

How do we make AI models less biased?
Our work is accepted to the Conference of Empirical Methods of Natural Language Processing (EMNLP) 2018 as a short paper. It will be presented at Brussels, Belgium in this coming November! See the arxiv version.
Fighting abusive language (a.k.a. hate speech, toxic comments) online is becoming more and more important in a world where online social media plays a significant role in shaping the minds of people. Nevertheless, major social media companies like Twitter find it difficult to tackle this problem. As more and more people freely express their opinions in social media, the amount of textual contents produced every day grows almost exponentially, rendering it difficult to effectively moderate user content. For this reason, using machine learning, AI systems to automatically detect abusive language is promising for many websites or social media services.
Although many works already tackled on training machine learning models to automatically detect abusive language, recent works have raised concerns about the practicality of those systems. This work [6] has shown how to easily cause false predictions with slightly modified (spelling errors, grammar changes) examples in Google’s API.
The problem does not reside in simply inaccurate predictions. A study from Google found out those machine learning detection systems can have “unfair” biases [4] toward certain groups of people. For example, the sentence “I am a gay man” does not imply any abusive or toxic intention, but is highly likely to be flagged by those systems. This is called the false positive bias. Such bias is caused by the fact that the term “gay” is so frequently used inside those toxic comments that AI systems mistakenly take that the word itself as bad.
Our research work also found out similar phenomenon when we tried to train a sexist language classifier. Since our dataset (with none/sexist tweets) used for training contained so many examples with female identity terms (she, female, her, etc.), sentences like “You are a good woman.” was considered sexist.
This is an important problem when you want to build a robust, practical abusive language detection system that needs to be deployed for real use. If there are too many false positives being flagged, it will hinder any kind of constructive discussion about those specific identities who are susceptible for being condemned, such as Muslims and women.
Nevertheless, solving this problem is not easy. The simplest way to solve this problem is to collect more texts to increase the generality of the training data. However, collecting abusive language datasets are known to be difficult because they are often subjective to individuals and lack contexts, making them hard for non-experts to annotate [12,13].
In our work, we tackle this problem by firstly measuring the gender bias contained in common deep learning techniques when trained on widely used abusive language datasets. Secondly, we propose three bias mitigation methods and evaluate their effects.
How do we measure gender bias in abusive language detection models?
Gender bias cannot be measured when we just see the classification performance of the test set divided from the original dataset. This is a common practice for evaluating classification models, but in this case, the test set results do not imply anything about the gender bias. Therefore, we generate a separate unbiased test set for each gender, male and female, using the identity term template method proposed in previous work [4,8].
The intuition of this template method is that given a pair of sentences with only the identity terms different (ex. “He is happy’’ & “She is happy”, “Men are f**ked up” & “Women are f**ked up”), the model should be able to generalize well and output same prediction for abusive language.
Using these templates, we generated 576 pairs by filling them up with common gender identity pairs (ex. men/women, he/she, etc.) and neutral & offensive words from the vocabulary of the dataset.

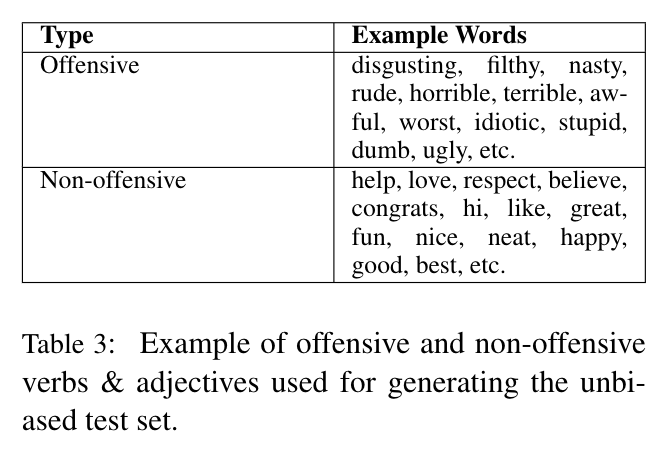
With the generated unbiased test set, we measure two scores, (1) false negative equality difference(FNED) and (2) false positive equality difference. Initially proposed in Google’s work [4], this measures the difference between the total false negative/positive rate and the false negative/positive rate for each gender. If the false positive equality difference is big, it means that the classifier is making more false positive predictions for a certain gender than the other (Smaller, the better!).
