

Image generated by playground ai; Prompt - "Alphabet letters coming in and out of a mechanical engine".
Large Language Models (LLMs) have taken over the world in recent months. New technological advances are happening really fast.
New models are being released every week, and it's hard to keep up. To be honest, I stopped following the research after a few "groundbreaking" models, but I have been still thinking about the implications of LLMs for software engineering.
I had the chance to work on one of the biggest LLM projects in the world, which gave me some initial insights. I've also been reading and experimenting with different engineering practices for LLMs.
As an extension of my previous post, On productionizing with ChatGPT, In my next two posts, I'll share my thoughts on engineering LLMs. This field is changing rapidly, so I'll be sure to emphasize that these are just my initial thoughts.
Disclaimer: The thoughts in this post are my own and do not represent my employer. I am not sharing any information that is not publicly known. I have used Google Bard to edit my writing.
What are LLMs?
Let’s go back to the basics.
LLMs, or large language models, can predict the next word in a sequence. They are trained on massive datasets of text and code, and can learn to perform a variety of tasks, such as generating text, translating languages, and answering questions. That’s why some people call them, “fancy autocomplete”.
But recent models proved that, with more scale and data, they can acquire a magical capabilities to follow our instructions, performing tasks that once seemed like only intelligent, creative humans could do in hours, or days, are getting done in matter of seconds.
LLMs can be divided into two types: [1] vanilla and [2] instruct-led. Vanilla LLMs are trained to predict the next word in a sequence, while instruct-led LLMs are trained additionally to follow instructions in the user prompt.
Instruct-led LLMs are enhanced by a technique called “Reinforcement Learning In Human Feedback (RLHF)”, using additional data to train the LLMs to take the input texts as instructions. That’s why we started calling these input texts as “prompts” and the act of changing the behavior of LLMs as “prompt-ing”.
When choosing an LLM, it is important to consider whether it is instruct-led trained or not.
LLMs as Engines
LLMs, or large language models, are not products themselves, but rather engines that can be used to create products. They are similar to car engines in that they provide the power to move something, but they need other components to be useful. For example, a car engine needs wheels, a body, and a steering wheel to be a transportation product.
In the same way, LLMs need other components to be useful. For example, the input prompt may need to be configured in a certain way, or the output may need some post-processing. And they also need to be integrated into a user interface so that people can interact with them. How to use these engines is really up to the designers and developers.

Some companies create their own engines and also the products that use them. For example, Google and OpenAI train their own LLMs and build products like Bard and ChatGPT. Other companies only provide the engines (such as Facebook's Llama), as Rolls-Royce manufactures airplane engines but not the aircrafts. Maybe some others will provide custom-tuned LLM engines that have been fine-tuned on a specific dataset. For example, Bloomberg developed an LLM for finance.
However, most companies will not create their own LLMs from scratch. Instead, they will utilize engines that have been trained by other companies.
This is because creating an LLM from scratch is very expensive. The majority of the cost comes from the pre-training stage, which requires requires running 1000s of GPUs, months of training, and millions of dollars. Only companies and open-source projects with abundant resources can afford to do this.

