

"불가리스 코로나19 억제 효과 검증돼"
어렸을 때부터 불가리스를 가끔씩 즐겨마시던 저는 "잉?"하면서 클릭했습니다. 10초만 더 생각했어도 말이 안되는 기사라는 것을 알았겠지만, 역시 스마트폰을 사용하는 손가락은 뇌보다 빠릅니다. 기사를 훑어보고, 제대로 된 임상연구가 아니라는 것을 금방 깨달았습니다. "아, 정말 이렇게 대놓고 광고성 기사를 써도 되는건가?" 싶었습니다.
아니나 다를까, 이 기사는 엄청난 역풍을 맞았습니다. 얼마 안 가 회장이 대국민 사과를 하고 사퇴를 하였습니다. 1년 이상 누적된 코로나에 대한 피로도와 이 회사가 여태까지 사람들에게 밉보인 일들이 있기 때문에 더 후폭풍이 심했던 것이겠죠. 문득 이 기사를 쓴 기자는 징계를 받았을지 궁금해집니다.
눈길을 끄는 헤드라인은 어느때보다 중요해졌습니다. 옛날처럼 하나의 신문을 구독하여 읽는 시대가 아니라, 엄청나게 쏟아져나온 기사 중에서 사람들의 관심을 끌어 클릭을 받아야 하는 시대가 되었기 때문이죠. 특히 기자가 클릭수로 자신의 글에 대한 평가를 받는다면 더더욱 그렇습니다. (솔직히 저도 글을 쓰면서 제목을 정하는게 가장 어렵다고 느끼기에 공감이 되네요)
그만큼 "낚시성" 헤드라인도 많아졌습니다. 읽다보면 나중에는 결국 어떤 제품의 광고이라거나, 제목과 본문의 중요한 내용이 일치하지 않은 경우가 있습니다. 시간을 낭비한 것 같아 짜증도 나고 무심코 클릭해 들어온 나에게 자괴감도 듭니다. 도대체 우리는 왜 이런 기사에 소중한 시간을 빼앗겨야 하는 것일까요? NLP를 통해 이런 기사를 걸러낼 수는 없는 것일까요?
이 문제를 NLP로 해결하려는 연구자 분들이 계셔 이 글을 통해 소개를 하려고 합니다. 숭실대 AI융합학부의 박건우 교수님과 Adobe Research NLP 팀의 윤승현 연구원님의 최근 연구를 다루어보고, 논문 저자 분들과 인터뷰를 통해 더 많은 의견을 나누어 보았습니다.
**위클리 NLP의 <저널리즘 x NLP> 시리즈의 첫번째 글입니다.

헤드라인 낚시꾼을 잡는 딥러닝 모델
기사를 잘 읽는 딥러닝 모델을 만드려면 어떻게 해야할까요? 일단 기사가 어떤 구조로 되어 있는지 생각해보아야겠지요. 아래와 같이 보통의 신문기사는 헤드라인(H) 그리고 본문 안의 문단(P) 여러 개로 이루어져 있습니다.