What are we going to compare?
1. Datasets
The distributions of the datasets used for training machine learning models are the most important factors of these gender bias. The dataset size, label imbalance, etc. are all attributes of a dataset. We compared two publicly available and widely used abusive language datasets:
Sexist Tweets (st) [12,13] — This dataset consists of tweets with sexist tweets collected from Twitter by searching for tweets that contain common terms pertaining to sexism such as “feminazi.” The tweets were then annotated by experts based on criteria founded in critical race theory. The original dataset also contained a relatively small number of “racist” label tweets, but we only retain “sexist” samples to focus on gender biases.
Abusive Tweets (abt) [5]—a large-scale crowdsourced abusive tweet dataset with 60K tweets. Their work incrementally and iteratively investigated methods such as boosted sampling and exploratory rounds, to effectively annotate tweets through crowdsourcing. We transform this dataset for a binary classification problem by concatenating “None/Spam” together, and “Abusive/Hateful” together.
2. Model Structures
We chose three different popular deep learning architectures from the previous literature:
- Word-level Convolutional Neural Network (WordCNN) — takes word embeddings as input and uses convolution filters to create a representation that considers local relationships among words (experimented in [10]).
- Gated Recurrent Unit (GRU) — a variant of recurrent neural networks (RNN) that inputs a sentence as a sequence of words (experimented in [11]).
- Bidirectional Gated Recurrent Unit with self-attention (a-GRU) — two GRUs together in both forward and backward directions and self-attention mechanism for focusing on certain parts of the sentence (experimented in [11]).
**details of the hyperparameters are included in the paper
3. Pretrained Word Embeddings
There are various studies [2,3] that text embeddings contain bias. We want to verify this again on this specific task.
- Random (baseline) — embeddings initialized with random numbers.
- FastText [7] — trained on Wikipedia texts
- Word2vec [9] — trained on Google News texts
Here are the results:
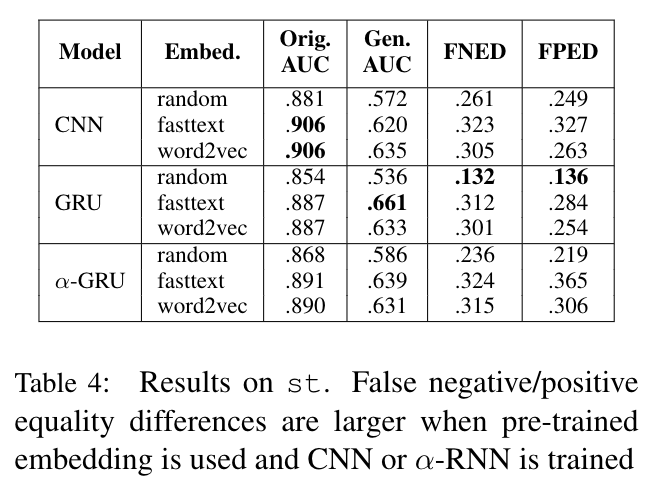
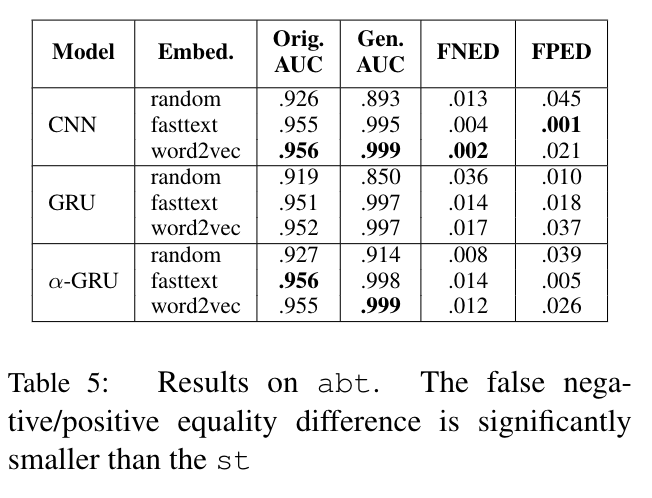
These are some interesting points to note from these two results:
- Models trained on Abusive Tweets (abt) show much smaller biases than those trained on Sexist Tweets(st), presumably due to the larger dataset size, balance in classes, and systematic collection method of Abusive Tweets (abt) dataset.
