Week 25 - NLP의 옵티머스 프라임, Transformer 등장!


반바지를 입고 아이스크림을 들고 있던 아이는 그것을 금방 다 먹었다.
여기서 그것은 무엇을 가리키는 걸까요? 설마 아이가 반바지를... 번역을 하다보면 대명사 때문에 애먹는 경우가 많습니다. 그것이 무엇인지 유추하려면 앞에 있는 "아이스크림"과 뒤에 있는 "먹는다"라는 두 단어를 동시에 고려해야 합니다. 인간은 그냥 주르륵 읽기만 해도 바로 답이 나오지만 머신 러닝 번역 모델이 이를 학습하는 것은 꽤나 어려운 일입니다.
오늘은 Neural Machine Translation (NMT) 뿐만 아니라 NLP 분야 모델의 끝판왕으로 자리 잡고 있는 트랜스포머(Transformer)에 대해서 공부해보겠습니다. 2017년 말에 Google Brain 팀에서 Attention Is All You Need 라는 논문에서 첫 선을 보인 트랜스포머는 최신 트렌드를 따르시는 분들이라면 여러 번 들어보셨을 BERT나 GPT의 기반이 되는 모델입니다.

RNN은 한쪽 밖에 모르는 바보..?
만약 위 문장을 RNN으로 처리한다면 어떻게 될까요? 문장의 처음부터 한 단어가 차례대로 컨베이어 벨트로 들어가겠죠.
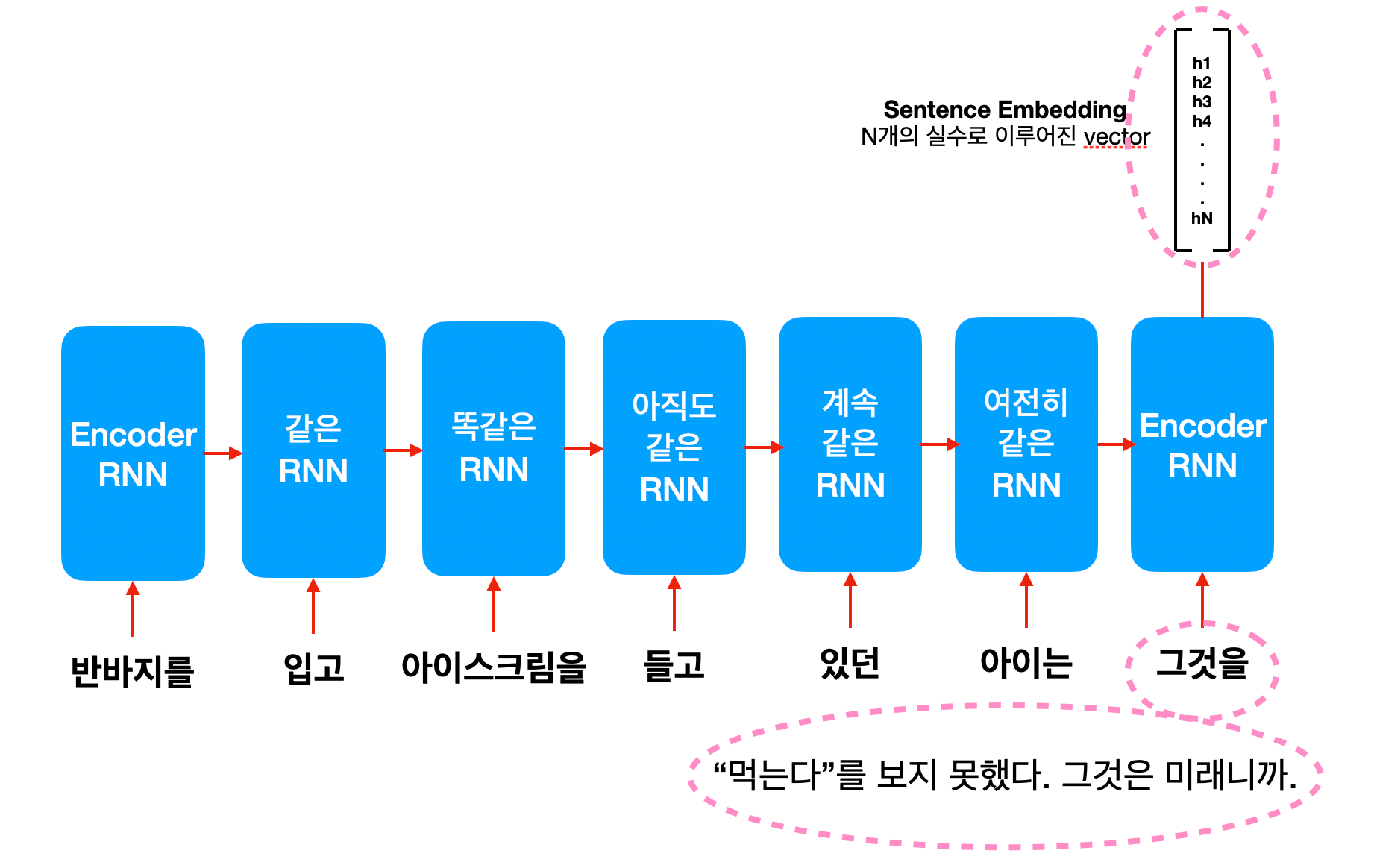
그런데 문제는 "그것"이 아이스크림이라고 이해를 하려면 "먹는다"까지 고려를 해야 하는데, RNN의 순차적인 처리 구조에서는 이게 불가능합니다. "먹는다"가 RNN에 들어갈 때는 "그것"에 대한 hidden state가 이미 output 되고 끝이 났기 때문이죠. 이를 해결하기 위해서 bi-directional RNN이라는 것이 등장합니다. 문장을 앞에서부터 보는 forward RNN, 뒤에서부터 보는 backword RNN 두 개의 hidden state output을 엮어서 함께 보는 방식입니다. 이는 또 다른 유명한 모델인 ELMO의 방식이기도 합니다.
