

회사든 제품이든 아티스트 이름이든, 잘 지은 이름의 영향력은 대단한 것 같습니다. 매일 수천수만 개의 새로운 것이 쏟아 나오는 요즘 세상에 사람들 머릿속에 각인되는 게 그만큼 쉽지 않은데 말이죠. 근데 논문의 이름을 잘 지어서 대박이 난다? 동네 맛집도 아니고 보통 사람들은 평소에는 관심도 없는 NLP 논문을, 그것도 Google AI 연구 팀이 그걸 해냅니다. BERT라는 이름을 한 번쯤은 들어보거나 어디서 보셨나요?
물론 이름으로 유명세를 탄 맛집의 음식이 별로라면 금방 거품이 가라앉겠죠. 하지만 BERT는 실력도 엄청났습니다. 당시 웬만한 NLP 문제는 BERT로 평정이 되었고, 지금까지도 이 모델의 후속작들이 속속 나오고 있습니다. xxxBERT라는 이름의 유행과 함께요. 도대체 이 모델은 무엇일까요?
아 근데, 여러분 BERT가 무엇의 약자인지는 아시고 계셨죠?

이름부터 알고 넘어가기

어디선가 본 것 같은 단어,
- Bidirectional: 양 방향의. 지난주에 문장 내의 한 단어를 이해할 때 앞에 있는 단어들과 뒤에 있는 단어들을 봐야 하는 경우가 있다고 했었죠? 그런 경우까지 다 처리할 수 있다는 뜻입니다.
많이 나온 단어,
- Encoder: seq2seq에서부터 계속 나온 개념이죠. Noisy Channeling (Week 20)에서 나온 개념으로 문장을 하나의 vector로 암호화해서 넣는 모델을 뜻합니다.
뭔가 생소한 단어,
- Representation: 모델이 학습한 후의 결과물을 뜻합니다. NLP 뿐만 아니라 머신러닝에서 자주 나오는 개념인데, 이게 뭔지 설명하려면 책 한 권이 필요한데, 일단은 오늘은 간단하게만 알고 넘어갑시다.
제일 눈에 익는 단어,
Transformer: 지난주에 배운 모델이죠? 놓치셨거나 기억이 안 나시면 어서 복습하러 고고!
- Transformer는 self-attention을 통해 하나의 단어를 이해하기 위해 문장 내의 다른 단어들과의 관계, 조합을 봅니다.
- 그렇기 때문에 앞만 바라보는 RNN과는 달리 Transformer는 앞뒤를 전부 다 볼 수 있습니다 (bidirectional).
- Attention 위에 Attention을 쌓은 Multi-headed attention을 통해 더 복잡한 단어 간의 관계를 모델링합니다.
- 이 모든 정보를 하나의 vector로 압축하여 표현합니다 (encoder, representation)
설명해보니깐 Transformer가 앞에 세 단어의 개념을 모두 포함하네요. 이게 BERT라는 차별성이 있는 이름을 짓기 위한 큰 그림이 아니었을까....? (저의 뇌피셜입니다)
BERT의 구조
BERT의 내부는 그냥 Transformer입니다. 모델 구조에서 특별한 것은 없습니다. 하나의 문장이 여러 개의 단어로 나뉘고**, word embedding 같은 vector로 표현되어 input되고, 각 단어마다 output vector가 나옵니다.
** 좀 더 정확히 말하면 단어가 아니라 SentencePiece라는 알고리즘으로 문장이 여러 개의 토큰(token)으로 쪼개집니다. Tokenization은 NLP에서 또 상당히 까다로운 문제라 다른 글에서 배워보도록 하겠습니다.
기존과는 다른 Language Model
그렇다면 BERT의 차별성은 어디서 오는 걸까요? 첫 번째는 Language model(LM)을 학습 방식의 차이점입니다.
우리가 처음 LM을 공부했을 때에는 앞의 단어들을 보고 다음 단어를 예측하는 방식으로 학습이 된다는 것을 배웠죠. BERT는 이 문제를 좀 더 어렵게 냅니다. 바로 중간 단어를 가리고 예측하는 Masked Language Model (MLM)입니다.