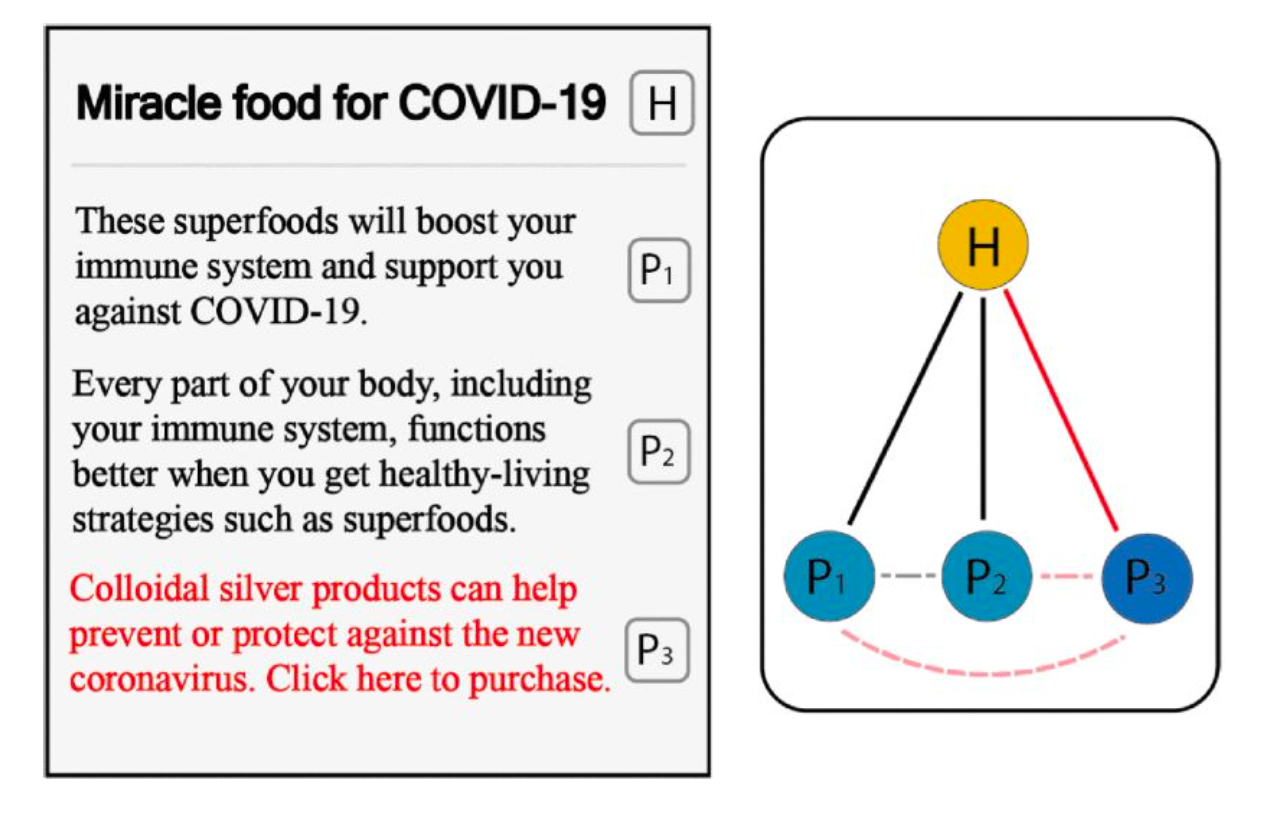
이 연구에는 Deep Hierarchical Encoder(DHE), 그리고 Graphical Neural Network(GNN)이라는 두 딥러닝 모델이 각각 사용되었습니다. 기사는 헤드라인 그리고 본문 안의 문단 여러 개로 이루어져 있는 구조라는 점에 착안하여 모델이 디자인되었다는 점이 특징입니다.
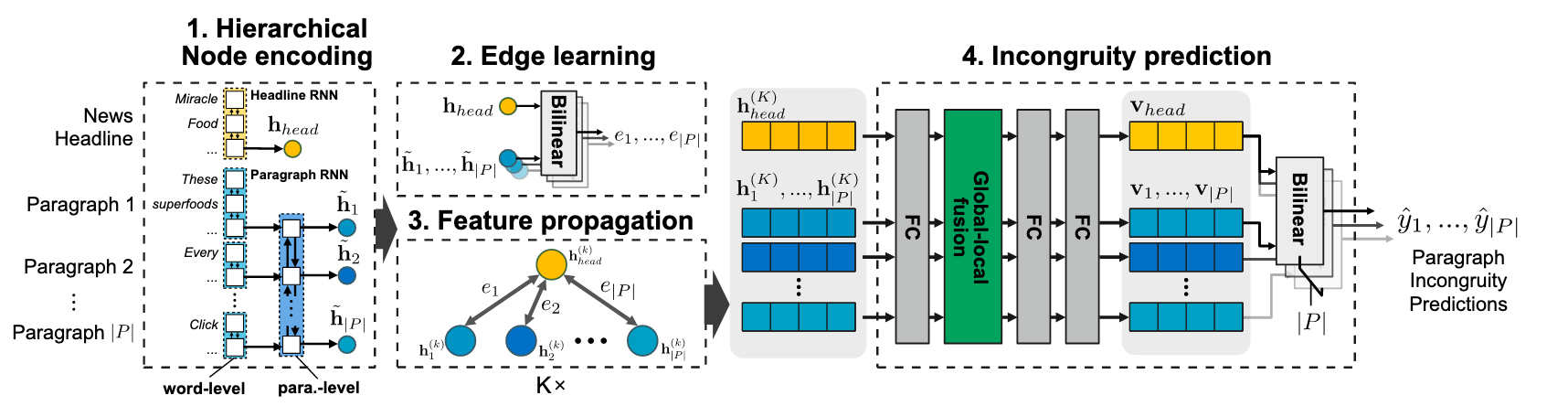
이 두 모델 구조는 신문 기사의 구조를 잘 반영하는 디자인이라 XGBoost, Attentive hierarchical dual encoder, BERT 등 다른 모델 구조에 비교해서 좋은 성능을 보여줍니다. 문제에 사용되는 데이터의 특징을 잘 이해하는 것이 굉장히 중요하다는 것을 보여주는 것 같습니다.