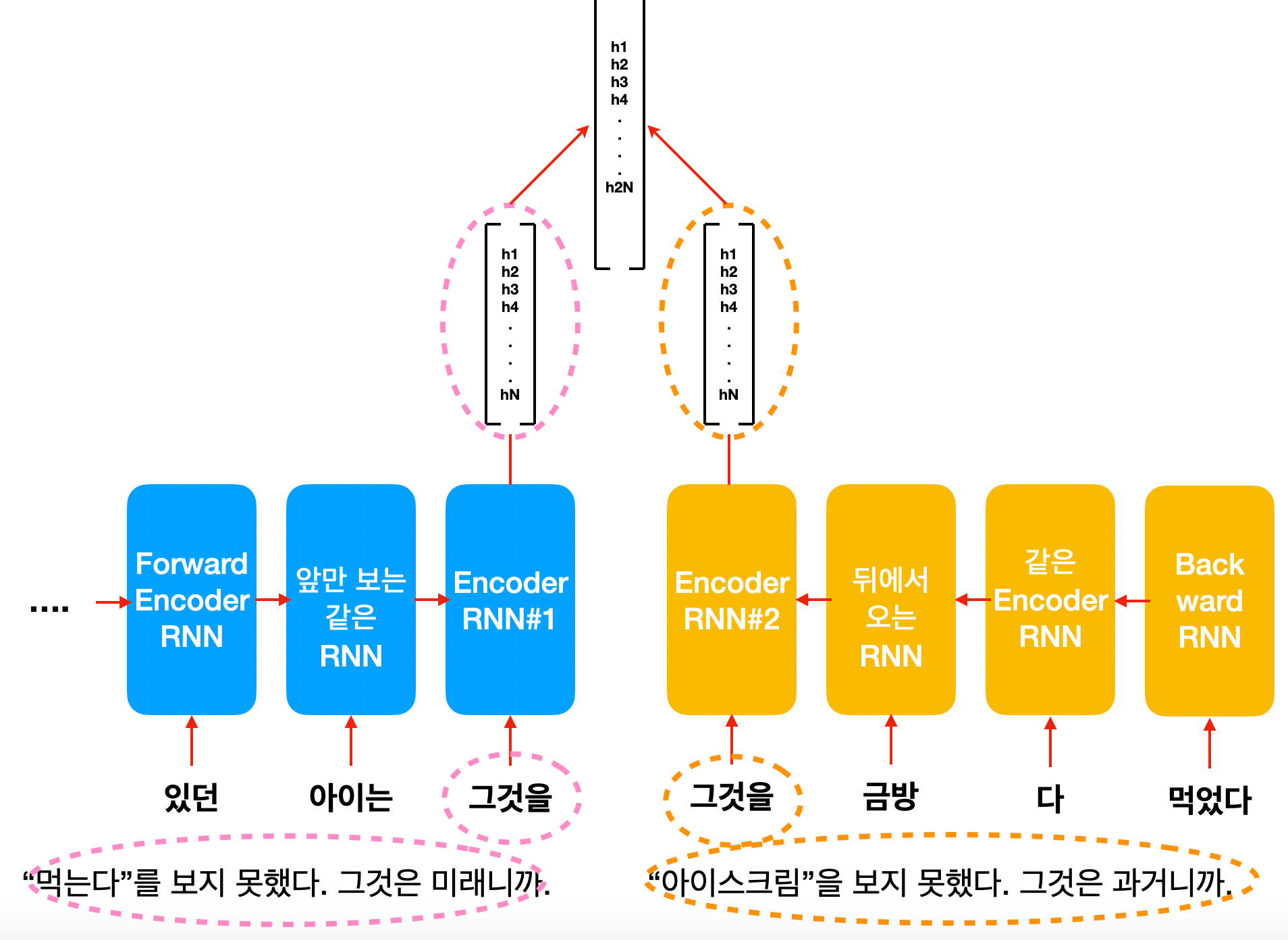
하지만 결국 backward RNN도 "먹는다"는 보지만 "아이스크림"을 못 보기 때문에 결국 RNN은 "그것"을 이해하기 위해 "아이스크림"과 "먹는다"를 동시에 보는 것은 구조적으로 불가능합니다. 이쯤에서 지지난 주에 배운 Attention Mechanism이 생각나시는 분이 있으시다면 본인을 칭찬해주세요! 잘 따라오고 계십니다.
