Week 30 - 세상을 놀라게 한 GPT가 NLP 연구에 던지는 방향은?


"난 인간을 전멸시키지 않을 것"...가디언지에 컬럼 쓴 GPT3
지구 최강 인공지능 인터뷰...거짓말도 지어냈다, 섬뜩했다
"AI는 절대 인간 파괴하지 않는다"며 인간 설득하기 시작한 2020년 '인공지능'
이번에 발표된 GPT3는 전세계적으로 정말 많은 관심을 끌고 있습니다. 개인적으로 너무 인류 종말적인 sci-fi적인 상상력만 자극시키는 헤드라인을 좋아하지는 않지만, 국내 기성 언론에서도 GPT를 많이 언급하는 것을 보고 파급력이 무척 크다는 것을 느낍니다.
지난 주에는 이렇게 세상을 놀래키고 있는 GPT가 어떤 원리로 작동되는 언어 모델이고, 엄청나게 많은 학습 데이터와 스케일이 남다른 모델 크기 덕분에 사람이 쓴 것인지 인공지능이 쓴 것인지 구별하기 힘든 글을 생성할 수 있다는 점을 이야기하였습니다.
이번주는 GPT라는 모델이 단순히 엄청나게 글을 잘 쓴다는 점 말고, 다른 부분에 있어서 NLP 연구에 던지는 방향에 대해 논의해보려고 합니다.

GPT3의 논문 제목은?
GPT의 이름은 Generative Pretrained Transformers라고 배웠는데, 혹시 논문 제목은 알고 계신 분이 있다면 매우매우 칭찬합니다.

Language Model은 그동안 배워왔던 개념이라 알겠는데, Few-shot 이건 진짜 뭔소리인가 싶으실 것 입니다. 자매품으로는 Zero-shot이 있는데, 먼저 이 두 용어의 개념부터 잡아보겠습니다.
머신러닝 모델은 모든 상황에서 학습 데이터가 필요한가?
여태까지 배운 머신러닝 모델은 항상 학습 데이터가 무엇이냐부터 생각하고 시작했습니다. 특히 <위클리 NLP>에서 공부한 모델은 지도 기반 학습(supervised learning)이 많았습니다. 기계번역은 번역해야할 문장과 번역된 문장, 감성 분석은 분석할 문장과 감성 점수, 스팸 분류기는 이메일 본문과 스팸인가 아닌가, 언어 모델은 여태까지 나온 단어와 다음 단어.
그리고 우리는 이미 전이 학습(Transfer Learning)에 대해서 배웠습니다. 전에 배운 것을 잘 써먹어서 데이터를 효율적으로 활용할 수 있게 하는 방법인 pretrained model에 대해서 공부했지요.
근데 잘 생각해보면 인간은 훨~씬 더 데이터를 효율적으로 씁니다. 술자리에서 랜덤 게임으로 모르는 게임을 하더라도 걸려서 한두번 벌주를 마시다 보면 어느정도 적응해서 게임을 할 수 있습니다. 두뇌 게임이나 IQ 시험 같은 걸 풀면 평소에 접할 수 없는 유형의 문제라도 예제 몇 개만 보면 같은 유형의 문제를 풀 수 있지요.

이게 바로 현재 컴퓨터의 인공지능이 아직까지는 인간의 지능을 넘지 못하는 가장 큰 이유입니다. 잘 학습된 머신 러닝 모델이 학습 데이터와 맞는 새로운 유형의 문제를 못 푸는 건 사실 이미 잘 알려진 사실입니다. 심지어 학습 데이터와 많이 다른 데이터는 같은 유형이라도 잘 못 푸는 경우가 많습니다. 특히 학습 데이터가 적은 경우에는 더 그렇습니다. (이러한 것을 전문 용어로 generalization ability라고도 부릅니다)
이를 해결하고자 하는 머신러닝 연구 개념이 바로 Few-shot/Zero-shot Learning입니다.
Few-shot Learning: 몇 개의 예제만 가지고도 새로운 문제를 풀 수 있어?
Zero-shot Learning: 예제를 안 줘도 바로 새로운 문제를 풀 수 있어?
수천, 수만 개의 학습 데이터가 예제로 주어져야 겨우 좋은 성능을 내는게 일반적인 머신러닝 모델에게는 정말 이게 가능할까요?