데이터가 없어도 만들어서 쓰면 돼
제가 이 연구에서 가장 인상 깊다고 생각한 부분은 바로 학습 데이터를 확보한 부분입니다. 특히 지난번 <모델 중심에서 데이터 중심 AI> 이라는 세미나 리뷰에서 데이터의 중요성을 강조했었죠.
낚시성 기사에 대한 데이터를 어떻게 구할 수 있을까요? 가장 먼저 떠오르는 것은 뉴스 포털에 들어가 기사를 수집한 후 사람 라벨러에게 낚시성인지 아닌지 판단하게 하는 것 입니다. 그런데 이렇게 할 시에는 아마 수천, 수만개의 기사를 검토해야만 겨우 몇십 개의 데이터를 수집할 수 있을 것 같습니다. 낚시성 기사가 큰 문제이긴 해도 전체 기사 중의 비율로 따지면 꽤 적기 때문이죠. 이런 경우에는 데이터를 구축하는데 비용과 시간이 만만치 않게 들어갈 것입니다.
네이버나 다음 같은 경우에는 "신고"가 있기 때문에 이를 잘 활용한다면 좀 더 효율적으로 데이터를 구축할 수도 있을 것 같습니다. 하지만 이러한 경우가 아니라면 어떻게 데이터를 확보할 수 있을까요? 바로 합성 데이터(sythetic data)를 활용하는 것입니다.
이 연구에서는 아주 직관적인 방법으로 데이터를 합성합니다. 하나의 기사 사이에 다른 기사의 문단을 끼워 넣고 이를 낚시성 기사라고 학습을 시키는 것입니다. 이런 방법으로는 무제한의 학습 데이터를 확보할 수 있겠죠?
