

2020년 봉준호 감독의 기생충이 아카데미를 수상하면서 함께 주목을 받았던 사람이 바로 그의 동시 통역가 샤론 최 씨인데요. 기계번역이 아무리 좋아도 당장은 이런 고퀄리티의 통역가는 대체될 수 없겠구나라고 할 정도로 훌륭한 실력을 선보였습니다. 저는 세 가지 부분에서 그녀의 통역이 굉장했다고 느꼈는데요:
(1) 영화 업계 (충무로/할리우드)에서 쓰이는 전문 용어 (jargon) 들을 자유자재로
(2) 한국식 유머를 영어로도 웃을 수 있게 즉석에서 튜닝
(3) 자주 길어지는 감독과 배우들의 발언들을 전부 기억한 후 놓치지 않고 번역

기계 번역은 이 세 가지를 잘할 수 있을까요?
(1) 포인트는 데이터로 어느 정도 해결할 수 있을 것 같습니다. 전문 용어들이 많이 들어가는 corpus가 있다면 충분히 그 관계를 배울 수 있지요. (2) 포인트는 데이터가 많더라도 너무 어려운 부분입니다. 유머의 본질을 이해하고 창의적으로 다른 언어로 재해석을 해야 하는 부분이거든요. NLP에서 유머라는 주제는 은근 활발하게 등장하지만 매우 고난의도의 문제입니다. 거기다가 번역까지 해야 한다면 AI에게도 정말 미친 숙제입니다. 그만큼 샤론 최 통역가님의 언변은 빛이 납니다.
그렇다면 (3) 포인트는 어떨까요? 컴퓨터는 용량이 큰 하드 디스크나 RAM이 있으니깐 문제없지 않냐고요? 그게 그렇게 단순하지가 않습니다.
오늘은 기계 번역 모델이 어떻게 긴 문장을 효과적으로 번역할 수 있는지에 대해 공부해보겠습니다.

내 머릿속의 지우개, RNN
지난주에 배운 seq2seq 모델은 두 개의 RNN이 encoder-decoder를 이룬 모델입니다. RNN을 처음 소개했을 때부터 말씀드렸듯이 RNN이라고 해도 무제한의 긴 기억을 가지고 있는 게 아닙니다. 이를 해결하기 위해 LSTM 같은 모델도 나왔고, 모델 크기를 더 늘린다거나 gradient clipping 같은 학습 시 대처하는 방법도 있습니다.
