

The sounds of laughter are the highlights of our lives, while the sounds of a baby crying can be quite the opposite.
Every day, we are exposed to a variety of different sounds inside our home. We understand where they are coming from and what to do when we hear them. When we hear a high-pitch ringing, we know it is coming from the baby and run to the bedroom. When we hear our family laughing, we smile and feel happy.
In 2019, I was working for a startup building a smart baby home device that can help to parent by analyzing how much parents talk to the baby and understand different moments by understanding the sounds at home.
How can machines understand different sounds?
The recent advances in machine learning (ML) enable machines to detect objects in images, transcribe what people are saying, and even translate that to another language. This is possible because of the rise of deep learning and exponential growth of data. Understanding images and language has become one of the hottest research topics.
However, understanding different sounds, other than speech, may seem unfamiliar to some people. Today, in this post, I will introduce some research works that we have been using to teach our machines how to understand laughter and baby cries in a home environment.
In the research community, we call this problem as acoustic scene understanding or sound event classification. Given audio, we want to predict what kind of sound it is and/or where it is coming from. Such prediction may be useful for a product like ours which triggers an action- saving audio moments with laughter for families and playing soothing sounds or notify the parents when the baby is crying.
So where should you begin when you want to build ML models?
I will introduce two different works that I explored to build laughter and baby crying detection models.
OpenSmile
OpenSmile (Speech & Music Interpretation by Large-space Extraction) is a widely used feature extraction toolkit for many speech-related problems. It is more popular among affect computing community since the features had been proven so successful in problems like emotion recognition, music interpretation, personality detection, etc. The library can extract various acoustic signal features, such as fundamental frequency, MFCC, and spectral bands, from an audio signal.
One of the first papers that used OpenSmile for sound event classification is Wang et al., 2016, presented in ICASSP 2016. The work is interesting in that it first extracts 6,669 features and reduces the dimensionality with Principal Component Analysis (PCA). This is to make the feature vectors dense for training an RNN model to perform classification. The model is trained to distinguish event labels like “feeding an animal”, “wedding ceremony”, “changing a vehicle tire”, etc.

