Week 8 - 스팸 이메일 분류기 만들기


여러분의 이메일 받은 편지함은 얼마나 빨리 쌓이시나요? 저는 이것저것 가입하다 보니깐 하루에도 홍보성 이메일이 수십 개가 오고는 합니다. 저는 앱 아이콘에 숫자가 그려져 있는 것을 견디지 못해서 전부 지우거나 몇 개는 그러다 가끔 읽어보기도 합니다. 중요한 이메일을 놓칠까 봐 조마조마하면서 읽다 보면 시간도 생각보다 많이 낭비되고요.
오늘은 NLP 기술로 여러분의 편지함에서 스팸을 걸러낼 수 있는 감지 모델 (spam detection)을 만들어보려고 합니다. 이미 Gmail 같은 서비스에는 이러한 기술들이 널리 쓰이고 있습니다. 이 글에서는 기본적인 통계 모델 Naive Bayes Classifier를 사용해보려고 합니다.

이것도 이분법(binary classification) 으로?
Week 6에는 문서 분류에 대해서 배워보았습니다. 특히 가장 간단한 0이냐 1이냐의 이분법 (binary classification)을 logistic regression이라는 통계 모델을 가지고 학습시키는 예시를 보았지요. Spam detection도 이분법으로 나눌 수 있을까요?
문제는 우리가 어떠한 데이터를 가지고 있냐입니다. 영화 리뷰를 긍정이냐 부정이냐로 나눌 때에는 부정 (negative; 0)과 긍정 (positive; 1)의 학습/평가 데이터 셋을 가지고 있었지요. 스팸 이메일 역시 이러한 학습 데이터가 필요합니다. 스팸이 아닌 이메일 (negative; 0), 그리고 스팸 이메일 (positive; 1). 이러한 데이터를 가지고 있다면 바로 binary classification 문제로 정의하고 해결책을 찾아볼 수 있습니다.
**이런 식으로 데이터에 정답 (label)이 붙어 있는 것을 supervised learning(지도 학습)이라고 합니다.
만약 그러한 데이터가 없다면 어떻게 하냐고요? 그렇다면 두 가지 방법이 있습니다.
첫 번째 가장 쉬운 방법은 지금 이메일함에 들어가서 몇 백개의 이메일을 가져온 다음에 스팸인지 아닌지 직접 분류를 하는 것입니다. 이를 human annotation 또는 data labeling 합니다. 통계 모델을 학습시킬 정도의 규모가 될 때까지 직접 사람이 학습 데이터를 만들어 내는 것입니다.