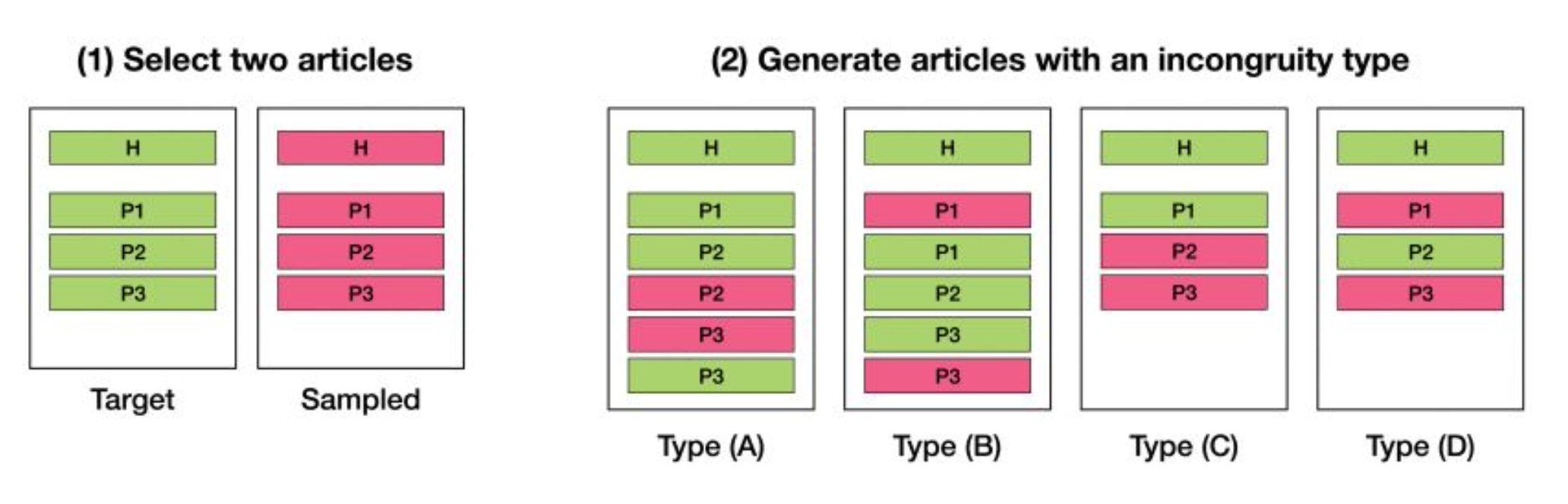
다만 합성 데이터를 사용할 때는 실제 데이터에 적용했을 때의 성능을 조심히 살펴보아야 합니다. 진짜 데이터가 아니라 가짜이기 때문에 괴리감이 있을 수도 있기 때문이죠. 이에 대한 자세한 내용은 아래 저자 분들의 코멘트와 원 논문을 참고하시길 바랍니다.
저자들과의 인터뷰
안녕하세요, 자기소개 부탁드립니다.
(건우) 안녕하세요. 숭실대학교 AI융합학부에서 연구하고 있는 박건우입니다. NLP 및 멀티모달 딥러닝 기술 기반으로 온라인 환경에서 나타나는 사회 문제를 해결하는 것을 목표하고 있으며, 주로 뉴스와 소셜 미디어 데이터를 다루고 있습니다.(승현) 안녕하세요 Adobe Research NLP팀에서 연구하고 있는 윤승현 입니다. 질의응답 시스템에 관련된 연구를 진행하고 있고, NLP/AI 기술을 이용해서 사회 문제를 해결하는 부분에도 관심이 많이 있습니다.
저널리즘 x NLP라는 토픽에 어떤 계기 또는 동기로 연구를 하게 되셨나요?
저희는 웹 환경 내 사람들의 행동 기록/콘텐츠 패턴 등을 분석하고 모델링하는 연구(건우), 그리고 질의 응답 시스템을 비롯한 자연어처리 연구(승현)를 주로 해 왔습니다. 연구를 하는 데 있어, 항상 어떤 것이 의미있고 사회에 도움 되는 방향일까를 고민하던 중, 2016년 미국 대선 이후 가짜뉴스 문제가 사회적으로 대두되는 것을 보았습니다. 가짜 뉴스, 낚시성 기사 등 낮은 퀄리티의 기사를 탐지하는 NLP 기술을 개발한다면 우리가 매일 접하는 뉴스 환경을 좀 더 바람직한 방향으로 나아갈 수 있도록 기여할 수 있을 것이라고 생각하여 저널리즘 x NLP 연구를 시작하게 되었습니다.
조금 더 구체 사례를 들면, 저희가 뉴스 기사를 접할 때 가장 먼저 보게 되는 헤드라인이 독자에게 주는 영향에 관한 선행 연구가 있습니다. 헤드라인이 주는 선입견이 본문을 읽은 과정에서도 많은 영향을 주게 된다는 연구입니다. 따라서 본문을 잘 대변하지 않도록 작성된 헤드라인이 만연해 있다면 잘 못된 선입견이 쉽게 퍼지게 되는 계기가 됩니다. 이는 뉴스 본문을 정독하지 않고, 헤드라인 위주로 뉴스를 소비하는 사회 구성원들에게 더 큰 잠재 위험 요소가 됩니다.