Google Audioset
Transfer learning through pre-trained models trained on a large amount of data has been the trend of ML community nowadays. ImageNet has been a huge success in the computer vision field, and BERT has changed the state-of-art for many different natural language processing (NLP) tasks.
In 2017, Google released a dataset called Audioset with 2 million 10-second audio clips with more than 500 labels. The original data comes from Youtube. Due to the popularity of this video platform, all sorts of video footage of the human world are contained in Youtube. It is not surprising that Google decided to make use of those videos for AI research.
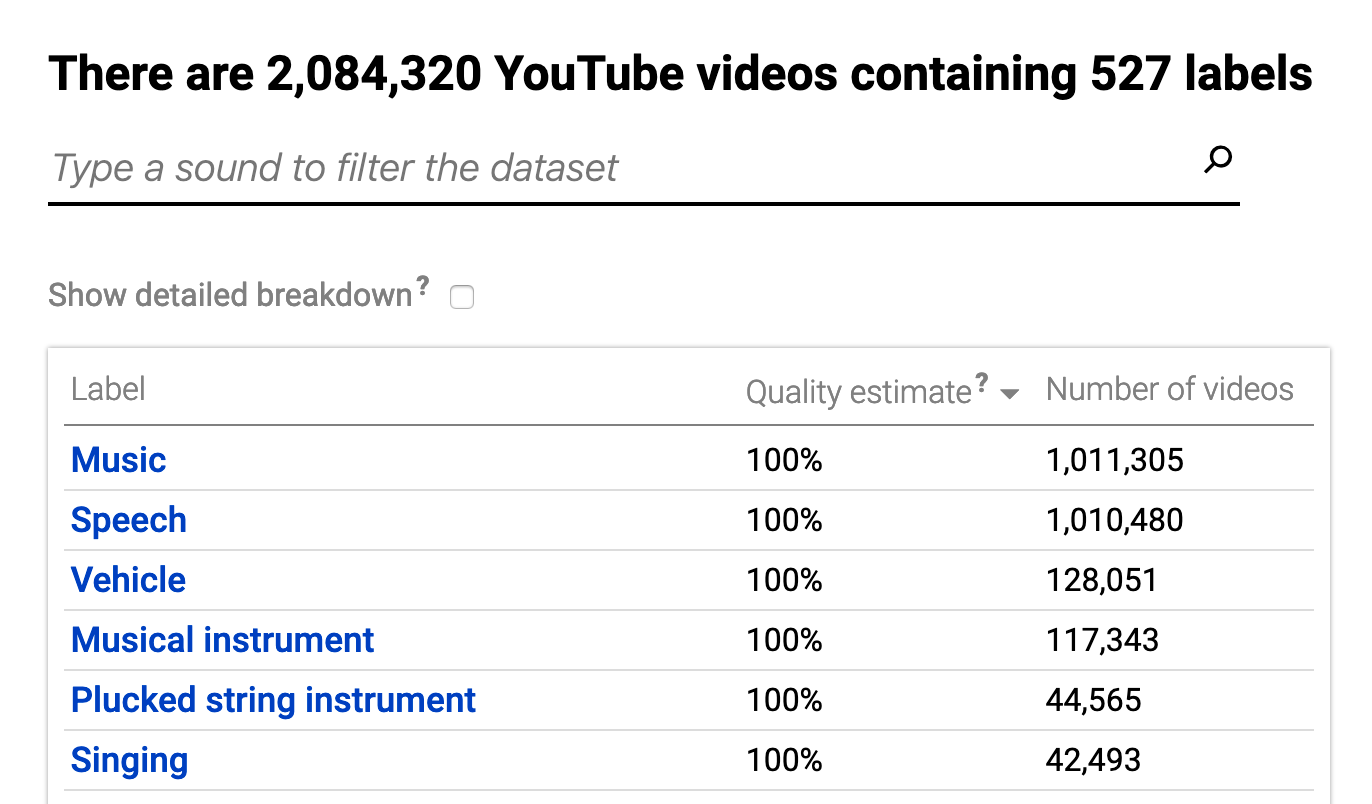
Thanks to Google, we were able to acquire initial sets of baby crying and laughter audio samples to train our seed classifiers, which we used them to do some active learning on hundreds of hours of unlabeled audio streams (more of that on another post)

Google Vggish Audio Embedding
However, due to the enormous size of Audioset, it is not easy for anyone to build such a large model and efficiently handle such a massive training dataset. For this reason, the more important counterpart of Audioset is Vggish Audio Embedding, a large convolutional neural network (CNN) trained to classify different sounds. Just as other popular transfer learning models, the softmax layer is removed so that the second last layer acts as an embedding extractor for any kind of sound.
The output of Vggish is very straightforward — 128-dimension vector for every second. So if 5 seconds of audio is given, the model spits out a 5x128 vector, which then can be used to train any other machine learning model.
Hershey et al., 2017 explains the details about how the model is trained. The audios are transformed into Log-Mel spectrograms, which is same as 2D images. As CNN is proven to perform well for such inputs, they experiment with different image classification architectures such as ResNet, VGG, AlexNet, etc., and find out that VGG-like architecture performs the best. That’s why the model is called VGGish.

Building a classifier on top
After learning how to stand on the shoulder of a giant called Google, we built our classifier by using Google Audioset as a feature extractor. Now we can think of each 128d vector as something like a word embedding in natural language processing. 10-second audio clip becomes a sentence with 10 words, where each word is represented by a 128d embedding.
To effectively capture the time dependency of the audios (e.g. a sound must be relevant to the sound 1 second ago or after), we use RNN architectures like LSTM or GRU with these features to train a classifier.
While we cannot reveal our internal data to train out baby crying classifier, we suggest playing with datasets like Environment Sound Classification (ESC-50). In our experiments, it was interesting how the classifier gets confused by cat sounds and door squeaking sounds (Only one cat-lover colleague can tell that it was a cat!)
Conclusion
In this post, I showed how you can start training acoustic scene detection models by using two feature extraction tools (with very different approaches). I built a laughter and baby crying classifier using some of these tools, which in turn became an important feature for our smart baby home device.
Opensmile Website
https://www.audeering.com/opensmile/
Google Vggish Codes
https://github.com/tensorflow/models/tree/master/research/audioset/vggish