

Image generated by playground ai; Prompt - "software engineers learning new things in front of a monitor, but panicking and frustrated".
What will NLP software engineers need to do in the new LLM world?
As someone who worked at one of the big tech companies that had this technology before ChatGPT, I had the privilege of working on many LLM projects relatively early. I thought to myself, "It's time to unlearn everything I learned about NLP." (But I spent years studying, doing research, and earning a postgraduate degree!
Will all software engineering eventually become "prompt engineering" as some worries? That is, no more coding, just writing English instructions to GPT.
Are all NLP engineers doomed? What should we do? Should we all start a Korean fried chicken store?
Nope, we should adjust to the new world and start thinking about LLM engineering.
Disclaimer: The thoughts on this posts are my own and do not represent my employer’s view. I am not sharing any information that is not public. Also, I’ve used Google Bard to edit my writing.
Availability of LLM APIs is a gamechanger
The rise of ChatGPT has had a profound impact on the field of NLP engineering. With the ability to call an API to PaLM or GPT, anyone can now solve NLP problems that would have once required specialized knowledge and expertise (Everyone is a NLP professional now)! Thanks to the easy access to LLMs via API, even a student with basic coding skills can integrate an LLM and build a chatbot that functions reasonably well.
For example, classification tasks used to require some form of machine learning training or fine-tuning. However, now anyone can simply try some prompts and achieve reasonable performance without any prior training.
(I use the term "reasonable performance" to mean that it looks good at first glance. However, as I mentioned before in my post, thorough evaluation often reveals that this is an illusion.)
This has led to some concerns that NLP engineering is becoming a commoditized field, and that the jobs of NLP engineers are at risk. I remember that time ChatGPT came out to public, my colleagues and I were pretty excited, not knowing the butterfly effect that it would bring to our career.
Rise of prompt engineering
Prompt engineering is a new buzz term that refers to the art of writing instructions for LLMs. LLMs are trained to take an input text as instructions to follow, so the way a user writes the prompt can greatly affect the output of the model.
Here are some things to consider when writing prompts for LLMs:
- Which examples should I include?
- How do I format them?
- What explicit instructions should I include?
- What other tricks are there to make LLMs follow my instruction correctly?
Strictly speaking, there is no "engineering" involved in prompt engineering. I think it's just a cleverly coined term. It is simply a matter of writing clear and concise instructions and knowing the patterns that works well on the model, so maybe It should be more like "prompt writing."
And I don't think "prompt engineer" will be a job title. Rather, prompt writing will become a common task for everyone in a company (no special skills required, as long as you can write), including software engineers, product managers, general managers, and so on. I believe this is already happening.
Everyone who uses LLMs will need to do some trial and error when writing prompts. This can be frustrating, as LLMs are black boxes and it can be difficult to understand why they behave the way they do. How they behave depends on the data and the training methodology, and, most likely, the user does not have any information on this. Additionally, LLMs are probabilistic models, so even with the same input, the output can vary. Also, an update in the model may influence previous versions of engineered prompts, so they may need to be updated regularly.
Such instability is something LLM users need to keep in mind and constantly deal with. I wrote about this a bit more on my previous post, On Productionizing with ChatGPT.
LLM engineering?
If prompt engineering is not engineering, then what does LLM engineering look like?
I mentioned in my previous post that LLMs are most likely going to be trained by only a few companies with the resources and the know-how, even finetuning. Therefore, most engineers will not need to deal with building the engine itself, unless they work for one of those companies and in those teams.
I mentioned in my previous post, LLMs are engines, that LLMs are most likely going to be trained by only a few companies with the resources and the know-how, even finetuning. Therefore, most engineers will not need to deal with building the engine itself, unless they work for one of those companies and in those teams.
Instead, there will be a variety of tasks and areas that need to be addressed.
The following list is not exhaustive, but it contains some areas that I think are important. The core perspective here is a continuation from the last post, "An LLM is an engine; other components are needed to make it work."
Testing, Evaluation, and Risk Analysis
The stability of software relies on tests. Unit tests and integration tests give engineers peace of mind and help them sleep at night.
However, LLMs change this paradigm. Their random and probabilistic nature makes engineering with LLMs much more challenging. LLMs are also known to have risks, such as hallucinations and unintended biases.
Systems that use an LLM engine need to take this trait into account.
- How can we ensure that a system behaves as intended?
- How can we know if an updated LLM version works better than the previous one?
These are key questions that must be addressed in the evaluation process. This process will now involve not only building evaluation datasets, but also data pipelines and systems to make things efficient. If evaluation takes a long time, then the production cycle will be slow, or the team will have to fly blind. A lot of engineering effort is needed for evaluation.
Evaluation datasets need to include a representative set of real user inputs, as well as high-risk inputs that could produce unsafe or catastrophically failing outputs. (And most importantly, the evaluation set should not directly overlap with the training set.)
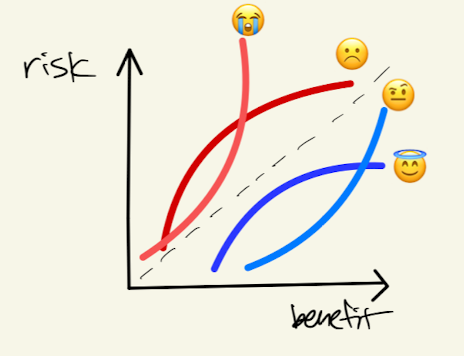
In the end, we want to assess the risks and benefits of LLMs through evaluation.
The graph looks something like this:
Human evaluation
Many researchers have been inventing automatic metrics to speed up evaluation of NLP tasks. Often, classification or regression datasets come with gold labels. However, the challenge in evaluating LLM systems is that there is often no absolute answer.