저희 첫 연구는 2019년에 한국어 기사를 주요 대상으로 진행하였는데, 제안한 모델이 실제 환경에서 본문과 연계성이 떨어지는 헤드라인을 포함한 뉴스 기사를 탐지해 내는 것을 확인했습니다. 이후에도 확장 연구를 계속 진행하고 있고, 이번에 소개드릴 연구는 영어 기사를 대상으로 한 연구 결과를 담고 있습니다.
2019 첫 연구는 한국어 데이터를 중심으로 연구 결과를 발표 하고, 이번 연구는 영어 데이터를 중심으로 진행하신 것으로 알고 있습니다. 이러한 결정은 어떤 이유에서 하셨는지 궁금합니다.
저희가 한국 뉴스 미디어 환경에 더 익숙하여 낚시성 기사를 본 경험이 많았었고, 이를 기반으로 학습 데이터를 생성하는 방법을 고안할 수 있었습니다. 한국 뉴스 미디어 환경에서 저희 모델이 효과적인 성능을 내는 것을 경험한 이후, 자연스레 다른 언어의 미디어 환경 개선에도 관심을 가지게 되었습니다. 영미권 뉴스 미디어 환경은 한국만큼은 익숙하지 않았지만 영어 데이터를 기반으로 한 NLP 기술에는 익숙했었고, 관련 연구들을 통해 낚시성 기사가 사회적으로 문제가 되고 있으며 연구가 활발히 되고 있는 것을 알고 있어 영어 데이터에도 적용 및 평가해 보았습니다.
한국어/영어 데이터 차이에 따라 적용 가능한 모델에 차이가 존재하는지 궁금합니다. 현재 제시하신 모델은 언어에 따른 제약이 없어 보이는데, 이러한 연구 방향은 한국어 데이터를 많이 사용하는 NLP 개발/연구 팀에 어떤 시사점이 있을까요?
한 문제를 풀기 위해서는 NLP 분야의 많은 세부 기술들이 유기적으로 연결되게 됩니다 (예를 들면 글에서 문장을 분리해내는 기술, 문장에서 단어(토큰)를 분리해내는 기술, 개체명 인식 기술 등). 이러한 요소 기술들이 많이 발전되어 있는 언어는 (예를 들어 영어), 어떤 문제를 해결하기 위한 좋은 도구들이 갖추어져 있는 환경이라 생각됩니다. 안타깝게도 한국어는 관련 기술 연구 및 공유가 상대적으로 부족합니다.
하지만 좋은 도구들이 아직 부족한 언어 환경이라도 데이터 구조 분석을 바탕으로 모델을 만들어 연구를 진행할 수 있다고 생각합니다. 아마도 저희가 기반을 둔 딥러닝 기법이 많은 데이터를 바탕으로 타겟팅 하는 패턴을 찾아내는데 효과적이어서 그런 것 같습니다. 이 경우 향후 좋은 기반 기술의 발전이 이루어지면, 해당 기술을 도입하여 저희 모델의 성능을 더 향상 시킬 수 있다고 생각합니다. 최근에는 한국어 관련 NLP세부 기술들이 기업 차원에서도 많이 연구되고 공개되고 있어서 점점 환경이 좋아지고 있는 것 같습니다.
합성 데이터(Synthetic data)를 생성한 후 학습한 모델이 현실 데이터에도 훌륭한 성능을 보인 것이 이 연구의 가장 큰 기여가 아닌가라는 생각을 하였습니다. 어떤 문제나 상황일 때 합성 데이터를 사용하는 것을 고려해야 할지, 사용한다면 고려해야 하는 점(ex. 데이터 디자인 시, 평가 시 등)이 무엇일까요?
라벨 데이터를 얻기 어려운 상황이면 합성 데이터를 만들 수 있을지 고민해보면 좋을 것 같습니다. 많은 경우 크라우드소싱 등을 이용해 라벨을 획득하지만 퀄리티 컨트롤이 어렵고, 많은 파라미터를 가지고 있는 모델을 학습할 정도의 충분한 데이터를 확보하기엔 비용과 시간이 많이 요구됩니다. 이런 경우 합성 데이터를 만들 수 있다면 위 문제를 해결 또는 완화할 수 있습니다.