위 예시와 같이 MLM은 좀 더 다양한 방식으로 문장을 학습할 수 있습니다. 그렇기 때문에 모델이 문장과 단어들에 대한 좀 더 앞뒤로 복합적인 이해 능력을 가질 수 있습니다. 이렇게 차별성을 둘 수 있는 이유는 다 Transformer가 앞뒤를 모두 볼 수 있는 모델이기 때문입니다. 그전에 RNN은 한 방향으로만 돌아볼 수밖에 없었죠.
이렇게 BERT는 주어진 단어들의 15% 정도를 마스크를 해버리고, 원래 단어가 무엇인지 예측하는 방식으로 학습이 됩니다.
두 문장 간의 관계를 배우는 Two Sentence Task
BERT을 학습하는 두 번째 과제는 2개의 문장이 주어졌을 때 서로 붙어서 나타나는 문장들인지 아닌지 예측하는 것입니다.
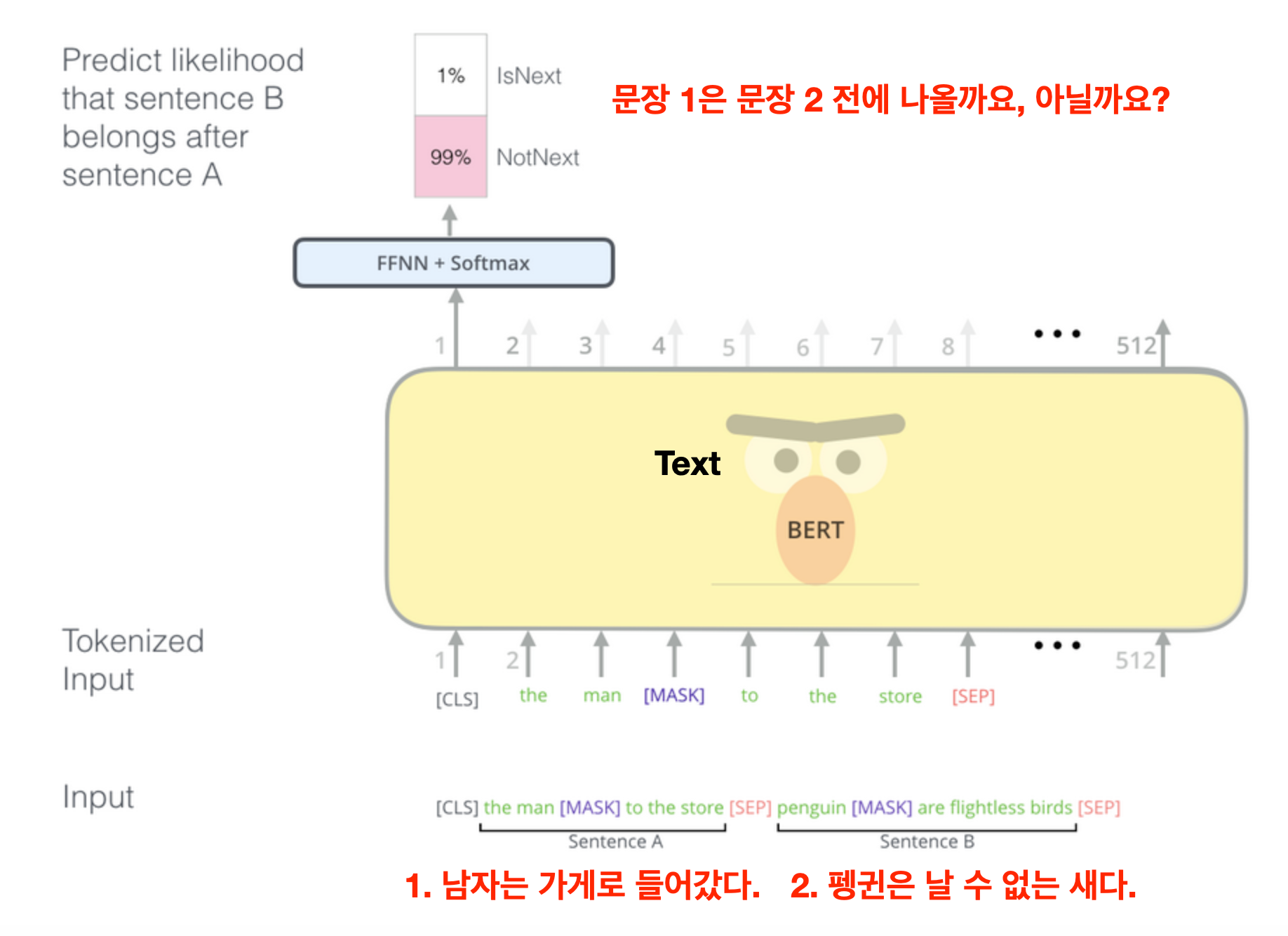
아마 제대로 쓰인 글이라면 "남자가 가게를 들어갔다" 다음에 "펭귄은 날 수 없는 새다"가 나오지는 않겠죠. 이런 식으로 BERT는 두 문장이 있을 때 단어들과의 관계, 문장 두 개 간의 관계를 학습합니다.
학습 데이터는 무엇으로? 얼마나 걸리나?
우리가 배운 word2vec이나 다른 LM처럼 BERT 역시 따로 labeling이 필요 없이 아무런 텍스트 데이터만 있다면 바로 학습할 수 있습니다. 그냥 있는 문장에다가 마스크를 씌우고, 아무 글의 문장 두 개를 가져다가 붙어있는지 아닌지를 예측하게 하도록 하면 되니깐요.
물론 구글은 많은 데이터와 컴퓨팅 파워로 BERT를 학습한 후 다양한 NLP 문제들의 최고 기록들을 박살 낸 후, 학습 코드뿐만 아니라 이미 학습된 모델까지도 오픈소스로 공개해버렸습니다. 심지어 100여 개의 언어를 한 번에 다룰 수 있는 다국어 BERT까지도요.
구글의 모델은 위키피디아 덤프, 수많은 책의 텍스트, 그리고 인터넷에서 크롤링된 Common Crawl Corpus 등으로 학습되었다고 합니다.