세상에는 labeling 되지 않은 데이터가 엄청나게 많습니다. 이메일 같은 경우에도 여러분의 편지함에 엄청나게 쌓여 있지만 어떤 것이 스팸인지 아닌지는 labeling 하기 전에는 알 수가 없지요. 이러한 labeling 과정이 보통 머신러닝 모델 개발에 가장 큰 비용과 시간이 들어갑니다. 그렇기 때문에 크라우드소싱을 이용한 crowdworker 서비스를 통해 노동력이 싼 개발 도상국의 인력을 이용하기도 하지요. 이에 대해서는 다른 글에서 다뤄보도록 하겠습니다.
네이버나 구글 같은 서비스들은 유저들이 스팸이라고 신고해주는 데이터를 많이 활용하지 않을까 조심스럽게 예측해봅니다.
두 번째 방법은 anomaly detection이라는 테크닉입니다. anomaly는 변칙이라는 뜻인데, 데이터 전체를 보았을 때 다른 데이터 포인트들과 아주 동떨어진 놈들을 찾아내는 것입니다. 이는 데이터 자체를 보기 때문에 label이 따로 필요하지 않습니다. 다만 데이터의 특성에 따라 성능의 차이가 많이 날 수 있고, 제대로 평가하기가 힘들 수 있습니다. 예를 들어, 저에게 유용한 이메일들이 대부분 비슷한 주제로만 이루어져 있다면, 갑자기 다른 주제인 스팸을 찾아내는 건 쉬울 수 있습니다. 하지만 저의 이메일들이 매우 다양한 주제를 가지고 있다면 이러한 모델로 스팸을 찾아내는 것은 어려울 수도 있습니다.
** 이 방식은 label이 따로 필요하지 않는 unsupervised learning(비지도 학습) 중 하나 입니다.
그렇기 때문에 우리는 데이터가 있다고 가정을 하고 첫 번째 binary classification으로 문제를 접근하기로 합니다.
다시 가방을 꺼내보자
Week 2에서 소개한 Bag-of-words (BoW)는 하나의 문서나 문장에 들어 있는 단어들을 순서와 상관 없이 하나의 vector로 표현하는 방식 입니다. 하나의 이메일 역시 이러한 방법을 표현될 수 있습니다.
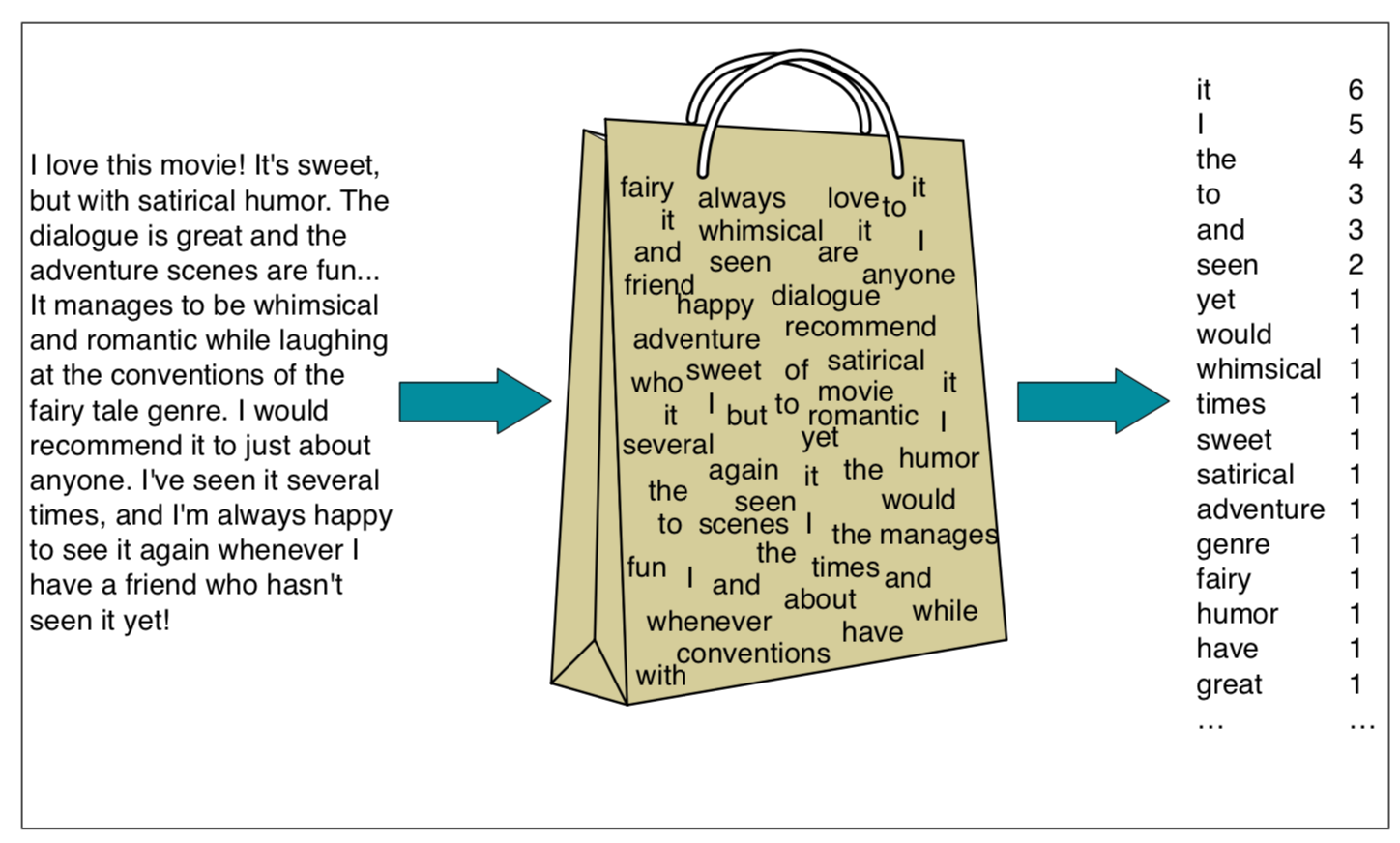
이번에 소개시켜드릴 모델은 Multinomial Naive Bayes classifier 입니다. 이름은 길지만 사실은 확률과 통계 시간에 배운 베이즈 정리(Bayes Rule) 만 아신다면 매우 쉬운 모델입니다. 베이즈 정리는 Prior probability (사전 확률)와 posterior probability (사후 확률)의 관계를 나타내는 정리인데 기억을 되살리시고 싶으신 분들은 이 블로그를 참조해주시기 바랍니다.
간단한 수학 식을 꺼내서 설명드리겠습니다.
c : classifier가 선택할 수 있는 class (우리의 경우 binary이기 때문에 스팸이냐, 아니냐 두 개의 class입니다)
d : document (이메일)

