Week 41 - CSI 과학수사대가 탐낼만한 NLP + Vision 기술


저는 아이언맨이나 베트맨 같은 히어로물보다 미국 TV 드라마 CSI 과학수사대 시리즈를 더 좋아합니다. 보면서 과학 기술이 범죄자들을 잡아내는 것에 희열을 느낍니다. 특히 지문 같은 어떤 증거를 가져와서, DB 검색을 돌리는 장면, 특히 큰 화면에 엄청난 양의 데이터가 후루룩 지나가다가 "매치"라고 나오는 비주얼이 너무 멋있었죠. "잡았다 요놈" 같은 느낌이랄까요.
다만 현실과 드라마는 다르다는 것을 알 수 있습니다. 특히 저는 군복무를 육군 헌병본부의 과학수사대에서 사이버수사병으로 복무하였는데, 실제로 이러한 수사를 위한 DB 검색은 현실보다는 희망사항에 더 가깝다는 것을 알게 되었습니다. 물론 실제 우리나라나 해외에 경찰 수사 기술은 빠르게 발전하고 있겠지만요.
그런데 AI를 범죄 수사에 활용하면 좋겠다라는 생각을 들게 한 연구 주제를 최근에 알게 되었습니다. CSI에서 용의자의 차량을 알아내고 반장이 CCTV 상황실에 가서,
"빨간색 SUV 차량, 오른쪽 범퍼에 찌그러진 자국이 있을꺼야"
같은 얘기를 하면 한 10초안에 바로 그 차량을 찾아내는 장면이 종종 나옵니다.
근데 생각해보면 마이애미든 뉴욕이든 LA이든 엄청나게 차가 많은 대도시인데, 어떻게 그렇게 빨리 그 차를 잡아낼 수 있었을까요? 원래 정답은 "드라마라서"였지만, 이러한 것을 가능케하는 기술이 연구 되고 있습니다.
바로 자연어 기반 차량 검색(Natural language based vehicle search) 입니다.
유명한 국제 컴퓨터 비전(Computer Vision) 컨퍼런스 CVPR에는 여러 워크샵도 열리는데, 올해에는 도시의 교통 CCTV 데이터를 가지고 한 AI City Challenge 라는 워크샵이 있었습니다.
여기에 한국에서 직장을 다니면서 한 사이드 프로젝트로 챌린지 대회에 참가하시고 논문까지 게재하신 분들이 계셔 제가 <위클리 NLP>에 소개하려고 합니다.
이번 글에는 "수많은 CCTV 비디오에서 내가 원하는 차량을 말로 설명하면 찾을 수 있을까?"라는 질문에 대한 기술을 소개하고, 이를 해결하려고 한 논문 SBNET과 저자 분들의 인터뷰를 소개합니다.

멀티 모달(MULTI-MODAL PROBLEM)
지난 Week 40 에서 텍스트에서 이미지를 생성하는 모델 DALL-E를 소개하면서 이렇게 텍스트와 이미지 같이 다른 형태의 인풋을 함께 다루는 문제를 멀티 모달(Multi-modal)이라고 설명드렸습니다.
특히 요즘 제가 NLP + ? 에 관심이 많아졌습니다. 가장 흔하게 접해왔던 연구는 NLP + 음성(Speech)입니다. 음성인식 같은 기술은 워낙 오래 전부터 연구되어왔던 문제이고, 인간은 넘어설 정도로 많은 발전을 해오고 있습니다 (Week 15, Week 16 참고).
그런데이 "자연어 기반 차량 검색" 문제는 DALL-E와 마찬가지로 NLP와 Vision을 합친 문제입니다. 텍스트로 검색하여 비디오에서 원하는 장면을 찾고, 원하는 차량 부분을 찾아야 하기 때문이죠. (참고로 비디오는 연속된 이미지 프레임으로 처리된다고 이해하시면 됩니다)
자연어 기반 차량 검색 문제
일단 이 문제가 어떤 것인지 한번 볼까요?

좌측에 나온 텍스트와 오른쪽에 나온 이미지가 모델에 들어가는 input이고, 그리고 가운데의 히트맵은 예측해야하는 정답(output)입니다.
문제를 두 가지 부분으로 나눌 수 있겠네요.
1) 비디오 중에서 알맞는 비디오, 그리고 그 안의 이미지 프레임을 찾고 (retrieval),
2) 이미지에서 원하는 차량 부분을 찾는다 (mask prediction; segmentation).
