Week 24 - 나 대신 아이한테 그림 책 읽어주는 AI가 나올까


요즘은 아이들의 상상력을 자극하기 위해 아예 글이 없는 그림 책이 인기라고 합니다. 아이들이 글보다는 그림에 집중하게 되어 자연스럽게 질문을 던지고 스토리를 같이 만들어 가는 형식이 좀 더 뇌발달에 효과적일 수 있겠죠.
근데 읽어주는 부모 입장에서는 훨씬 고난이도 과제가 아닐까 싶습니다. 텍스트가 없으니 스토리를 직접 지어 내야 하기도 하고, 모든 페이지에 있는 그림을 해석해주어야 하니깐요. 여러모로 아이를 키우는 일은 굉장히 어려운 일이 아닌가 싶습니다. 전에 유아용 스마트 스피커 및 앱을 만드는 BabyTech 스타트업에서 1년 가량 일했는데, 그 때 어린이 책 데이터베이스와 추천 알고리즘을 개발하면서, 20대 때 미리 육아에 대한 고민을 많이 했었습니다 ㅎㅎ
그런데 말입니다, 이미지를 보고 글로 설명을 생성하는 AI 기술이 있다는거 아시나요? 바로 우리가 그동안 배웠던 기계 번역에 이용되는 모델을 응용해서 만들 수 있다는 것! 이번주 글은 그러한 image2text 기술들에 대해 이야기해보려 합니다.

Image Captioning, 나에게 보이는 걸 설명해줘

Image Captioning은 상당히 직관적이면서 어려운 문제입니다. 왜냐면 하나의 이미지를 보고 설명할 수 있는 방법이 거의 무제한이기 때문입니다. 위에 야구 경기 예시에서는 선수의 움직임을 설명하고 있지만, 어떤 사람은 경기장의 잔디가 먼저 보일 수도 있고, 유니폼의 색, 등번호 등 설명할 수 있는 것이 정말 다양하기 때문입니다.
그렇기 때문에 AI 모델은 오로지 학습 데이터에 의존할 수 밖에 없습니다. 만약 학습 데이터가 사람과 움직임에 대한 설명이 많다면, 새로운 사진에 대해서도 그렇게 해석을 할 것이고, 색감과 디자인에 대한 설명이 많다면 잔디나 유니폼 색에 대해 이야기할 확률이 높습니다. 이건 어떻게 보면 자연스러운 것 아닐까 싶습니다. 사람도 역시 자기의 살아온 인생 (학습 데이터)에 따라 예술 작품 또는 사진을 보고 주목하는 것이 다를테니깐요.
기계 학습에서의 encoder-decoder 모델에서는 encoder는 기존 문장 (ex. 한국어)을 읽고, decoder는 번역 문장 (ex. 영어)를 생성합니다. Image captioning을 하려면 이 프레임워크가 어떻게 바뀌어야 할지 감이 오시나요?
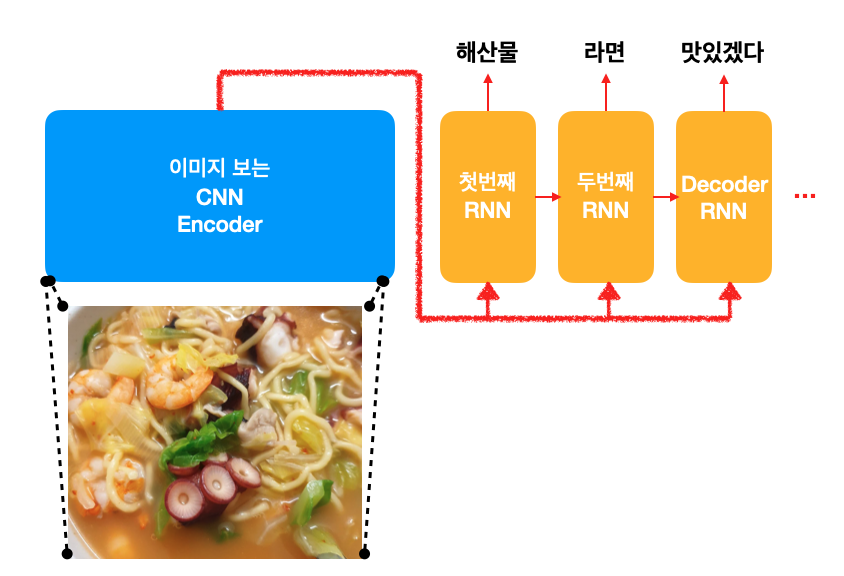
생각해보면 이미지를 보고 캡션을 생성한다는 것은 일종의 번역과 같습니다. 다만 input이 문장이 아니라 이미지로 바뀌었습니다. encoder는 이미지에 더 효과적인 Convolutional Neural Network (CNN) 구조로 바꾸어씁니다.
여기서 지난 주에 배운 관심법 (attention mechanism)은 아주 적절하게 이용됩니다. 단어 한 개 한 개를 내뱉을 때 이미지의 각각 다른 부분에 주의를 기울인다는 것은 아래 예시 처럼 매우 직관적입니다.

기계 번역에서의 Attention Mechanism이 처음 발표 되고 곧바로 같은 연구 그룹에서 Show, Attend, and Tell: Neural Image Caption Generation With Attention이라는 제목의 논문이 공개되었습니다. 모델이 단어를 뱉을 때 어디를 보고 이야기하는지 알 수 있어 틀리더라도 직관적인 분석이 가능해 큰 반향을 일으켰습니다.