Attention Is All You Need (a.k.a. RNN은 갖다 버려!)
Attention Mechanism은 번역 문장(target)을 생성할 때 원본 문장(source)의 여러 부분을 한꺼번에 참고하기 위해 만들어진 구조입니다. 그렇다면 "그것"을 번역할 때 "아이스크림", "그것", "먹는다" 세 단어를 같이 관심을 줄 수 있으면 문제가 해결되는게 아닐까요?
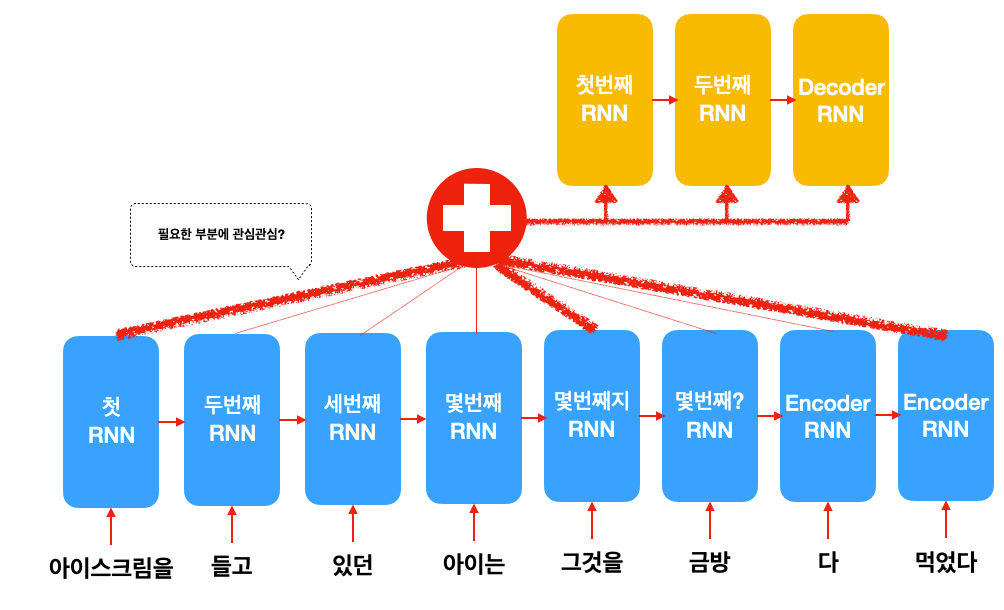
네, 맞습니다. 그런데 트랜스포머 연구자들은 이런 현상을 보고 이렇게 생각했던거 같습니다. "아니 어차피 attention mechanism으로 문장 앞이고 뒤고 나중에 다 볼 수 있는데 RNN이 왜 필요한거야? 그냥 Attention만 있으면 되는거 아니야? That's all you need!" 그렇게 깔려있던 컨베이어 벨트는 모두 철거가 되고 이러한 구조만 남습니다.
