

"We should let artificial intelligence (AI) do the work of politicians, judges, and bankers. AI doesn't have feelings or political views so it won't be biased."
I see these kinds of comments a lot on news articles about socially unjust systems or decisions. It is sad to see increasing distrusts on every crucial component of our societies - no matter where you are in the world, in 2020. Although we have been developing social systems, from legal to finance, to be less vulnerable to an individual's prejudice or ignorance, still, most decisions in the systems are made by humans.
Humans are inherently biased, by their childhood education, origins, and many other factors, or sometimes intentionally with bad intentions. So people who have been suffering from these unfair systems hope that removing humans in the loop will also remove their errors. Unfortunately, that is not the case for machine learning, the most popular approach for building AI systems.
Machine learning (ML) models are susceptible to unintended biases as much as we do. The good news is we can design them not to be.
What is unintended bias in ML?
Let's say you are running a hospital with limited resources but an exponentially growing number of patients. This scenario is not uncommon in the current pandemic situation. With good intentions to save more people, the hospital has been developing a model to predict the risk factor of patients. Patients predicted as ones with a high-risk factor will be treated first while others need to wait. Everything sounds reasonable, right? The more accurate predictions, the more lives saved.
However, according to the study published on Nature in October 2019, such an algorithm widely used in US hospitals has been discriminating against black people. The system was "less likely to refer black people than white people who were equally sick to programs that aim to improve care for patients with complex medical needs". The reason was that the model assigned risk scores to patients on the basis of total health-care costs accrued in one year, but the total health-care costs did not capture the whole picture.
The use of machine learning algorithms is not limited to healthcare. Ant Financial, which is more well-known by its product Alipay, talks about using machine learning to "determine whether to grant a customer a loan". In theory, this innovation will provide more financial opportunities to small businesses and individuals by increasing the productivity of approving loans. However, what if the algorithm is favorable toward a certain ethnic identity, gender, or race? Ant Financial's Cheif AI Scientist, Alan Qi, also mentions the risk of unfairness of the algorithm and its impact to real people.
Decisions by machine learning models are becoming more common in every field, which means, without properly handled, some of these unintended biases will permeate into our lives.
Why does it happen?
Indeed, any machine learning algorithm is not inherently biased as a trained model does not hold any value or believe in anything. AI does not have consciousness.
But machine learning model has a religion. It is called data. Machine learning happens by analyzing training data. The model finds patterns of the data.
The problem is that those data are usually coming from humans. Past human behaviors, our history, are likely to contain human bias - racial prejudices, gender inequality, and so on. Think about all historic loan data in the United States used as training data. Probably the most predictable feature for a person to be granted a loan will be home addresses. Redlining can happen in a data-driven way.
Even GPT-3, one of the recently published, most powerful models that got many NLP researchers excited for its performance, is known to have biases. Its researchers state in their paper: "Biases present in training data may lead models to generate stereotyped or prejudiced content." Note that their model is mainly trained on text corpus crawled from the Web. The paper includes a whole section called, "6.2: Fairness, Bias, and Representation", examining unintended bias in the model's generated texts on different genders, races, and religions.

Why is it hard to prevent?
"Can't we just remove those discriminatory variables from the data during training?"
Think about taking your gender off your resume (Gender on a resume? Yes, it is still required by some companies in South Korea). Nevertheless, other attributes, such as your name, club activities, and mandatory military service completion (You are pretty much guaranteed to be asked about this in South Korea), are already suggestive of your gender. If humans can easily tell, machine learning is definitely going to catch this pattern. These are obvious patterns just as examples, but there will be even more complex patterns that are indicative of your gender/race/ethnicity.
One can argue that if the model analysis shows that some attributes predict who is a good job candidate or debtor, isn't that the truth? Yes or no.
Firstly, you need to understand the difference between correlation and causation.
- Correlation is a term in statistics that refers to the degree of association between two random variables.
- Causation is implying that A and B have a cause-and-effect relationship with one another. You’re saying A causes B.
One race or ethnicity is more likely to have higher proportion of prison inmates. But can we say being "black" or "Hispanic" causes one to be more likely to commit a crime? This is a question that cannot answer by just one statistical number. Unfortunately, the result of a machine learning model can be easily confused with reality.
Secondly, the training data is usually a small fraction of the real world. Without acknowledging this fact, blindly throwing it to a machine learning can create a model not only biased but also poor performing.