또한 저희 연구처럼 저널리즘과 같은 분야를 목표로 하게되면, 시대마다 주요한 토픽과 글을 쓰는 패턴이 달라질 수 있음을 항상 생각해야 합니다. 언어는 구성원들의 공감과 사용 빈도에 따라 조금씩 변하기 때문에, 관련 문제를 타겟팅하는 모델도 이에 맞추어 주기적으로 업데이트를 해주어야 합니다. 이 경우마다 새로운 라벨 데이터를 생성해야한다면 지속성을 가지기에 어려움이 있을 것 같습니다. 이런 경우 효과적인 합성 데이터 생성 방법이 있다면 이 문제를 어느정도 완화 시킬 수 있다고 생각합니다.
합성 데이터는 실제로 존재하지 않는 데이터를 가상으로 만들어 낸 것이기 때문에, 생성한 데이터가 목표하는 라벨을 잘 대표하는 지 논리적 검증과 함께, 실제 사용자를 대상으로 한 평가도 필수적으로 이루어져야 할 것입니다. 이 경우 샘플링을 통해 얻어진 일정 양의 데이터에 대해 전문가를 고용하여 매뉴얼 검증을 진행하거나, 크라우드소싱을 활용하여 다수의 의견을 들어 볼 수 있을 것 같습니다. 또한 합성 데이터를 학습한 모델을 실제 데이터에 적용했을 때 목표하는 문제를 잘 푸는 지 다각도 평가가 필요합니다.
Deep Hierarchical Encoder(DHE)와 Graphical Neural Network(GNN)라는 모델링에서의 개선 뿐만 아니라, 합성 데이터를 디자인해 생성 및 Data Augmentation을 통해 데이터 측면에서의 개선까지 제시했다는 점에서 굉장히 알찬 연구라고 느꼈습니다. 최근에 앤드류 응 교수가 세미나를 통해 모델 중심에서 데이터 중심의 AI로 가야한다는 이야기를 하였는데요. 이러한 관점에 대해 어떤 생각을 가지고 있으신지 궁금합니다.
감사합니다. 저희도 앤드류 응 교수님께서 말씀하신 방향에 크게 공감하고 있으며, 크게 두 가지 관점에서 데이터 기반 AI로 나아가야 한다고 생각합니다. 첫째로, 모델 학습 및 활용에 앞서 효과적인 데이터 전처리가 이루어져야 할 것입니다. 이 연구에서도 각 뉴스 미디어에서 일괄적으로 넣는 기사 시작 문구, 기자 이름 등을 제거하였을 때 학습된 모델의 성능을 유의미하게 향상시킴을 발견하였습니다. 둘째로, 데이터의 특징에서 영감을 얻어 AI 모델을 보다 효과적으로 설계할 수 있을 것입니다. 이 연구에서 저희는 뉴스 기사가 본문-문단-문장의 계층적인 구조를 지니고 있음에 착안하여 Hierarchical Encoder를 설계하였고, 최근에 진행한 연구(IEEE Access)에서는 이 구조를 그래프 형태로 표현한 모델로 더 큰 성능의 개선을 이루었습니다. 실제로 구체적인 문제 해결을 목표하거나 서비스에 적용할 때는 타겟 도메인의 데이터 특성을 고민하고 모델 설계에도 활용하였을 때 더 효과적인 AI개발이 가능하다고 생각합니다.
이 연구의 모델을 사람들이 실제로 이용할 수 있는 서비스로 만들 계획이 있으신가요? 그렇다면 어떤 형태가 될까요?