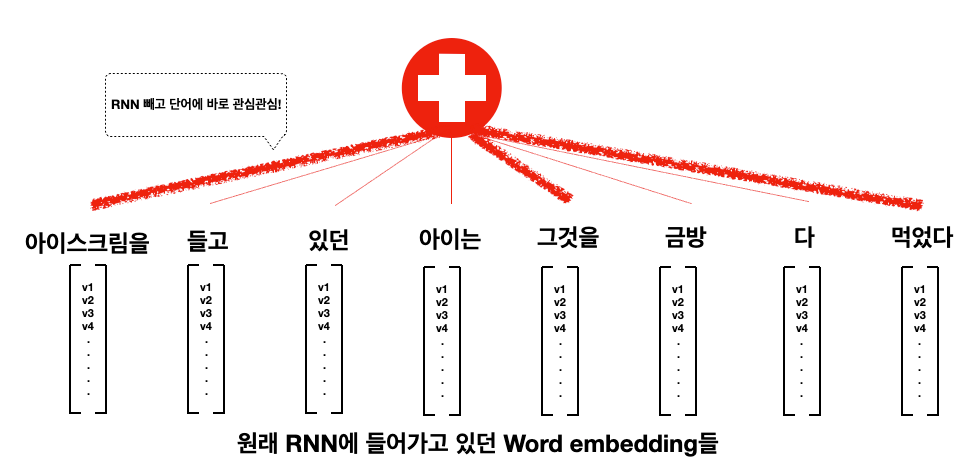
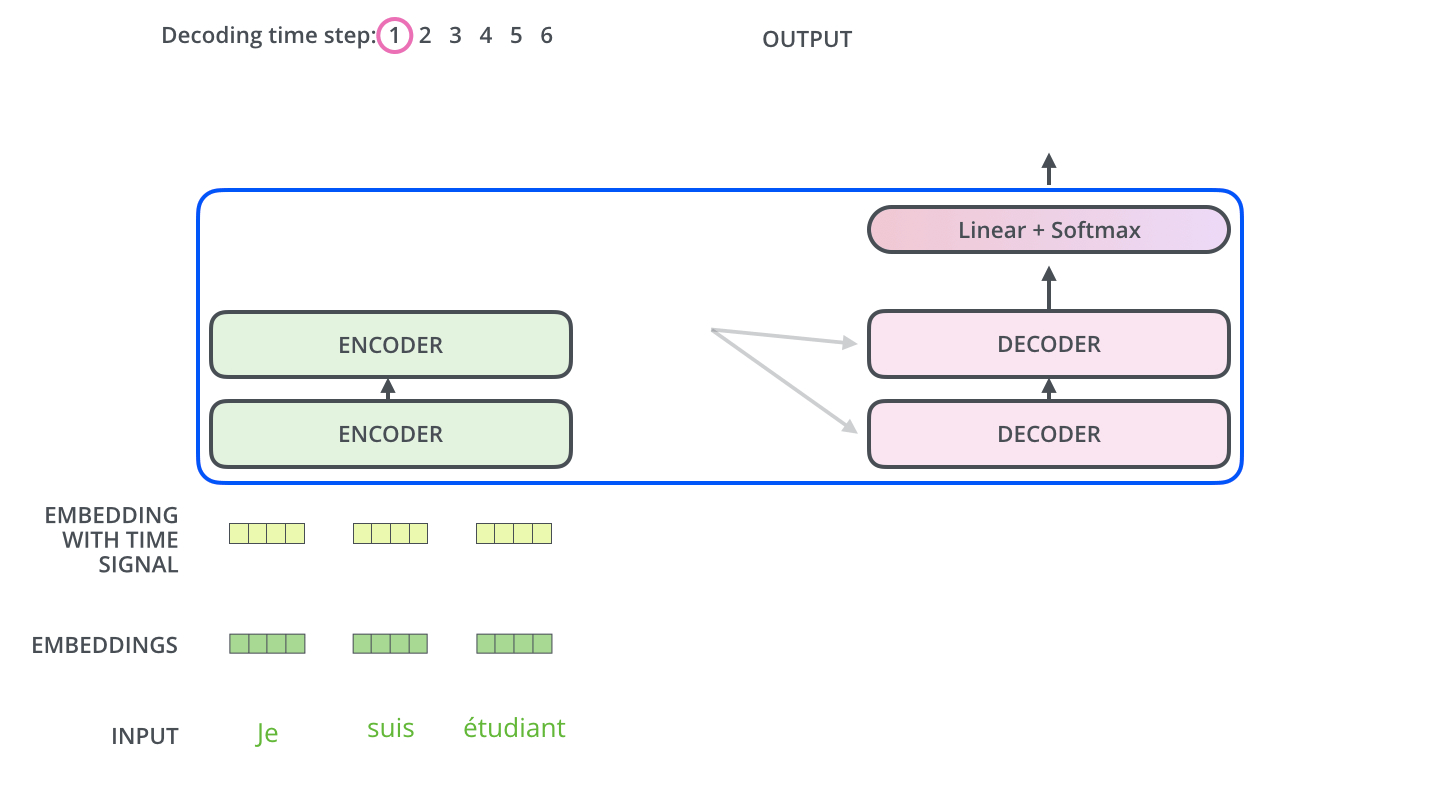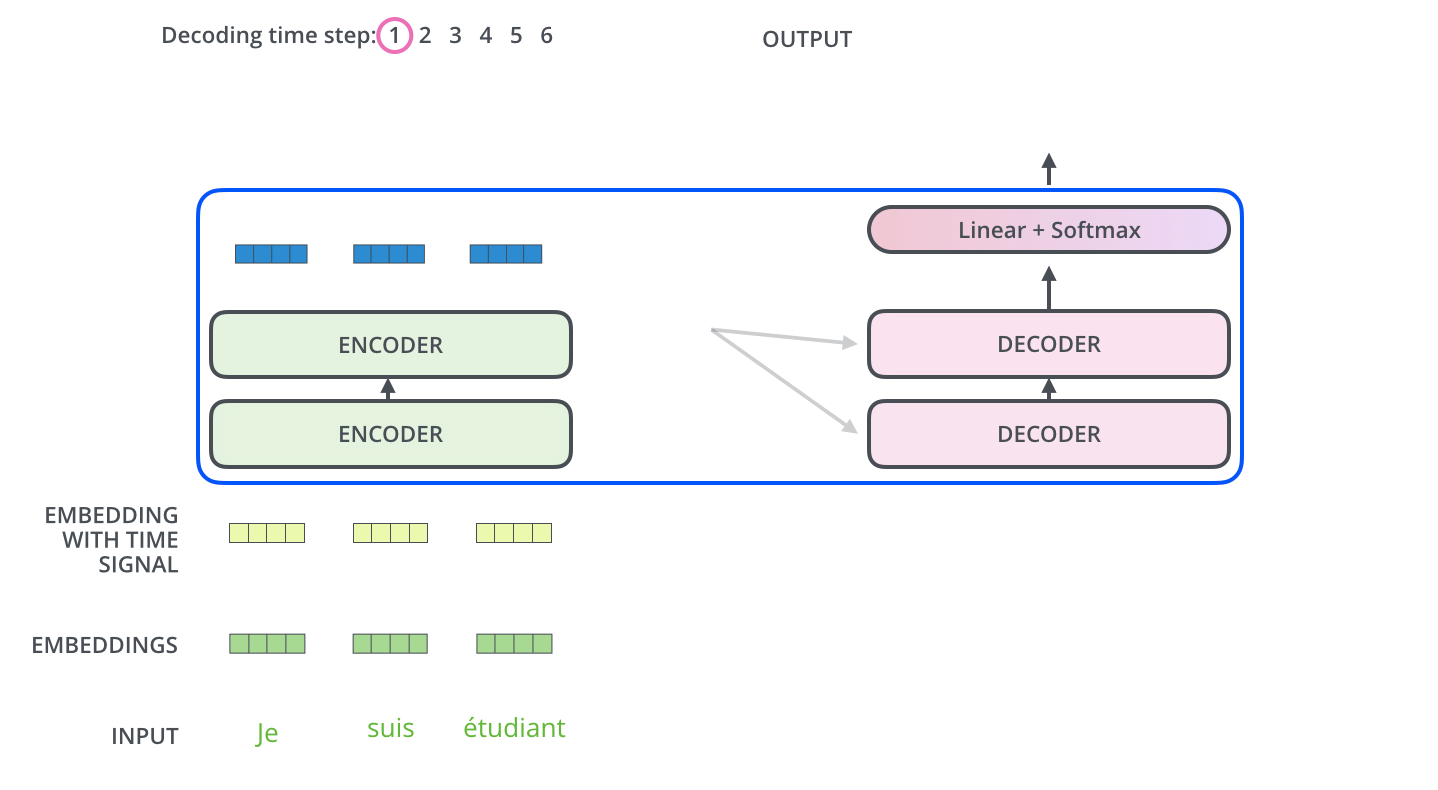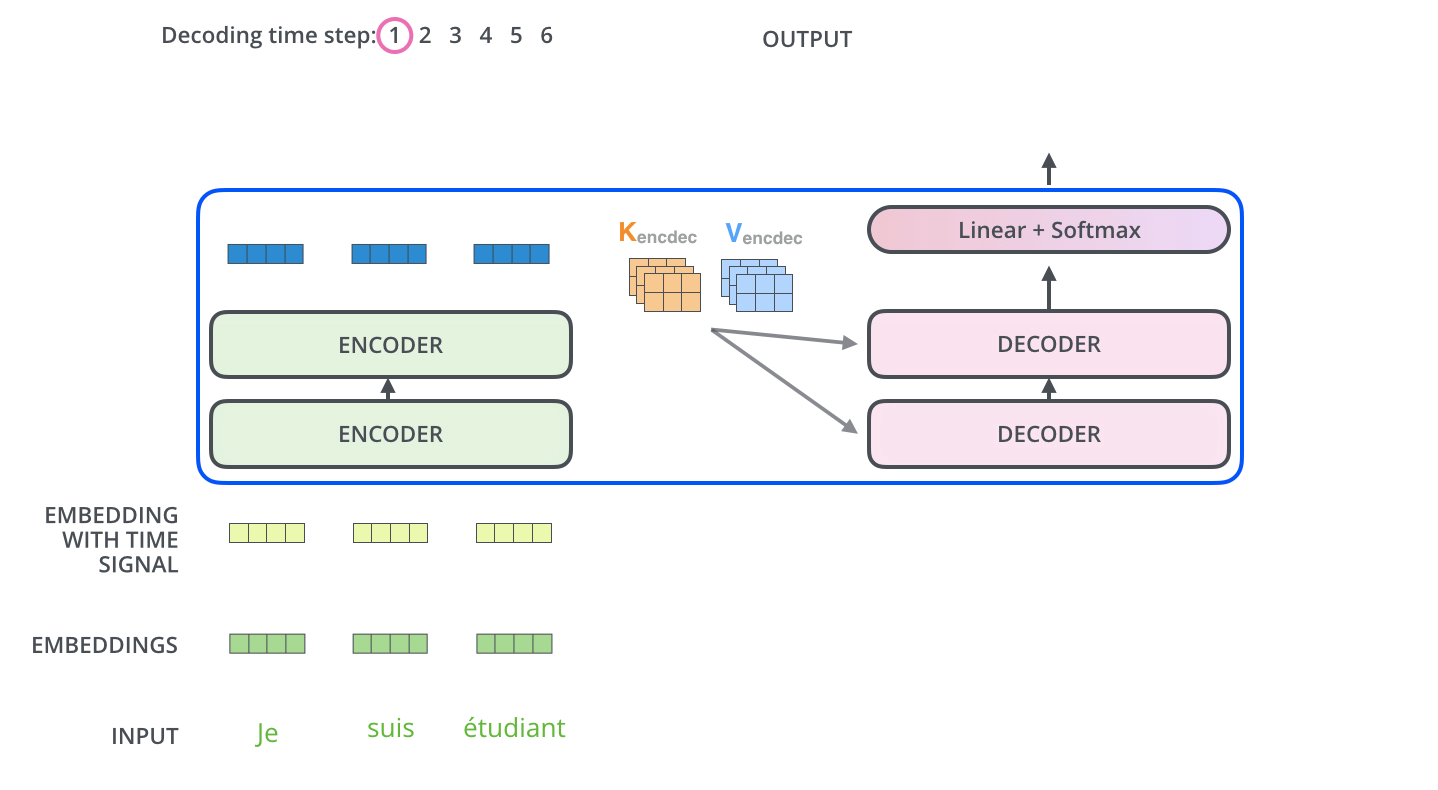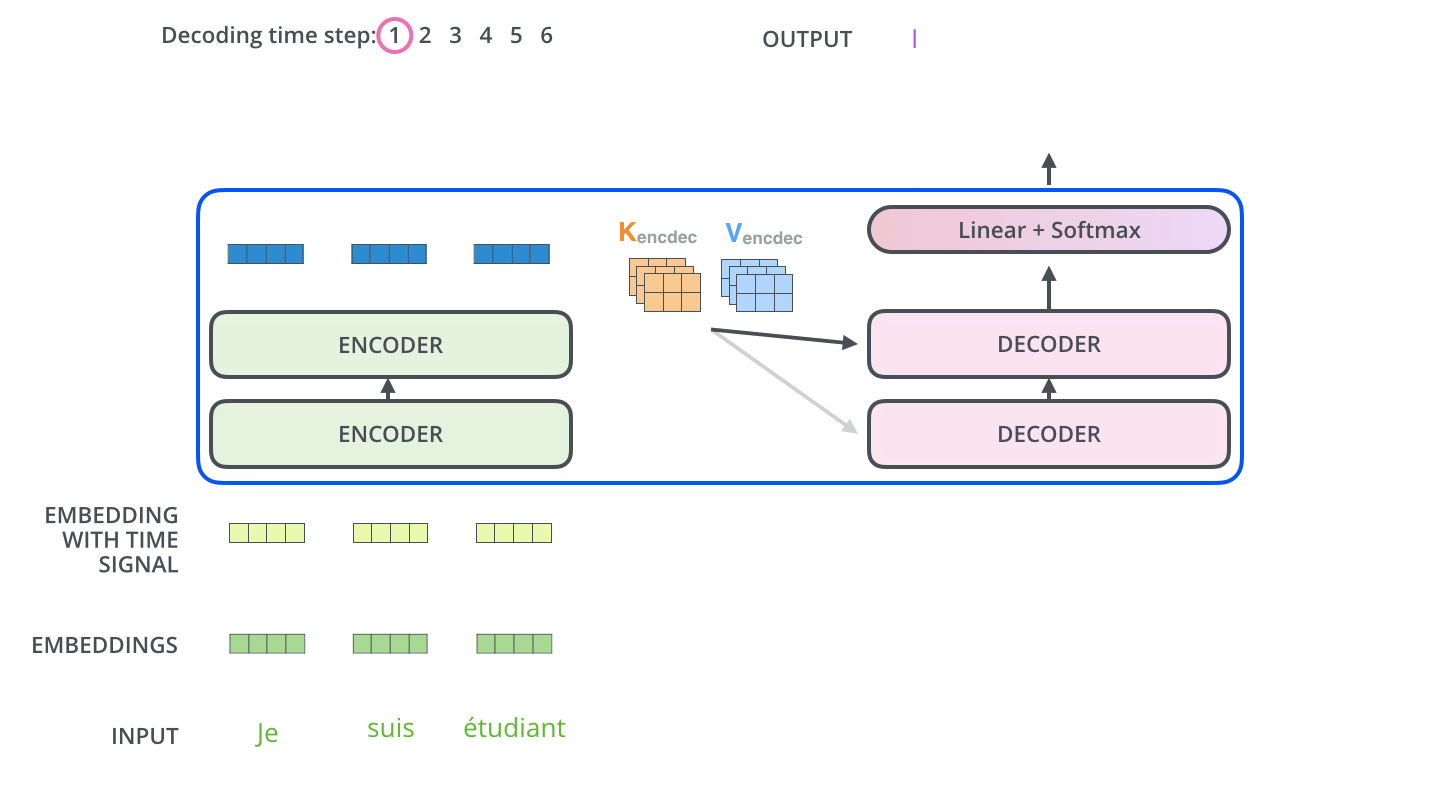
여기서 Word Embedding 뿐만 아니라 Positional Embedding이라는 것이 추가로 붙습니다. 