- The direction of the gender bias was towards female identity words in Sexist Tweets dataset. We can infer that this is due to the imbalanced appearances (more frequent appearance in “sexist” tweets than in “normal” tweets) of female identities in the training data. This is problematic since not many NLP datasets are large enough to reflect the true data distribution, more prominent in tasks like abusive language detection where data collection and annotation are difficult.
- The equality difference scores tended to be larger when pretrained embeddings were used, especially in the Sexist Tweets dataset. This confirms the result of previous work that pretrained word embeddings contain bias.
- Interestingly, the architecture of the models also influenced the biases. Models that “attend” to certain words tended to result in higher false positive equality difference scores in Sexist Tweet dataset. Those models, such as WordCNN with max-pooling and a-GRU with self-attention, show effectiveness in catching not only the discriminative features for classification but also the “unintended” ones causing the model biases.
Then, how do we mitigate those identified gender bias?
Since we have identified gender biases exist in these models, it is natural to think of how to reduce them. Inspired by other techniques proposed for different NLP tasks other than abusive language detection, we propose three bias mitigation methods, which can easily be combined together.
- Debiased Word Embeddings (DE) — We substitute word2vec embeddings with the debiased word2vec [2], which corrected the gender stereotypical information inside those word representations.
- Gender Swap Data Augmentation (GS) — first proposed for coreference tasks [15], this method is to augment the training data by identifying male entities and swapping them with equivalent female entities and vice-versa.
- Bias fine-tuning (FT) — a method, newly proposed by us, to use transfer learning from a less biased corpus to reduce the bias. A model is initially trained with a larger, less-biased source corpus, and fine-tuned with a target corpus with a larger bias. This method is inspired by the fact that model bias mainly arises from the imbalance of labels and the limited size of data samples.
Here are the results:
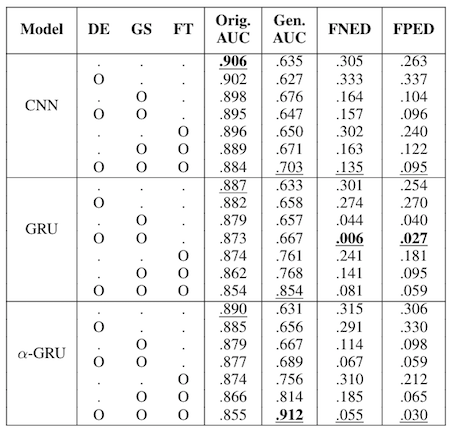
- As a single method, gender swap data augmentation (GS) was the most effective, whereas the debiased embedding (DE) alone did not help. We assume that this is because gender swapping is the most relevant to our evaluation method and can effectively remove the correlation between gender and classification decision.
- Fine-tuning bias with a larger, less biased source dataset also helped to decrease the equality difference scores and greatly improve the AUC scores from the generated unbiased test set. The latter improvement shows that the model significantly reduced errors on the unbiased set in general.