단지 이미지에 등장하는 물체의 이름 뿐만 아니라 on, in, with, over 같은 전치사로 공간적인 개념까지 학습할 수 있다는 것이 아주 인상 깊습니다.
Visual Question Answering/Generation, 이미지 보고 질문하고 답하기
그 이후, Image2text 분야는 엄청나게 재밌어집니다. 단순히 그림을 설명하는 것이 아니라 이제는 질문을 던지면 답까지 유추할 수 있게 하는 데이터 셋이 등장합니다.

매 년 열리 VQA Challenge 같은 대회를 통해 모델 성능 경쟁을 유도해 엄청난 발전을 이루어내기도 하고, 아예 비슷하면서 조금 방식의 문제를 spin-off하기도 합니다. 예를 들어, 아래 논문은 그림을 보고 질문을 생성하는 모델을 만들어냅니다.
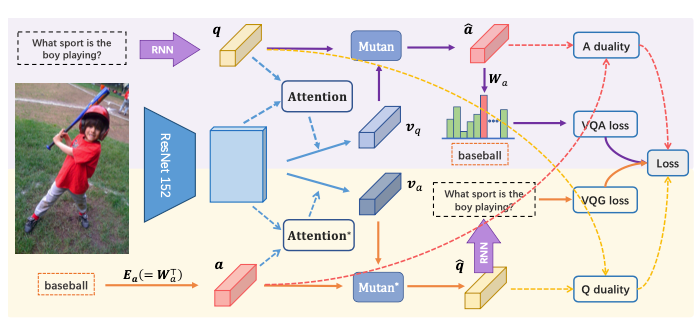
원래 이 논문의 메인 포인트는 "모델이 이미지를 보고 질문을 생성하는 법을 학습하면, 답하는 것도 잘할 수 있을 것이다"라는 것인데, 그냥 질문 생성하는 것만해도 꽤 재밌는 것 같습니다. 제가 BabyTech 스타트업에서 일했을 때 이런 연구를 보고, 부모들한테 그림 책을 아이에게 읽어줄 때 어떤 질문을 던져주면 좋은지 질문을 추천해주는 시스템을 만들어 출판사들에게 팔면 어떨까 이런 아이디어가 있었는데, 리소스가 부족해 실현하지는 못했었습니다.
Interactive Image Retrieval: 내가 원하는 걸 설명해볼게
더 나아가, 시스템과 대화를 하면서 이미지를 찾아보는 것은 어떨까요? CVPR 2020에서는 Fashion IQ라는 흥미로운 응용 분야에서 데이터 셋을 공개해 워크샵을 열었습니다. 두 패션 이미지의 차이를 언어로 이해할 수 있는 시스템을 개발한다면, 사람이 이미지를 보고 "좀 더 밝은거 없어?", "스트라입 무늬를 원해" 이런 식으로 질문을 했을 때 원하는 이미지를 찾을 수 있다면?
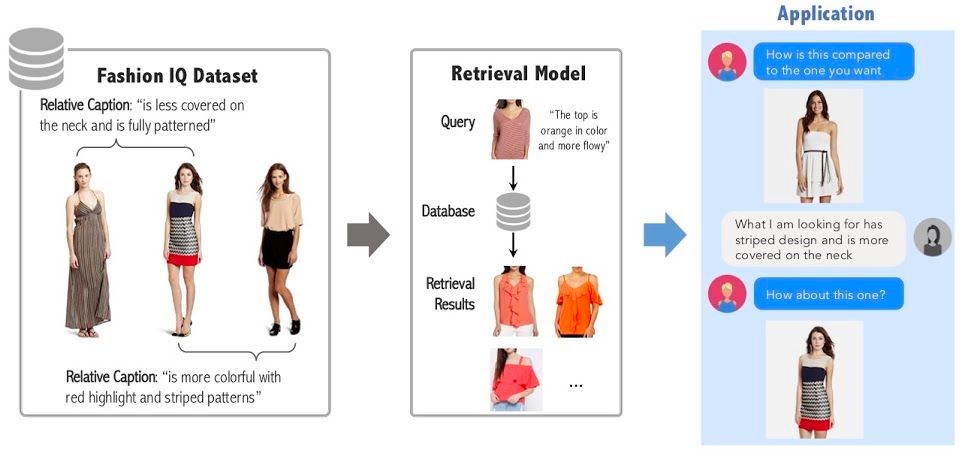
작년 ICCV 2019에 열린 대회에서는 비슷한 데이터에서 서울대 AI 연구 팀 (Ripple AI)이 좋은 결과를 냈었다고 하네요.
오늘은 컴퓨터 비젼 (CV)와 자연어 처리 (NLP)가 융합된 너무나 재밌고 기대되는 분야를 잠깐 기웃거려 보았습니다. 앞으로도 응용될 수 있는 것이 정말 무궁무진한 것 같은데요. 혹시라도 이쪽으로 더 관심있으시거나 재밌는 아이디어가 있으시다면 댓글로 남겨주세요! 재밌는 프로젝트를 같이 할 수 있지 않을까요?

Reference
- Lin et al., 2014, Microsoft COCO: Common Objects in Context
- Xu et al., 2015, Show, Attend, and Tell: Neural Image Caption Generation With Attention,
- Goyal et al., 2017, Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
- Li et al., 2017, Visual Question Generation as Dual Task of Visual Question Answering,
- https://visualqa.org/challenge.html
- Fashion IQ: A New Dataset towards Retrieving Images by Natural Language Feedback. Xiaoxiao Guo*, Hui Wu*, Yupeng Gao, Steve Rennie and Rogerio Feris. Arxiv. 2019