근데 문제는 아무리 애를 써도 이렇게 긴 문장을 번역하려고 할 때 seq2seq의 기억력에 문제가 생긴다는 점입니다.
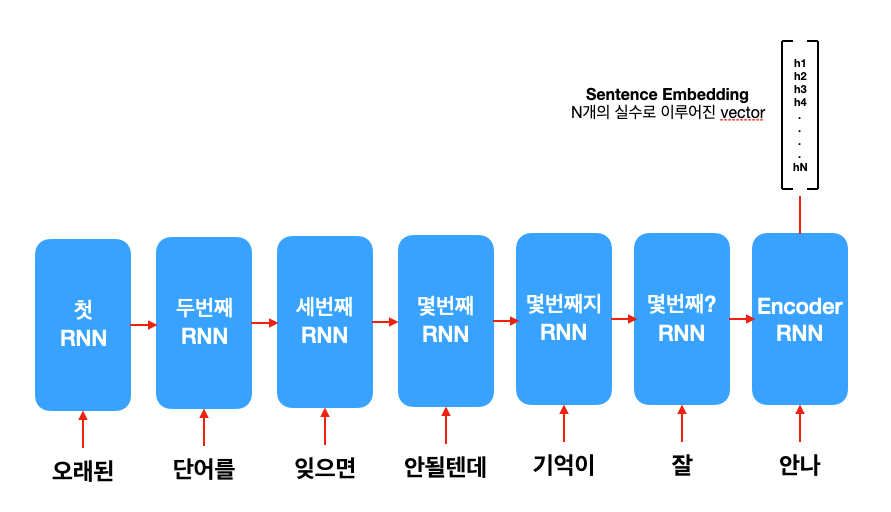
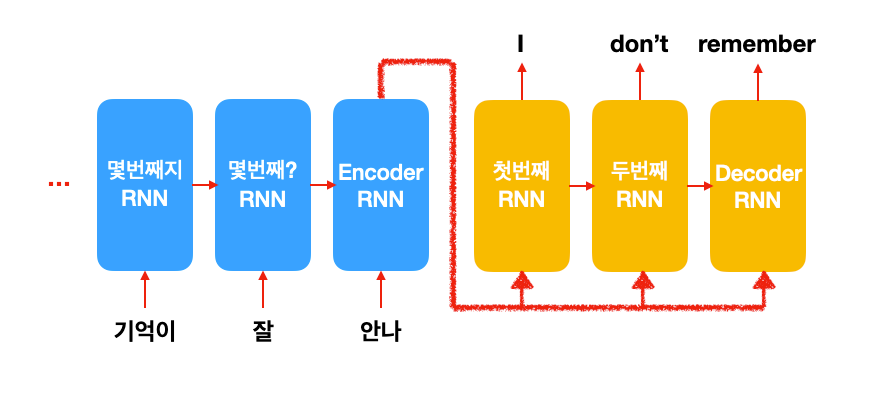
seq2seq의 input 문장을 읽는 encoder는 마지막에 하나의 sentence embedding을 만들어냅니다. 결국 여기에 input 문장에 모든 정보가 들어가 있는 것이죠. 이걸 받아서 decoder RNN이 번역 문장을 한 단어 한 단어 생성하기 시작합니다. 근데 문장이 길어지면 앞에 있는 단어들이 무시 (가 아니라 까먹은 거...) 된다는 것입니다.
아무래도 한 개의 문장을 한 개의 sentence embedding으로 구겨 넣으려니까 탈이 나는 것 같습니다. 물론 모델 크기를 늘린다면 문제가 조금은 해결되겠지만 매우 비효율적이겠지요.
어딜 바라봐, 나만 바라봐: Attention Mechanism
그래서 해결책으로 나온 것이 Attention Mechanism입니다. 문장을 한 개의 vector로 쑤셔 넣는게 아니라 매 단어를 넣을 때마다 나오는 RNN hidden state를 전부 이용하는 겁니다.
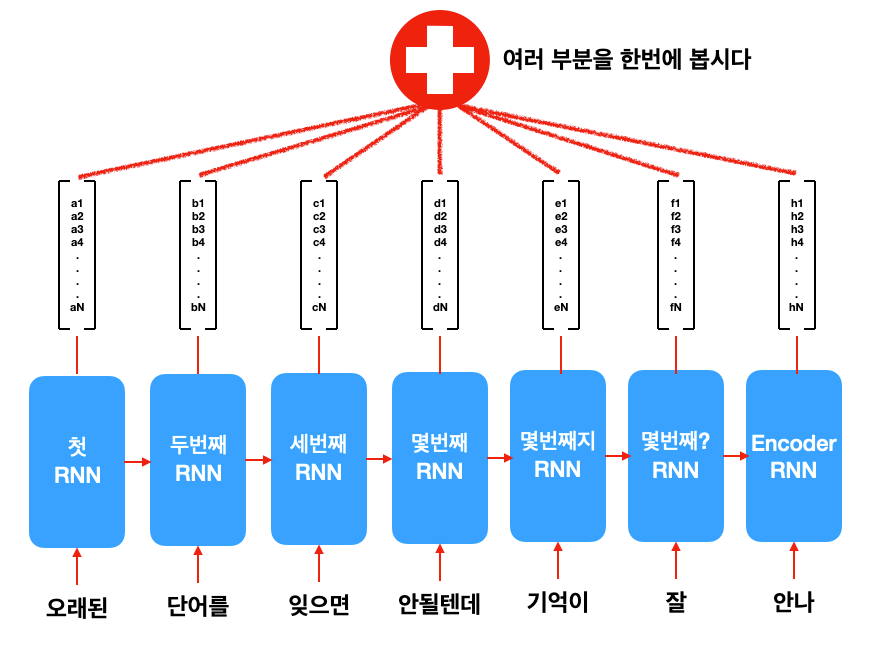
그러면 한 개의 sentence embedding이 아니라, 여러 개의 vector들이 나옵니다. 근데 얘네들은 워낙 많기 때문에 한번에 묶는 방법이 필요합니다. 안 그러면 너무 모델이 방대해질뿐더러, 문장 길이가 그때그때 다른 것 (variable length)에 대응할 수가 없습니다. 어찌되었든 한번에 볼 수 있는 방법이 필요합니다.