단어를 RNN처럼 순서대로 넣는 대신 문장을 한번에 뭉치로 보는 attention mechanism을 쓰기 때문에 이 단어의 순서에 대한 정보를 어딘가에 추가해줘야합니다. 이 정보를 단순하게 N 번째이다하고 숫자를 첨부하는 것이 아니라, sin, cos함수를 합성하여 나타낸 vector로 표현한다는 점이 참 창의적입니다. 신기하게도 단어의 위치를 일종의 신호 (signal)로 표현하는 것이 성능에는 더 효과적이라고 합니다. 단숨에 이해하기 어려운 내용인데, 자세한 내용은 원 논문을 참고하시기 바랍니다.
Harder, Better, Faster, Stronger
트랜스포머는 이름처럼 무시무시하게 강력한 모델입니다. 기존 Attention Mechanism은 RNN의 hidden state를 softmax layer로 한 개의 vector로 합쳐버리는데에 그치지만, 트랜스포머는 Query, Key, Value 등 여러 개의 vector를 생성한 후 feed-forward network에 넣어버리고...
벌써 무슨 말인지 모르겠죠? 사실 이 구조를 하나하나 설명하다보면 제가 약속한 15분 안에 설명을 못합니다. 한마디로 설명하자면 기존의 Attention Mechanism보다:
성능이 엄청납니다. 왜 그런지를 요약해보자면:
1) Self-Attention: 같은 문장 안에 있는 "아이스크림", "그것", "먹는다" 등 여러 가지의 단어 조합을 한번에 관심에 넣을 수 있습니다. 그렇게 때문에 더 복잡하고 많은 파라미터(parameter)를 가집니다.

2) Multi-headed Attention: 관심 위에 관심. Encoder를 여러 개의 쌓아올려 단어 조합의 조합, 또는 조합의 조합의 조합까지 고려할 수 있습니다.