저희가 개발한 딥러닝 모델의 예측 결과를 사람들에게 미리 알게 해주면, 실제 사람들이 제목과 본문이 다른 내용을 다루는 소위 낚시성 기사들을 거르는 데 도움을 줄 수 있을 것이라 생각합니다. 하나의 proof-of-concept 으로 저희는 BaitWatcher라는 웹 브라우저 익스텐션을 개발하여, 사람들이 뉴스를 선택하기 위해 마우스 커서를 뉴스 제목에 위치하면, 기사를 클릭하기 전 모델의 예측 결과를 말풍선 형태로 보여줄 수 있도록 하였습니다. 이 프로그램의 효과를 검증하기 위해 소규모 유저 테스트도 진행하였고, 많은 참가자가 뉴스를 선택하는데 도움을 준다고 답하는 등 긍정적 답변을 얻었습니다. 하지만, 몇몇 참가자는 왜 모델이 낚시성이라고 판단하였는지 궁금해하는 등 실제 서비스로 적용할 때는 모델의 interpretability, explanability가 중요한 요소가 될 것이라는 숙제를 얻기도 했습니다. 저희 모델이 실제 뉴스 데이터에서도 괜찮은 성능을 보여주고 있으나 아직 실제 서비스화를 계획하고 있지는 않습니다. BaitWatcher 프로그램과 실험 내용은 코드와 논문으로 공개되어 있습니다.
이러한 훌륭한 저널리즘 x NLP 연구를 하고 싶은 사람이라면 어떻게 해야할까요? 함께 하고 싶다면 누구에게 연락을 해야할까요?
NLP 및 딥러닝 기술을 공부하는 것 뿐 아니라 다른 분야의 문제에도 열린 마음을 갖고 도전하는 마인드셋이 중요하다고 생각합니다. 따라서 저널리즘 뿐 아니라 각자가 관심있는 분야의 문제를 데이터와 AI 기술을 이용하여 해결하려 할때 의미있는 진보를 만들어낼 수 있을 것이라 생각합니다. 다만 단순한 논리적 사고, 즉 도메인 분야의 깊은 고민이 결핍된 educated guess 만을 갖고 문제를 접근하려다 보면 실제 해당 분야에서 다루어온 연구들을 간과할 수 있기 때문에, 해당 분야의 전문가분들과 협업하고 연구도 살펴보고 하는 것도 중요하다고 생각합니다.
저희는 NLP 및 딥러닝 기술을 활용하고, 목표 분야의 전문가들과 협업하여 사회적 문제를 해결하기 위한 연구를 계속하려 합니다. 저널리즘 x NLP 분야의 또다른 연구를 계획중에 있고요. 저널리즘이 꼭 텍스트로만 이루어져 있지는 않기 때문에 향후 연구는 image/video/text 와 같이 여러 종류의 형태를 복합적으로 고려하는 방향의 연구도 계획하고 있습니다. NLP/AI 기술을 갖고 계시며 사회적으로 의미 있는 일을 하고 싶으신 분들은 저희와 함께 연구하면 좋을 것 같습니다. 한국에 계시다면 숭실대학교 HUMANE랩에 단/장기 방문하셔도 좋을 것 같네요 ^^ 언제든 대화 및 협업 환영입니다!
(박건우 교수님 홈페이지, 이메일: bywords.kor@gmail.com; 윤승현 연구원님 홈페이지, 이메일: mysmilesh@gmail.com)
오늘은 낚시성 기사를 걸러내는 NLP 모델에 대해 알아보았습니다. 두 저자분들의 깊은 인사이트를 인터뷰를 통해 더 많은 것을 배울 수 있었습니다. 어서 빨리 서비스화 되어 질 낮은 기사로 시간 낭비하는 일이 없었으면 좋겠다는 마음입니다.
다음에는 <저널리즘 x NLP> 시리즈로 이어서 팩트체크에 관련된 연구에 대해 이야기하려고 합니다. 이 시리즈로 보고 싶은 주제나 연구가 있다면 댓글로 남겨주세요!

Reference
- Yoon, Seunghyun, et al. "Detecting incongruity between news headline and body text via a deep hierarchical encoder." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. No. 01. 2019.
- Yoon, Seunghyun, et al. "Learning to Detect Incongruence in News Headline and Body Text via a Graph Neural Network." IEEE Access 9 (2021): 36195-36206.