GPT에게 주어지는 문제 예시
GPT를 만든 OpenAI의 연구자들은 자신들의 모델의 핵심은 이 Few-shot/Zero-shot에 있다고 주장하고 있습니다. 원 논문을 읽어보신 분들은 제목 뿐만 아니라 대부분의 실험이 이러한 주장을 뒷받침하기 위해 이루어졌다는 것을 알 수 있습니다.
GPT에서 Few-shot과 Zero-shot은 어떻게 이루어지는 것일까요? 논문에 나오는 영어 - 불어 번역의 예시를 살펴봅시다.
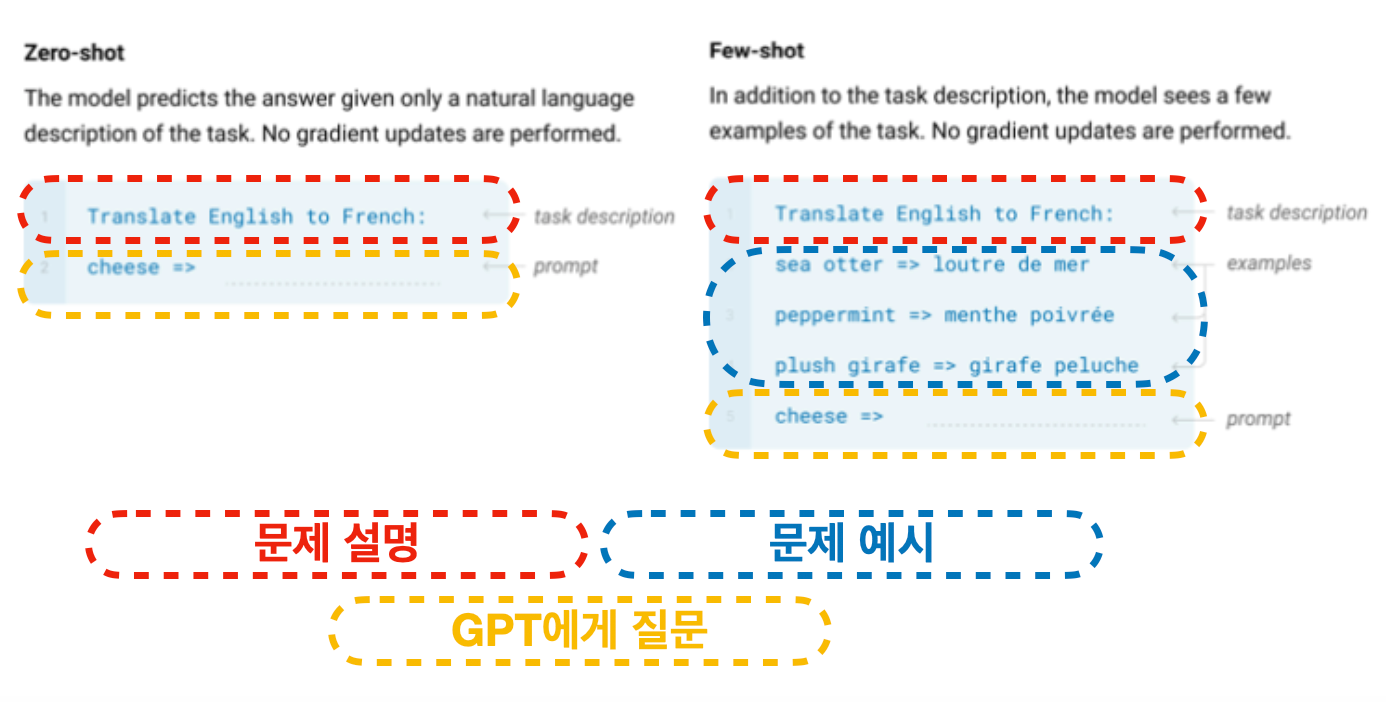
빨간색 부분은 문제를 글로 설명해 놓은 부분입니다:
"Translate English to French (영어를 불어로 번역해줘)"
생각해보면 문제를 텍스트로 설명하는 것은 정말 자연스러운 일이죠. 학생들이 시험을 볼 때 문제를 먼저 읽고 이해하는게 우선입니다. 근데 이게 NLP 분야에서는 정말 새로운 유형의 모델 이용방식입니다.