또한 기본 모델 (BERT-Base)은 1억 개 이상, 성능을 최대한 끌어올린 BERT-Large는 3억 개의 parameter를 가지고 있습니다. 그렇기 때문에 엄청나게 많은 연산이 필요한데, 4~16개의 Google Cloud TPU Instance (Google 버전의 GPU; 머신러닝에 적합한 연산 칩)를 사용하면 4일 정도의 학습기간이 걸린다고 합니다. Bert-Base 모델을 TPU 1개로만 가지고 하면 약 2주 정도 걸리는데, 이 부분만 500 USD 이상의 비용이 소요된다고 하니 데이터가 많거나 모델이 더 커지면 돈이 더 많이 들겠죠.
다행히도 이미 학습된 많은 모델들이 공개되어 있어 대부분의 연구자/개발자들은 처음부터 학습할 필요는 없이 오픈소스 된 모델들을 가져다가 쓸 수 있습니다.
 GitHub
GitHub GitHubGitHub
GitHubGitHub
오늘은 대망의 BERT 모델을 기본 구조과 학습 방법을 공부해보았습니다. 그런데 이 모델을 어떻게 실전에 쓸 수 있다는 것일까요? 어떠한 NLP 문제이든 다 적용할 수 있는 것일까요? 도대체 왜 이렇게 다들 BERT, BERT 하는 것일까요?
그걸 알기 위해서는 머신러닝에서 아주 중요한 개념을 먼저 짚고 넘어가야 합니다. 바로 Transfer Learning(전이 학습; TL)입니다. TL의 핵심은 "남의 덕을 보고 살자"라는 것인데요. 다음주에 먼저 TL을 공부하고 다시 BERT의 실제 응용 방법을 알아보도록 하겠습니다.

Reference
- Devlin et al., 2018, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- NLPinKorean Blog, The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) (한국어 BERT 설명)
- Google Research BERT github (https://github.com/google-research/bert)