위 수식을 말로 풀어 설명하자면 어떤 이메일 (d)이 주어졌을 때, 이 이메일이 스팸인지 아닌지 (c=0? c=1?) 각각 확률을 계산한 후, 더큰 큰 확률을 가진 c를 찾습니다. 수식을 직역해서 말이 조금 어려운데, 결국 "이 이메일 그냥 스팸일 확률이 높아? 아닐 확률이 높아?" 라는 소리입니다.
P(c|d)는 베이즈 정리를 통해 이렇게 바꾸어질 수 있습니다.
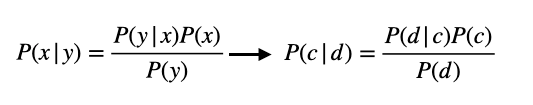

그렇다면 남는 것은 이 두 가지 항목인데요:
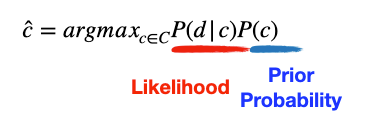
각각 설명을 해볼까요~
P(c) : prior probability
조금 더 간단한 P(c) 부분부터 볼까요? P(c)는 이메일(d)과 상관 없이 classifier가 선택할 수 있는 class의 확률, 사전 확률 (prior probability)라고 부릅니다.. 우리에겐 두 가지 옵션이 있습니다 - 스팸이냐 (c=1) 아니냐 (c=0). 어떻게 하면 이 확률을 계산할 수 있을까요?
아주 간단합니다. 그냥 주어진 학습 데이터에서 스팸의 비율이 얼마인지 계산하면 됩니다. 예를 들어 100개의 이메일 중에 2개가 스팸이라는 것을 알면 P(c=1) = 0.02, P(c=0) = 0.98 이 됩니다. 이메일 내용에 대한 아무런 정보가 없다면 이러한 통계를 알고 있는 것이 유용하겠죠?
P(d|c) : likelihood
Likelihood (가능도)는 어떤 이메일(d)이 스팸 class에서 등장할 가능성을 계산한 숫자입니다. c = 스팸이라고 주어졌을 때, 이 이메일이 작성될 확률을 계산한 것입니다. 조금 헷갈리시죠? 이 이메일이 스팸일 확률을 계산한 것이 아니라, 이미 스팸이라는 가정을 하고 이메일이 쓰여졌다면 얼마나 그럴듯 하냐를 계산한거라 생각하시면 됩니다.
그렇다면 얼마나 그럴듯 하냐는 어떻게 계산할까요. 그건 바로 이메일에 들어가있는 단어 하나하나를 살펴보는겁니다. 혹시 이메일 제목에 "광고", "무료", "보험", "체험", "판매" 같은 단어들이 보이면 바로 스팸으로 여기고 삭제한 경험이 있으신가요? (보험 업종에 종사하시는 분이 있으면 미리 양해 부탁드립니다 ^^)
그것과 같은 원리로 naive bayes classifier는 학습 데이터 중 스팸 이메일들에 들어 있는 단어들에 대한 통계를 확률로 계산합니다. 예를 들어, "보험"이라는 단어가 스팸 이메일 100개 중에 90개에, 보통 이메일의 10개 중에 1번 들어있다고 하면 P(보험 | 스팸) = 90/100 = 0.9로 계산되는 것이지요. 다른 단어들도 각각 이렇게 계산을 합니다.