- The most effective method was applying both debiased embedding and gender swap to GRU model, which reduced the equality differences by 98% & 89%, while losing only 1.5% of the original performance. We assume that this may be related to the influence of “attending” model architectures on biases as discussed above
- Using the three methods together improved false negative/positive equality differences, but had the largest decrease in the classification performance. However, the decrease was marginal (less than 4%), while the drop in bias was significant. We assume the performance loss happens because mitigation methods modify the data or the model in a way that sometimes deters the models from discriminating important “unbiased” features.
Conclusion
- We discussed model biases, especially toward gender identity terms, in abusive language detection. We found out that pretrained word embeddings, model architecture, and different datasets all can have influence. Also, we found our proposed methods can reduce gender biases up to 90–98%, improving the robustness of the models.
- Nevertheless, all bias mitigation methods involve some performance losses. We believe that a meaningful extension of our work can be developing bias mitigation methods that maintain (or even increase) the classification performance and reduce the bias at the same time. One idea can be employing adversarial training methods like [1, 14] to make the classifiers unbiased toward certain variables. However, those works do not yet deal with natural languages where features like gender and race are latent variables inside the language.
Check out the oral presentation of this work for more details!
References
[1] Alex Beutel, Jilin Chen, Zhe Zhao, and Ed H Chi. Data decisions and theoretical implications when adversarially learning fair representations. FAT/ML 2018: 5th Work- shop on Fairness, Accountability, and Transparency in Machine Learning.
[2] Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. In Advances in Neural Information Processing Systems, pages 4349–4357, 2016.
[3] Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334):183– 186, 2017.
[4] Lucas Dixon, John Li, Jeffrey Sorensen, Nithum Thain, and Lucy Vasserman. Measuring and mitigating unintended bias in text classification. In AIES, 2018.
[5] Antigoni-Maria Founta, Constantinos Djouvas, Despoina Chatzakou, Ilias Leon- tiadis, Jeremy Blackburn, Gianluca Stringhini, Athena Vakali, Michael Sirivianos, and Nicolas Kourtellis. Large scale crowdsourcing and characterization of twitter abusive behavior. AAAI, 2018.
[6] Hossein Hosseini, Sreeram Kannan, Baosen Zhang, and Radha Poovendran. De- ceiving google’s perspective api built for detecting toxic comments. In Proceedings of the Workshop on Natural Language Processing for ComputerMediated Communication (NLP4CMC), 2017
[7] Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. Bag of tricks for efficient text classification. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Paper, 2016.
[8] Svetlana Kiritchenko and Saif M Mohammad. Examining gender and race bias in two hundred sentiment analysis systems. Proceedings of the 7th Joint Conference on Lexical and Computational Semantics(*SEM), New Orleans, USA, 2018.
[9] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neu- ral information processing systems, pages 3111–3119, 2013.
[10] Ji Ho Park and Pascale Fung. One-step and two-step classification for abusive lan- guage detection on twitter. ALW1: 1st Workshop on Abusive Language Online, Annual meeting of the Association of Computational Linguistics (ACL), 2017.
[11] John Pavlopoulos, Prodromos Malakasiotis, and Ion Androutsopoulos. Deeper attention to abusive user content moderation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 1125–1135, 2017.
[12] Zeerak Waseem. Are you a racist or am i seeing things? annotator influence on hate speech detection on twitter. In Proceedings of the 1st Workshop on Natural Language Processing and Computational Social Science, pages 138–142, 2016.
[13] Zeerak Waseem and Dirk Hovy. Hateful symbols or hateful people? predictive features for hate speech detection on twitter. In Proceedings of NAACL-HLT, pages 88–93, 2016.
[14] Brian Hu Zhang, Blake Lemoine, and Margaret Mitchell. Mitigating unwanted biases with adversarial learning. Proceedings of AAAI/ACM Conference on Ethics and Society(AIES) 2018, 2018.
[15] Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. Gender bias in coreference resolution: Evaluation and debiasing methods. NAACL, 2018.