그래서 나온 개념이 관심법(attention mechanism)입니다. 번역을 직접 해보신 분은 알겠지만, 긴 문장의 경우 몇 단어 먼저 번역해서 써놓은 후, 원래 문장의 뒷 부분을 다시 보고 다음 단어들을 번역할 때가 많습니다. 이처럼 내가 번역하고 있는 부분에 따라 원래 문장에서도 뒤돌아 봐야하는 부분이 달라진다는 것이 attention mechanism의 핵심 개념입니다.
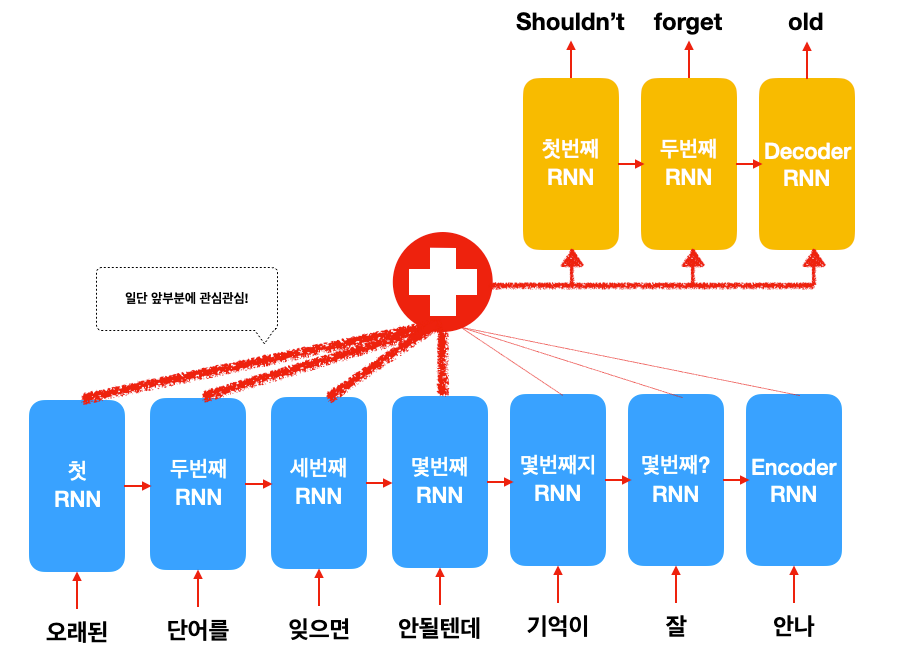
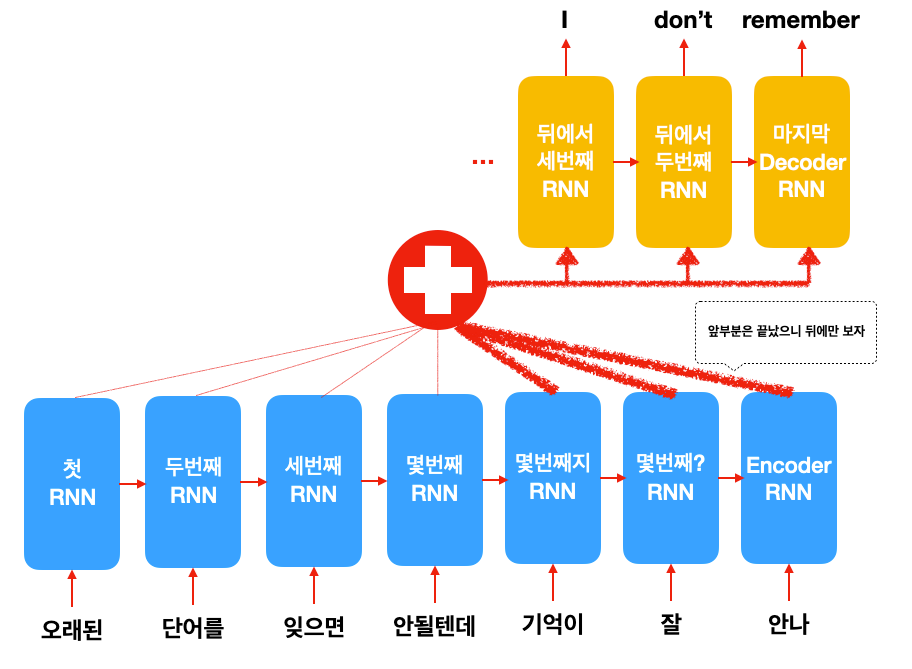
** 수학적으로는 weighted sum을 만들어서 averaging하는 것과 같습니다. 자세한 내용은 reference의 원 논문을 참고하세요.
위 그림을 보시면, 앞 부분을 번역할 때는 앞 단어들에 좀 더 관심을 기울이고, 다 끝나갈 때는 뒷 부분에 관심을 가지지요.
어떻게 모델이 어디를 관심있게 봐야하는지 아냐고요? 이 역시 머신 러닝 모델이 자동으로 데이터를 통해 학습을 합니다. 인간이 어떻게 하라고 직접적으로 프로그래밍하는 것이 아닙니다.
그렇다면 그냥 순서대로 한 단어씩 관심 갖게 하면 되는거 아니냐고요?
그건 지난 번 phrase-based MT에서도 잠깐 얘기했지만 언어마다 문장을 구성하는 순서가 다르기 때문에 (ex. 주어 + 목적어 + 동사의 한국어, 주어 + 동사 + 목적어의 영어), 데이터를 통해 학습을 하는 것이 더 효과적입니다.
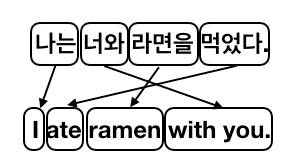
신기하게도 기계 학습 모델은 많은 데이터가 있다면, 번역할 때 어디에 관심을 가져야 하는지 알아서 척척 알아냅니다. 위 그림처럼 단어끼리 어떻게 대응 되는지 관계를 찾는 것을 phrase alignment라고 합니다. attention mechanism으로 학습된 모델은 이를 자동으로 학습할 수 있습니다. 아래 그래프를 한번 보시죠.
