반으로 음성(sound signal)을 우리가 읽을 수 있는 텍스트(text)로 변환할 수 있는 모델을 만드는 것입니다. 어떻게요? 역시 통계학 모델이 빠질 수 없겠죠!
또 나왔다, Bayes' Theorem!
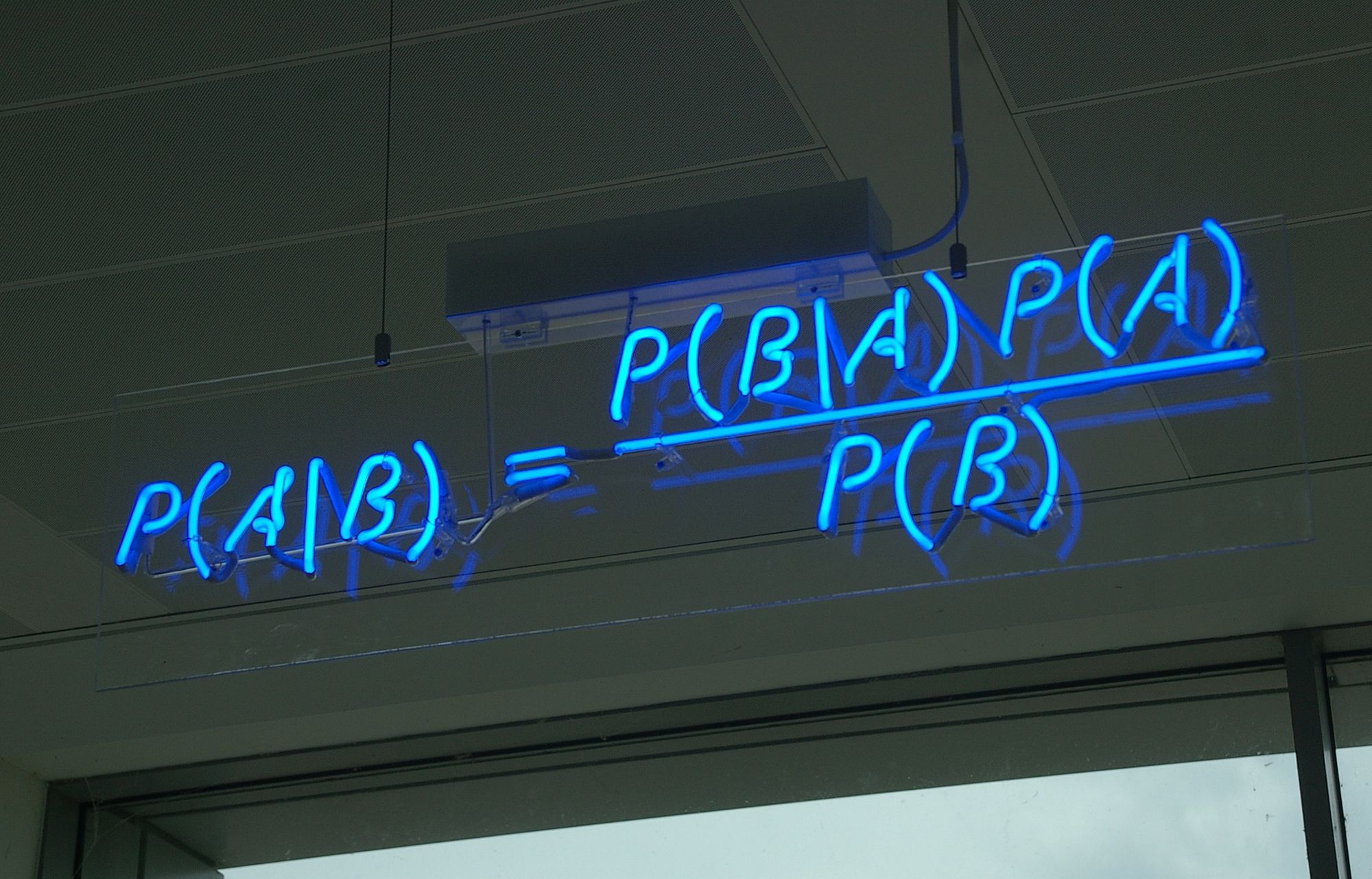
ASR 모델은 bayes' theorem을 통해 두 가지 모델로 분리되어 이루어져 있습니다. 하나는 소리 모델 (acoustic model), 그리고 언어 모델 (language model).