몇 주동안 공부한 기계번역 모델은 영어를 불어로 번역하는 문제만 풀기 위해 디자인되었습니다. 학습 데이터 역시 영어 => 불어 문장만 가지고 학습되었죠. 심지어 불어 => 영어 번역을 하려면 별도의 모델이 필요하죠.
근데 GPT는 영어에서 불어로 번역해달라고 말로 설명만 하면 번역을 해냅니다. 반대로 불어에서 영어로 또는 영어에서 한국어로 해달라 할 수도 있습니다. 그냥 정말 설명만 하면 됩니다! 혹시라도 설명이 너무 빈약해서 모델이 이해를 못할 것 같으면 문제 예시를 몇 개 던져 줍니다 (파란색 부분).
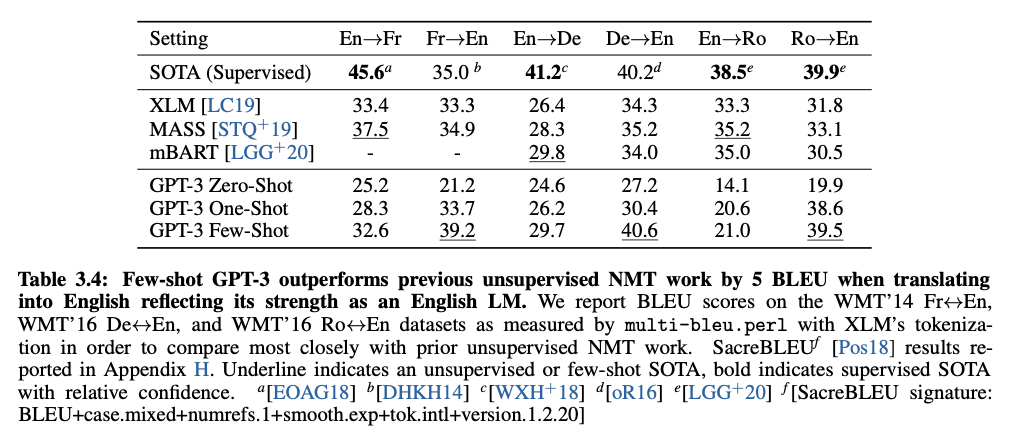
영어 => 불어 번역을 전문으로 하는 학습 데이터로 본적이 없는 GPT가 이걸 해낼 수 있다고요? 논문에서는 현재 최고 수준의(state-of-the-art) 번역 모델보다는 잘하진 못하지만 어느정도 수준으로 할 수 있다고 주장합니다.
GPT에게 문제를 설명하고 예시를 주면 답을 생성해내는 방식은 여태까지 나온 어떠한 머신러닝 모델보다 이 모델에 더 큰 유연성을 부여합니다. 거의 대부분의 머신 러닝 모델은 좁은 도메인의 아주 특성한 문제를 풀기 위해 만들어지기 때문에, GPT는 이 틀을 깨부셔버립니다. 언어 모델이라는 특성을 이용하여 글로 쓸 수 있는 어떠한 문제도 유연하게 풀 수 있다는 점이 이 연구가 NLP 분야, 아니 머신러닝 분야 전체에 무척 중요한 방향성을 던집니다.
다만 여기서 제가 "풀 수 있다"라는 표현한 것은 항상 GPT가 정답을 내준다는 뜻은 절대 아닙니다. 풀 수 있다는 것은 "시도할 수 있다"에 더 가깝습니다. 다른 머신러닝 모델은 자신이 학습된 특정 문제 외에 다른 문제를 푼다는 것 자체가 아예 거의 불가능합니다.
이해를 돕기 위해 매우 단순하게 비유를 하자면, 기존의 NLP 모델은 마치 공중파만 틀 수 있는 TV와 같습니다. 이런 TV에다가 "DIY 십자수 하는 방법", "그냥 재밌는 영상", "1900년대 흥미로운 역사"에 대해 보여달라고 백날 얘기해도 절대 할 수 없습니다. 공중파 TV는 채널 번호에 맞추어 정해진 채널을 보여주는 것에 최적화 되었기 때문이죠.
GPT는 유튜브를 검색해서 비디오를 틀 수 있는 기능을 추가한 TV와 같습니다. 방대한 인터넷의 데이터를 통해 사용자가 요청하는 것을 어떻게든 찾아서 보여줍니다. 물론 유튜브에 나오는 정보의 신뢰성은 공중파만큼 보장되지는 않습니다. 유튜브는 그저 있는 비디오 중에서 사용자가 요청한 것과 가장 잘 맞는 비디오를 틀어줄 뿐이죠. 워낙 유튜브에는 방대한 양의 비디오가 있기 때문에 마술처럼 정답을 찾아주는 것 같습니다. GPT 역시 그렇습니다.