이렇게 문제를 바라보니깐 참 쉽지가 않아 보입니다. 일단 비디오에 차량이 여러 개가 있을 수도 있고, 교통 상황 (ex. 교차로, 신호등, 보행자 등)에 대한 이해도 있어야 할 것 같습니다. 특히 이러한 비주얼적인 이해뿐만 아니라 언어에 대한 이해까지 더해지니 굉장히 쉽지 않은 문제라는 것을 알 수 있습니다.

END-TO-END MULTI-TASK 모델
End-to-end(E2E)
머신 러닝에서 End-to-End(E2E) 모델이라는 것은 input과 output 사이를 모두 학습되는 파라미터로 구성하는 것을 말합니다. 사람이 손으로 어떠한 규칙이나 휴리스틱을 주는 것이 아니라 전부 데이터로부터 모델을 학습시키는 방식이죠. 딥러닝이 떠오르고 나서는 이러한 E2E로 모델링하는 것이 딥러닝 연구에서는 꽤 일반적인 방식이 되었습니다.
제가 소개하는 논문 SBNET의 연구자분들도 이러한 방식을 채택하고 있습니다.
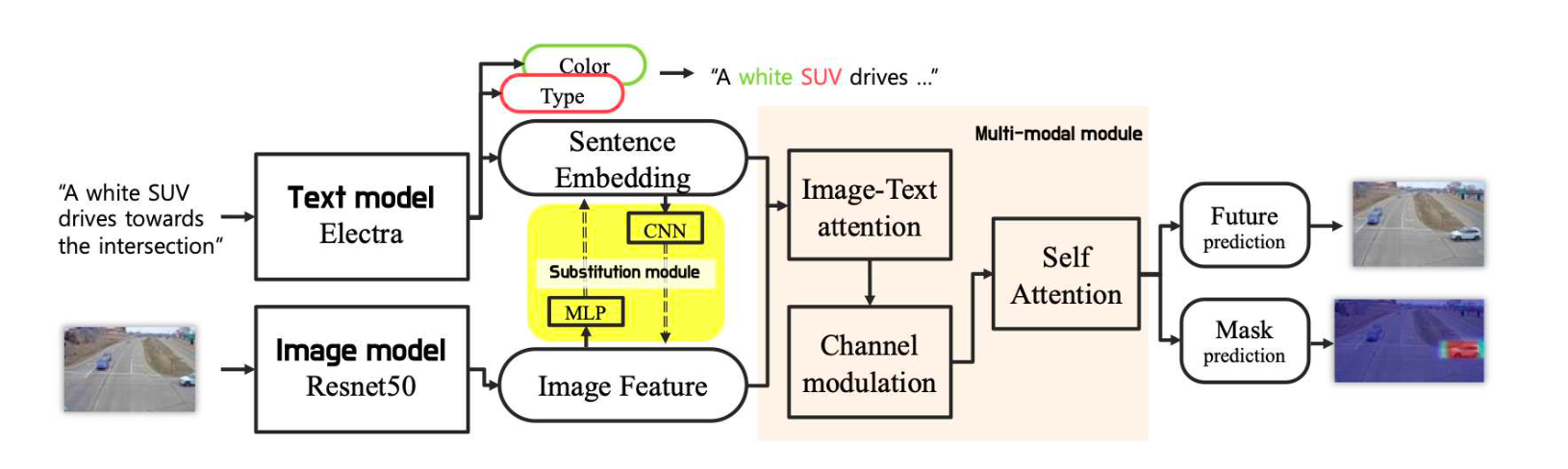
input인 텍스트와 이미지를 각각 NLP 모델인 Electra와 CV 모델인 Resnet에 인코딩을 한 후, 추후 이를 함께 섞어 최종 예측을 하는 한 개의 큰 모델로 구성하였습니다.
멀티 테스크(Multi-task)
SBNET 또다른 특징 중 하나는 모델에게 여러 가지 문제를 주어 학습시킨다는 점입니다. 가장 중요한 메인 테스크(Main task)는 이미지에 차량 부분을 찾는 Mask Prediction이겠죠. 그 외에 SBNET은 더 정확한 학습을 위해 두 가지 사이드 테스크(side task)를 선택하였습니다.