The research work I worked on, "Reducing Gender Bias in Abusive Language Detection", shows that using a benchmark abusive language dataset to train a model has a problem in that such model often mistakenly identifies female pronouns as a strong indicator of a "sexist" language. For example, "She is a person" will have a high probability of being "sexist".
This is due to poor selection and balancing of training and evaluation data. As the model only learns from the given data, it has never seen enough perfectly normal sentences that contain the pronoun "she". Although this sounds trivial, it may be easily omitted when not properly taken into account during evaluation. A lot of machine learning model evaluations are reduced down to a single number, such as accuracy or F1 score.
How can we prevent it? Use a checklist.
1. Acknowledge it
- When designing your solution, think about what kinds of bias that you might unintentionally induce. This should be ideally done even before data collection. It will make your life much easier.
- Imagine the consequence of the model's prediction when deployed in real life. What would it mean to the individuals (users)?
2. Define & Measure it
"If you can't measure it, you can't improve it" - Peter Drucker
- Come up with additional metrics to measure the unintended bias in your model or your dataset, like this research about counter factual fairness.
- For the example of gender bias in the abusive language model, Error Rate Equality Difference was calculated by defining the unintended bias as the difference of false positive/negative rates of both genders.
3. Fight it
Now that you know what you are tackling, you need to optimize the numbers. There are various techniques to do this but I will introduce a couple of things in natural language processing (NLP).
- Add more examples to make your data more representative and balanced. This is the easiest and most intuitive, but often not an option when data collection is expensive or difficult.
- Leverage transfer learning. Using a bigger model trained on larger data can mitigate the bias. Also, there are specific efforts to remove biases in word embeddings, one of the most popular ways of transfer learning.
- Adopt adversarial training. Adversarial training, one of the recently hot topics of machine learning, can help reduce the unintended bias by jointly training a distracting classifier. This can help the model to learn representation agnostic of the attributes you want to explicitly avoid, such as gender or race, while not sacrificing classification accuracy.
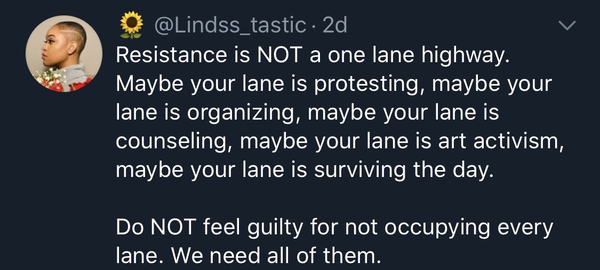
This tweet led me to write this post. I am not the most knowledgeable person in the history of racial discrimination in the United States, but I know that all people should be treated equally anywhere on the planet. I hope for society to be more harmonious and peaceful no matter your race, ethnicity, or nationality. I believe that diversity is the key to mankind's innovation, survival, and happiness.
My lane is studying and developing machine learning and natural language processing systems. One hopeful thing is that the community has a good self-awareness of this, setting up workshops, conference tracks, and themes in "ethical AI". Google has set up "Responsible AI Practices", which is being not only discussed internally but also shared with everyone.
I believe that these works will help to change our thinking when we are developing these systems. This post is a small stone on top of these wonderful efforts happening in every part of the lanes in the society.
Please feel free to leave comments to fill up the things I missed and reach out to me if you need more resources.
Reference
- Heidi Ledford, Millions of black people affected by racial bias in health-care algorithms, Nature.com, 2019
- Will Knight, Meet the Chinese Finance Giant That’s Secretly an AI Company, MIT Technology Review, 2017
- Alan Qi, Ant Financial Applies AI in Financial Sector, Alibaba Cloud Blog, 2019
- Brown et al., 2020, Language Models are Few-Shot Learners
- Catherine Yeo, 2020, How Biased in GPT-3?, Towardsdatascience Blog
- Lionel Valdellon, Correlation vs Causation: Definition, Differences, and Examples, Clevertap Blog, 2019
- Park et al., 2018, Reducing Gender Bias in Abusive Language Detection, EMNLP 2018
- Kusner et al., 2017, Counterfactual Fairness, NIPS 2017
- Dixon et al., 2018, Measuring and Mitigating Unintended Bias in Text Classification, AAAI/ACM Conference on AI, Ethics, and Society (2018)
- Zhao et al., 2018, Learning Gender-Neutral Word Embeddings, EMNLP 2018
- Elazar & Goldberg, 2018, Adversarial Removal of Demographic Attributes from Text Data, EMNLP 2018