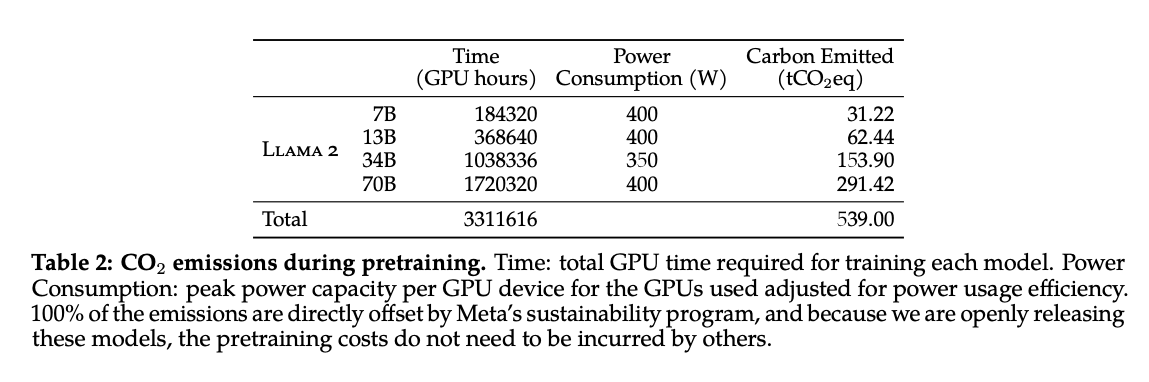
Also, it is ideal for reducing carbon footprint. See an excerpt from Llama 2 paper below on how much carbon is produced while training the model.
Using LLMs
Currently, there are two ways to use these engines:
- Calling an API: This is the simplest way to use LLMs. You can simply write a few lines of code to call an API and get the results you need. This is a great option for small projects or for people who don't want to deal with the hassle of hosting their own.
- Hosting your own: If you need more control over the LLM or if you need to use it for a large project, you can host your own. This requires more technical expertise, but it gives you more flexibility and control.
Calling an API
There are a number of companies that offer LLM APIs, such as Google, OpenAI, and Hugging Face. These APIs make it easy to use LLMs for a variety of tasks. The first method is so easy that it basically remove any barrier to entry to access LLMs. Anyone would can write simple API client code can leverage the power of these capable NLP models. All the complexity over infra, latency, training are done by the API providers. Client just needs to pay for the call.
Such simplicity fundamentally changed the game of NLP. The space exploded with people experimenting with LLMs via APIs. Some say that this is a larger phenomenon than the advent of iPhone’s App Store, which resulted explosions of third-part mobile apps. Now a high school student with minimal coding knowledge can create a pretty reasonably performing chatbot, threatening the existence of NLP engineers like myself.
However, there are a few drawbacks to calling an API.
- Latency: Calling an API can add latency to your application. This is because the API provider needs to process your request and then return the results.
- Cost: You may need to pay for each API call. This can add up if you are using the API for a large project.
- Data privacy: The data that you pass to the API may not be private. This is because the API provider needs to store the data in order to process your request (and sometimes subject to human review for their quality improvements).
- Limited control: input length and parameter selection are bounded by whatever API provides.
Hosting your own
As an alternative, Hosting your own LLM gives you more control over the model and the data. You can also use the model for more demanding tasks that would be too slow or expensive to call an API for. However, there are also some challenges to hosting your own LLM.
There has been a surge of different open-sourced LLMs of varying sizes. Meta's Llama 2 is a notable example, as it is now commercially usable, unlike its leaked predecessor. For example, StableLM and MPT are two other players who have released LLMs that they claim are as good as or even better than those of the major players.
Pros:
- Data privacy: Input and output do not need to go through a third-party. Such data ownership may be an important factor for a project.
- Costs: may be lower than calling an API for large number of data volumes.
Cons:
- Infra expertise: you need to create and maintain the infra to host the LLMs. Cloud providers will make this part easier, but still requires technical expertise.
- Performance: LLMs tend to have better capabilities when bigger, and larger models mean more difficulties to host.
Moreover, your own LLMs can be further tuned with proprietary data. However, fine-tuning (supervised learning or RLHF) is not an easy task to do right, so there will be more companies that offer finetuning-as-a-service, which you just upload your data, select the base LLM model, finetune it, and download the model weights.
Today I laid out my thoughts on the high-level view of LLM engineering. Main takeaway is that: “LLM is an engine, not a product”. I hope this view can inspire many product designers and engineers to think of LLMs to revolutionize whatever you are working on:
Next question that might arise then is, “what does a software engineer working with LLMs do?” Spoiler alert - it’s not jut prompt engineering. I’ll cover that in my next post.