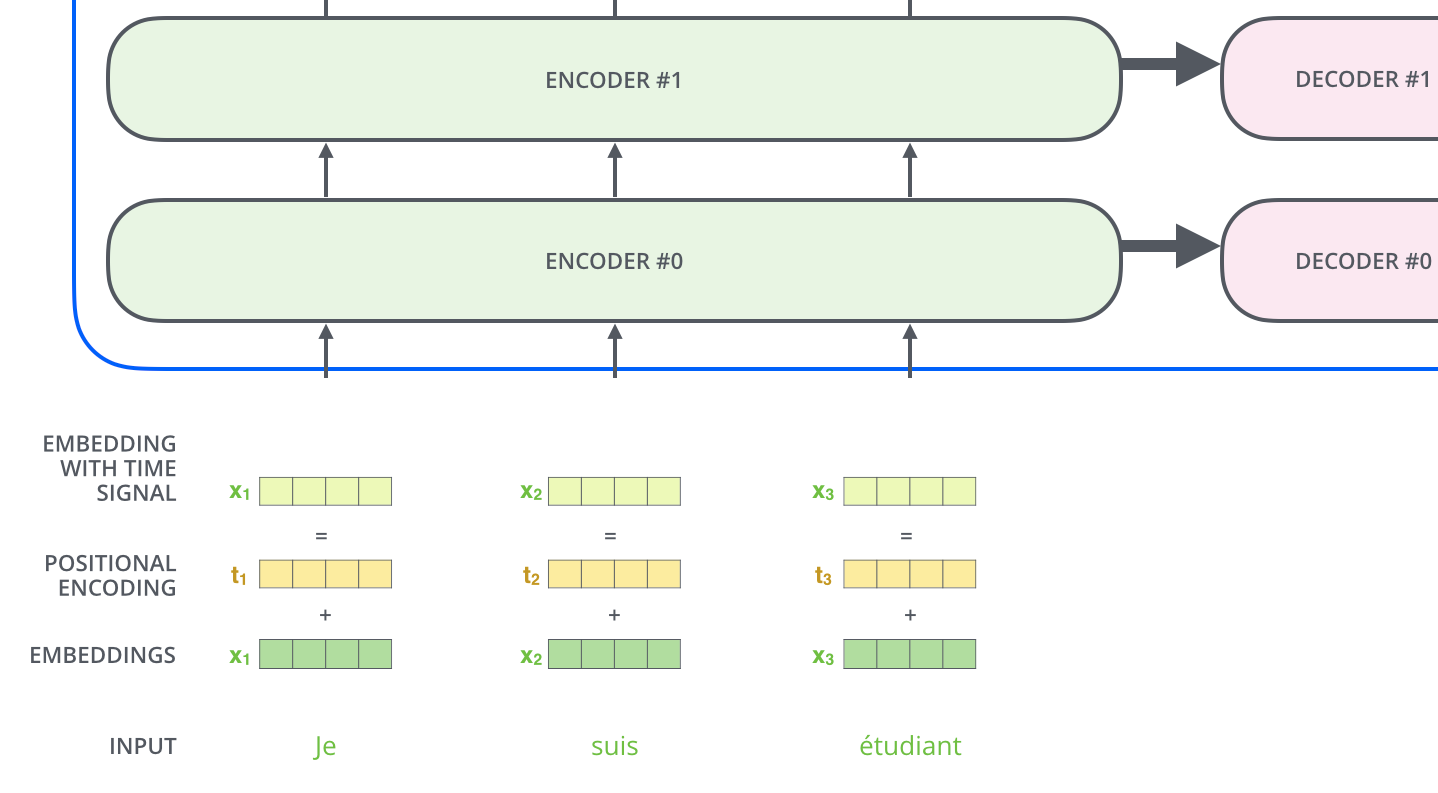
3) Parallelization: 문장의 마지막 단어를 보려면 문장 전체가 컨베이어 벨트에 들어갈 때까지 기다려야 하는 RNN과 달리 트랜스포머는 각 위치에서 문장을 통채로 보기 때문에 따로 계산할 수 있습니다. 이는 기존 모델과는 다르게 분산 컴퓨팅 (distributed computing)이 가능하게 한다는 점에서 큰 의미가 있는데, GPT-2,3 같이 미친듯이 큰 모델이 나오게 된 가장 중요한 이유입니다.
이렇게 트랜스포머는 당시 있었던 번역 모델의 최강 모델들보다 10배 또는 100배 더 효율적으로 (즉, 학습 시 연산을 적게 한) 학습되었음에도 불구하고 성능은 state-of-the-art (금메달)을 깨부수어 버리면서 큰 반향을 일으킵니다.
Transformer의 각 component들을 이해하시고 싶으시다면 원 논문과 위 이미지들의 출처인 The Illustrated Transformer 블로그(원문, 한국어 번역)를 읽어보시기를 추천합니다!
오늘은 Attention is All You Need, 트랜스포머 모델에 대해서 배워보았습니다. 그동안 기계번역 (NMT) 가 어떻게 Language Modelling부터 시작하여 Phrase Based, RNN-based seq2seq, Attention mechanism, 그리고 트랜스포머까지 왔는지 길게 역사를 훑어보았는데 어떠셨는지요?
Transformer의 자식 중에 또 대단히 유명해진 모델이 있죠. 바로 BERT! 이 녀석에 대해서 공부해보려 합니다. 정말 많은 NLP 문제들에서 좋은 성능을 보여주었는데요. BERT가 어떻게 Transformer를 이용해서 새로운 방법의 LM을 만들었는지에 대해 써보겠습니다.

Reference
- Vaswani et al., 2017, Attention Is All You Need, NIPS 2017
- Jay Alammar, The Illustrated Transformer, 2018