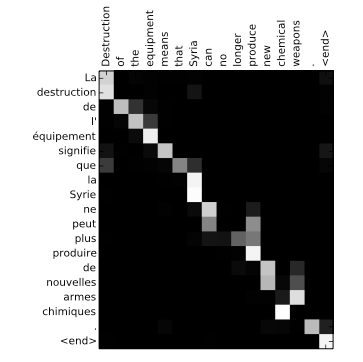
첫 영어 단어 Destruction을 번역할 때 관심을 받는 부분이 La destruction, Syria는 La Syrie에 관심이 켜지는 것을 볼 수 있습니다. 성별 관사가 들어가는 불어의 특성을 잘 파악한다는 증거지요. 그리고 마지막에 chemical weapon에서 armes chimiques으로 번역되는데, chemical은 chimiques에 관심이 켜지고, weapon은 armes에 켜지는걸 보시면 역시 형용사가 명사 뒤로 가는 불어의 특성을 모델이 알아서 잘 학습했다는 것을 알 수 있습니다.
오늘은 Attention Mechanism이라는 seq2seq를 훨씬 더 업그레이드 시킨 대단한 연구에 대해서 공부해보았습니다. 이 연구를 통해 기계 학습의 성능 역시 확 올라갔는데요. 이를 통해 transformer라는 굉장한 모델이 나오고, 누구나 한번쯤을 들어봤을 BERT라는 끝판왕 모델이 나오는데, 이게 모두 이 attention mechanism의 자손들이라고 보시면 되겠습니다.
그러한 모델들을 살펴보기 전에, 다음 주에는 seq2seq 모델이 기계 번역 말고 다른 문제에 어떻게 적용되었는지 살펴보려고 합니다. 슬슬 기계 번역이라는 주제에 싫증이 나실 법할 때가 될듯해서 제가 준비했습니다.
바로 Image Captioning, Computer vision (CV)과 NLP가 만나는 아주 재밌는 주제입니다! 놓치지 않으시려면 이메일 구독 하세요!

Reference
- D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate, ICLR 2015
- Kyunghyun Cho, Chapter 6: Neural Machine Translation, Natural Language Understanding with Distributed Representation