ASR 모델로 들어오는 소리를 X, 이에 해독할 텍스트를 W라고 해봅시다. 근데 우리는 W가 무엇인지 정확하게 알 수 없기 때문에 확률 모델로 표현해야 합니다. 이를 간단한 conditional probability 수식으로 표현할 수 있습니다.
P(W|X) : 소리 X가 주어졌을 때, 텍스트 W는 무엇인가.
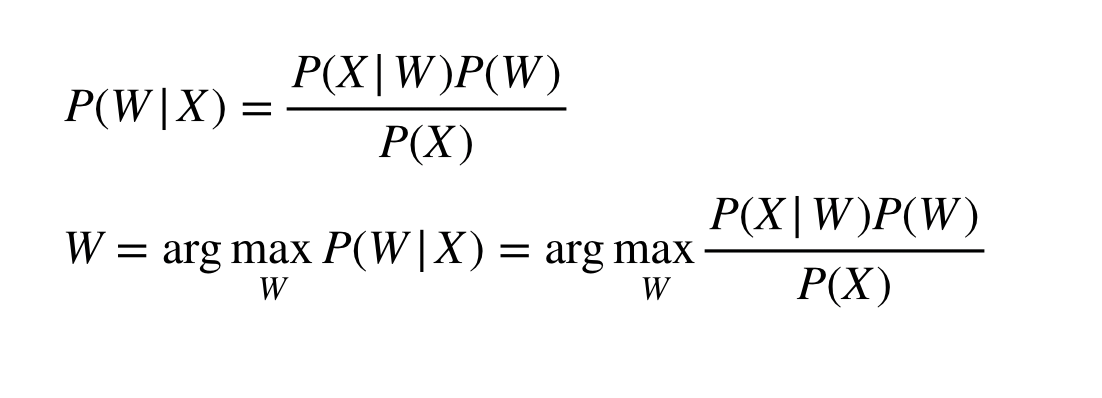
근데 잘 생각해보면 분모에 들어가는 P(X)는 W와 상관이 없기 때문에 argmax에서는 버려져도 상관이 없죠. 그럼 수식이 더 단순해집니다.
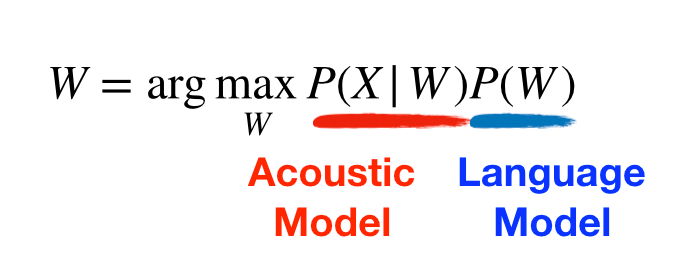
P(X|W) : 텍스트 W가 주어졌을 때, 소리 X는 무엇인가.
P(W) : 텍스트 W의 확률
Acoustic Model (AM)은 아직 뭔지 잘 모르겠지만, P(W)은 텍스트 W의 확률이라고 합니다. 네, 이 부분이 우리가 지난 몇 주간 공부한 문장의 그럴듯함을 학습하는 LM이 맞습니다!
이번 글에는 ASR 모델의 기본 작동 원리에 대해서 공부해보았습니다. 핵심은 Bayes' theorem을 이용하여 ASR 모델을 AM과 LM으로 나누어 학습시킬 수 있다는 점입니다. LM 같은 경우에는 엄청나게 많은 텍스트만 있으면 되기 때문에 따로 정확한 모델을 학습시킬 수 있어서 ASR의 성능을 향상하는데 큰 역할을 한다고 합니다!
다음 글에는 Acoustic Model에 대해서 좀 더 설명하고, ASR 모델은 어떻게 학습되는 것인지, 어떤 기준을 가지고 평가가 되는지 등을 알아보도록 하겠습니다!

Reference
- Automatic Speech Recognition: An Overview. Julia Hirschberg, CS 4706, Columbia University
- An Overview of Modern Speech Recognition, Xuedong Huang and Li Deng, Microsoft Corporation, 2010