It is more like evaluating an essay written by a student. An essay can be wrong in many ways – off-topic, incoherent, ungrammatical, or untruthful. However, once it passes these basic criteria, there is no absolute, objective score for how good an essay is. For this reason, graders may choose to compare the writing with other students'. Saying that one writing is better than another is easier (but only slightly).
LLMs are also evaluated in a similar way. They are compared to each other to see which one performs better.
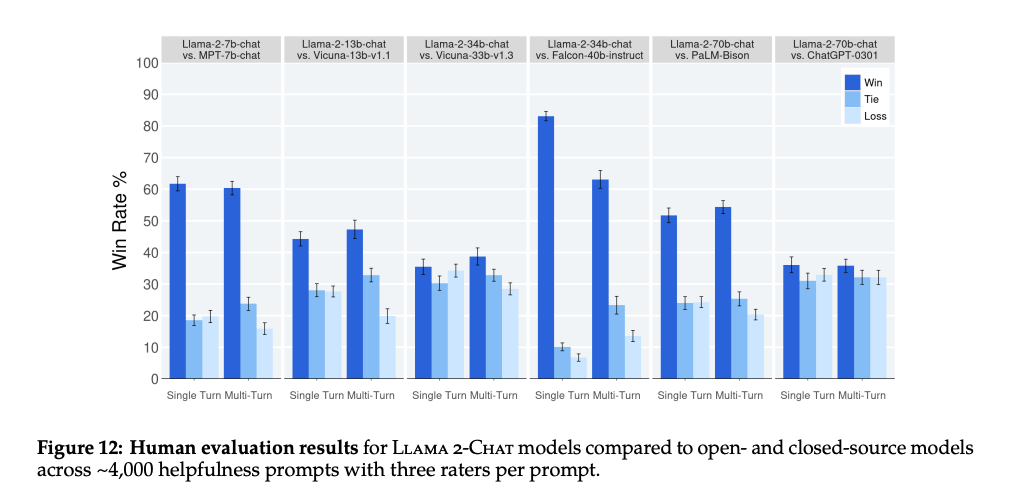
One of the challenges of this evaluation is that it involves a lot of human annotators, also known as human computation (HCOMP) projects. These projects are not just expensive, but they also involve specific tasks such as vendor management, quality inspections, and cost analysis.
One may argue that these are not software engineering tasks, but rather project management tasks. I believe that software engineers should also understand this process in order to work with project managers, or in smaller companies, they may be in charge of these tasks.
Additionally, interpreting the results is not trivial. When evaluating LLMs, human annotator decisions are commonly used, but they can be quite noisy. Data science skills can be helpful in analyzing these results.
Risk Handling
There are so many risks in areas such as privacy, security, and safety when using an LLM. A dedicated effort is needed to identify these risks by preparing special evaluation datasets, red teaming, and other methods.
Once the risks have been identified, we need to develop strategies to mitigate them. In some cases, it may be possible to fix the LLM engine to prevent risky behaviors. However, this may not always be feasible. In these cases, we may need to use other methods, such as detecting risky inputs and outputs and handling them separately (e.g., filtering).
Mitigating the risks of LLMsis not just an engineering problem. It also involves a lot of user experience (UX) thinking.
- How can we gain the trust of users with a system that is inherently risky?
- How can we minimize the damage when risky behavior occurs?
- How can we ask users to flag new cases without damaging or upsetting them?
Data management and processing
LLMs could not have been created without data. While a large amount of data is already used in the pre-training stage, those who use the LLM engine will also need to manage a large amount of data themselves.
As I explained above, the most important data is for evaluation. There may also be data for further improvements (e.g., fine-tuning data). The system will also produce logging data.
With an LLM engine, a lot of data will be generated. This creates significant data engineering challenges, such as storage, versioning, analytical tools, quality management, and log mining.
Software Systems Design
Senior engineers design systems. This will not change in the LLM world, but we need to think outside the box of traditional software engineering.
- How do we integrate an LLM engine into our existing system?
- How do we build a stable system around an engine that is inherently random?
- How will data flow through each component?
- How do we design tests that take randomness into account?
ML/NLP system design is an exciting area that I would also like to learn and experience more!
Defining problems
Last but not least, I believe that engineers need to not only solve problems, but also identify them. We have invented a powerful engine, but where can it be used?
Chatbots are the most intuitive and popular application of LLMs, but they can be used for more than that. They can replace existing NLP systems or generate synthetic data that can be used to train smaller models. Any existing automation flows should be revisited to see if LLMs can be used to improve them.
Excitingly, many people are exploring the use of LLMs as agents that can make decisions and take actions directly. This approach could drastically reduce the engineering cost of complex control flows. Libraries like Langchain make prototyping easy, so if you are interested, go and experiment!
To unlock more potential of LLM engines, engineers need to think outside the box and start talking to people in different areas. This includes not only other roles, such as product managers, UX designers and researchers, program managers, and business developers, but also people from other fields.
In a world where anyone can access these powerful LLMs through APIs, digging vertically - focusing just on the tech expertise - may not be a good investment. On the other hand, thinking horizontally could lead to more innovation and opportunities. Other fields, such as healthcare, education, manufacturing, and retail, will adopt foundational models like LLMs to achieve productivity gains. They need more software engineers who can identify problems that can be solved by LLM engines.
In the last two posts, I touched on the topics of engineering with LLMs. It is really a scary and exciting time to be a NLP engineer. We should all really spend time in learning new things and experimenting with them. I also wish I have more time to tinker with different stuffs.
If you have any feedback, question, things to share, please post on the comments.