순진(naive)하게 단어를 바라본다면?
자, 위의 예시 처럼 각 단어들의 확률을 계산해보았습니다. 하지만 우리가 알고 싶은 것은 이메일(d) 에 대한 확률입니다. 각 이메일은 여러 개의 단어들 (w) 로 이루어져있죠. 단어들의 joint probability (결합 확률)은 어떻게 계산할까요.
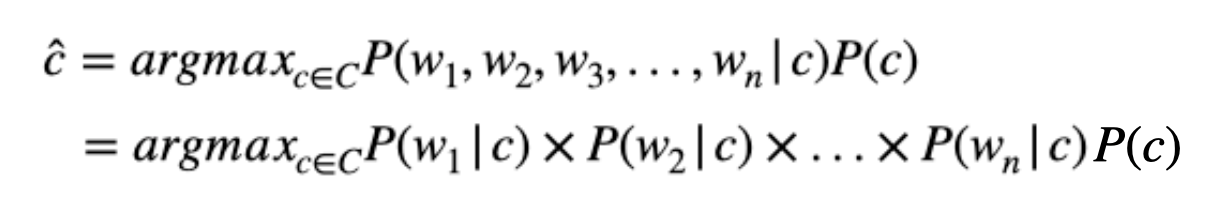
이메일의 joint probability를 제대로 계산하려면 단어의 순서가 중요합니다만, naive bayes classifier는 순서를 무시하고 각 단어들이 independent (독립) 하다는 가정을 넣습니다. 하나의 단어가 발생할 확률이 다른 단어의 영향을 받지 않는다는 것이죠. 사실 이 가정은 이메일 텍스트의 많은 것을 생략합니다. 그렇기 때문에 "naive - 순진하다"라는 이름이 붙은거죠.
하지만 이러한 가정에도 불구하고 간단한 문제에는 꽤나 효과적인 성능을 보입니다. 지난 글에서도 Bag-of-words (BoW) vector가 단순하지만 의외로 좋은 성능을 보인다고 말씀드렸는데, naive bayes classifer가 그 대표적인 예시라고 생각하시면 됩니다.
** 만약 예측하려는 이메일에 있는 단어에 학습 데이터에 등장하지 않는 것이 나오면 무시합니다. 왜냐면 빈도수가 0이기 때문에 확률도 0이 되기 때문이죠. 그렇다면 joint probability가 항상 0이 되어 문제가 되겠죠?
간단한 예시, "보험 판매 오늘 당장"이라는 이메일을 가지고 마지막까지 계산을 하면 이렇습니다.


결국 "보험 판매 오늘 당장" 이라는 이메일은 스팸인 것으로 예측이 되었습니다.

오늘은 고등학교 시절 배운 확률과 통계를 복습하는 마음으로 스팸 이메일 classifier를 공부해보았습니다. Naive Bayes Classifier는 문제를 단순하게 정의함으로써 간단한 카운팅만으로도 빠르고 쉽게 머신러닝 모델링을 할 수 있다는게 장점입니다. 또한 NLP 공부를 함에 있어서도 bayes theroem, word ordering indendence 등 나중에 중요하게 나오는 개념들이 많아 이번주에 소개해보았습니다.
너무 많은 수식 때문에 어렵지는 않았는지요? 최대한 큰 그림만 설명하려고 하여서 생략된 부분이 꽤 있습니다. 만약에 좀 더 디테일을 보고 싶으신 분은 제가 참고한 튜토리얼을 보시기 바랍니다!

Reference
- Chapter 4: Naive Bayes and Sentiment Classification, Speech and Language Processing. Daniel Jurafsky & James H. Martin