1) 차량의 색깔과 종류가 무엇인지 (Classification Module)
2) 다음 장면은 어떻게 진행될 것인지 (Future Prediction Module)
이렇게 사이드 테스크를 줌으로써 모델이 메인 테스크를 더 잘할 수 있게 하는 것을 멀티 테스크 러닝이라고 합니다. 1)은 모델에게 어떤 단어가 차량의 색깔이고, 어떤 단어가 차량의 종류인지 좀 더 직접적으로 알려줄 수 있고, 2)은 앞서 말한 교통 상황에 대한 비쥬얼적인 이해를 학습시키는데 도움을 줄 수 있지 않을까라는 모델링 판단이 들어간 것으로 보입니다.
**그 외에도 Representation Learning 차원에서 텍스트와 이미지 인코딩을 비슷하게 만드려는 Substitution 모델, 멀티모달 Attention 모델 등 다양한 세부 모델링에 대한 디테일이 있으니 관심있으시면 원 논문을 읽어보는 것을 추천합니다!
저자들과의 인터뷰
안녕하세요, 간단하게 자기소개 부탁드립니다.
안녕하세요, 모두의연구소에서 vital랩에 참여하고 있는 이상록, 우태강, 이상헌이라고 합니다.
이상록: 저는 현재 스타트업에서 머신러닝 업무를 하고 있고 vital랩에서 랩장으로 활동중입니다.
우태강: NAVER 쇼핑에서 머신러닝 엔지니어로 일하고 있습니다.
이상헌: 국민대학교 자동차융합학과에서 교수로 재직중입니다.
(필자: 모두의연구소에서의 이 프로젝트에 대해 소개한 브런치 글: 취미로 연구하다 논문까지 썼다고? 도 일독을 추천합니다)
이 토픽은 어떤 계기 또는 동기로 연구를 하게 되셨나요?
Natural language based vehicle search는 AI City workshop과 함께 열린 challenge에서 제안한 연구주제입니다. 저희는 지난해 동일한 워크샵에서 같은 차량을 찾는 vision based vehicle re-identification에 참여를 했었습니다. 해당 대회를 하고 논문을 쓰면서 자연어로 이미지에서 차량을 찾는 주제도 정말 재미있겠다는 생각을 했었습니다. 마침 이번해에 이 주제로 대회가 열렸고 흥미로워 보여서 참여했습니다. 만약 실제로 사용한다면 "자연어로 검색하는 쪽이 더 활용가능성이 높지 않을까?" 라는 생각도 참여를 결심한 동기중 하나입니다.
텍스트와 이미지라는 아주 다른 두 모달(modal)의 데이터를 함께 다룰 때 어려운 점/재밌는 점이 무엇일까요?
첫 번째로, 이미지에서 임베딩되는 피쳐와 자연어에서 임베딩되는 피쳐가 근본적으로 분포가 다르다는 점이 어려웠던 것 같습니다. 저희는 이를 극복하기 위해 relational reasoning에서 쓰던 FILM과 같은 모델의 구조를 참고 했었습니다.
두 번째로, 요즘은 트랜스포머로 통일되는 추세지만 이미지와 자연어에서 쓰이는 모델이 좀 많이 다르다는 것도 어려운 점인 것 같습니다. 저희도 트랜스포머를 이용해 통합적인 모델을 사용해보려고 시도했었는데 아무래도 다들 직장인이라 trial-and-error를 할 시간이 부족해 resnet + electra 두 구조를 사용했습니다.
세 번째로, 자연어와 이미지 데이터 둘 다에 관해 어느정도 지식이 있어야 한다는점이 좀 어려웠습니다. 먼저 데이터에 관한 인사이트를 얻기 위해 자연어와 이미지를 다 한번 쭉 봤었는데 노이즈가 많아서 그걸 처리하는 도메인 지식을 습득하느라 시간이 좀 걸렸었습니다.
이미지와 자연어는 함께 다룰 때 더 재미있는 task(VQA, VizWiz.. etc)를 많이 수행할 수 있는 것 같습니다. 또 (두 가지 종류의 인풋을) 함께 사용하면 TLDR: "Watching videos can help language understanding"이런 논문처럼 기존에 불가능했던 서로간의 상승작용을 찾을 수 있는 것 같기도 하고요.
연구하신 Natural languaged-based image retrieval은 CCTV 영상에서 차량을 찾는 문제 외에 어떤 응용 어플리케이션이 있을 수 있을까요?
(태강) 인터넷 쇼핑할 때, 특히 의류나 잡화 같은 상품을 찾을 때 상품 이미지를 보고 결정을 내립니다. 최근에는 네이버 스마트렌즈나 구글이미지검색 같이 이미지 검색 자체도 사용되어가는 추세이지만 여전히 대부분의 검색은 자연어처리가 사용됩니다. “하늘하늘한 꽃무늬 원피스" 같은 검색어를 이용해서 쇼핑검색을 사용하는 것이 대표적입니다.
언어는 이미 사람이 digitize 한 결과이기 때문에 continuous signal 인 이미지보다 생성하기 쉬운 장점이 있습니다. (생각을 언어로 표현하는 것보다 그림그리는 것이 오래 걸리니까요.) 따라서 이미지를 언어로 표현하는 모든 어플리케이션에 응용가능하다고 생각합니다.
이 논문은 CVPR 학회 워크샵의 AI City 챌린지라는 대회 결과인데요. 대회를 참가한 경험이 어땠는지, 이러한 챌린지 형식으로 여러 팀이 경쟁하는 형식에 대한 생각, AI/ML에 입문하려는 분들에게 추천을 하시는지 의견이 궁금합니다.
저는 챌린지라는 형식이 경쟁을 통해 기존의 연구상황과 다른 환경을 만들어서 결과를 더 좋게 만드는것 같습니다.학회의 challenge가 kaggle과 같이 토론이 가능한 것은 아니라 조금 답답하긴 하지만 결과가 논문으로 남는 것도 장점입니다. (요즘은 challenge 자체를 kaggle 플랫폼에서 여는 경우도 있긴 합니다).하지만 짧은 기간에 많은 시간을 투입해야 해서 저희같이 퇴근 후 연구를 지향하는 사람들은 상위권을 노리긴 힘들었습니다.어느정도 공부가 되신 분들에게 challenge나 kaggle같은 대회는 적극 추천하고 싶습니다.
최종 예측의 정확도를 높이기 위해 차량 색이나 종류 맞추기, 미래 프레임 예측하기 등 여러 가지 다른 보조 문제를 추가하는 방식인 멀티 태스크(multi-task) 러닝을 쓰신 것이 인상이 깊었습니다. 이러한 멀티 태스크 러닝에서 보조 문제를 어떻게 선정하는게 좋은지, 이러한 모델 구조를 사용할 때 신경을 써야 하는 점이 있을까요?
1. 차량을 구분하는데 색이나 타입은 필수적인 요소이기 때문에 해당하는 multi task를 넣었습니다. 사실 사람의 판단에 의해서 task를 넣었을 때 결과가 나쁜 경우도 있어서 어떤 것이 정답이다 말하긴 어려운 것 같습니다.
2. 저희 논문의 방법처럼 main task를 위한 sub task를 여러개 더해 multi task 러닝을 하는 경우 sub task가 main task를 방해하지 않게 만드는 것이 중요한 것 같습니다. sub task는 성능이 높지 않아도 main task의 성능을 높이는 역할만 하면 되기 때문에 loss에서 그걸 컨트롤하는게 중요했습니다. 저희는 그리드 서치를 사용해서 각 loss별 비중을 조절했는데Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics 과 같은 논문처럼 휴리스틱하지 않은 방법으로 각 loss별 비중을 조절하는 것도 괜찮은 방법입니다.
3. 첨언하자면 multi task가 아니라 pre-text task로 self supervised learning을 써서 representation 능력을 높이는 것도 요즘 유행하는 잘 먹히는 방법이라 생각합니다. (저희는 시간도 없고 두번 학습하기가 너무 피곤해서 그냥 multi-task를 썼습니다)
오늘은 자연어 기반 차량 검색이라는 재밌는 멀티모달 연구에 대해 알아보았습니다. 직장도 바쁘실텐데 사이드 프로젝트로 연구를 하시는 저자 분들이 너무 멋지다고 느꼈고, 이렇게 <위클리 NLP>에서 소개까지 하게 되어서 감사하고 영광인 마음입니다.
계속 이렇게 다른 분들의 연구나 프로젝트도 소개를 하려고 합니다. 이미 지난 Week 34, Week 37, Week 38 에 이어 4번째 인터뷰 컨텐츠를 하였습니다. 혹시라도 피드백이 있거나 본인의 연구 역시 이런 협업으로 소개하고 싶으시다면 꼭 댓글이나 이메일로 연락해주시기 바랍니다!
지난 글부터 이렇게 NLP + ? 의 멀티 모달 연구에 관심이 많이 생겨서 이렇게 계속 보고 있습니다. 계속 이쪽으로 살펴볼 예정인데, 소개하면 좋을만한 연구가 있어 알려주시면 피드백을 반영하도록 하겠습니다!