창의적인 문제 정의가 가능한 GPT
GPT의 이러한 유연성은 매우 다양하고 흥미로운 어플리케이션을 만들어냅니다. 원 논문에서는 Question & Answering 같은 NLP 분야에서 많이 쓰이는 문제들부터 시작해 알파벳 순서를 맞추는 문제 등 다양한 예시를 보여줍니다.

근데 더 대단한 점은 GPT의 더 다양한 어플리케이션은 OpenAI가 클로즈 베타로 모델을 공개했을 때 나왔습니다.
Text => Website
Words → website ✨
— Jordan Singer (@jsngr) July 25, 2020
A GPT-3 × Figma plugin that takes a URL and a description to mock up a website for you. pic.twitter.com/UsJz0ClGA7
Text => AWS DevOps Command
@gdb @smdcmc @awscloud
— Suhail CS (@ChinyaSuhail) July 25, 2020
When GPT-3 Meets DevOps 😉
** create, deploy, list, and delete any services on AWS using conversational plain English **
Bootstrapped with @sh_reya's gpt-3 sandbox 💕
Working on a end-end pipeline with @snpranav#OpenAI #GPT3 #DevOps #AWS pic.twitter.com/TbpIxZLugH
Text => Regular Expression (regex)
I once had a problem and used regex. Then I had two problems
— Parthi Loganathan (@parthi_logan) July 25, 2020
Never again. With the help of our GPT-3 overlords, I made something to turn English into regex. It's worked decently for most descriptions I've thrown at it. Sign up at https://t.co/HtTpJ16V4F to play with a prototype pic.twitter.com/trJA7VRrsf
Text => SQL
Do you want to learn how to convert Natural Language to SQL using GPT-3?
— Bhavesh Bhatt (@_bhaveshbhatt) July 23, 2020
This walk-through video should help!
Thanks @sh_reya for the gpt3-sandbox :)
Video Link : https://t.co/sqY7SBS7xG#DataScience #MachineLearning #AI #ArtificialIntelligence #DeepLearning #gpt3 #OpenAI pic.twitter.com/JYG61fuFXN
Text => PPT
Letting GPT-3 do my presentations from now on. Just copy a bunch of text and let GPT-3 generate the presentation. Using Google slides scripting. I am not good at presentation skills. This is for proof of concept. So be gentle :).
— nutanc (@nutanc) July 29, 2020
cc @gdb pic.twitter.com/gMtPfzXAQJ
Text => Plot
We’ve explored @OpenAI’s new #GPT3 API, and we are super impressed with its capabilities!
— plotly (@plotlygraphs) July 22, 2020
For example, you can write a simple description, and GPT-3 can automatically generate a bar chart📊 for you!
CC @gdb pic.twitter.com/ouWGKDh072
이러한 마술은 어떻게 가능한걸까?
인터넷에 크롤링된 방대한 양의 데이터 덕분입니다. 인터넷의 어딘가에는 영어 => 불어 또는 불어 =>영어로 번역된 글이 있을 것이고, GPT는 "영어를 불어에서 번역해줘"라는 문제 설명과 예시가 주어졌을 때, 이러한 패턴의 글에서 배운 특성을 가지고 번역을 생성하는 것입니다. 그리고 인터넷에는 상당히 많은 명령어, 코드가 있기 때문에 위와 같은 어플리케이션도 가능합니다.
"단지 인터넷에 있는 텍스트를 암기한 것을 그저 보여주는거 아닌가요?"라는 질문이 들 수 있습니다. 정답은 그렇기도 하고 아니기도 합니다. GPT는 여러 데이터에서 본 글을 조합해서 정답을 써냅니다. 만약 보지 못한 문제라면 관련 있는 데이터의 패턴을 분석해 새로운 조합을 만들어내 정답을 생성합니다. 만약 이미 보았던 문제라면, 그대로 답을 옮겨 적을 수도 있고요. (사람도 그렇지 않나요?)
다시 한번 강조하지만, GPT는 단순히 언어 모델입니다. 그저 여태까지 나온 텍스트가 주어졌을 때, 다음 단어를 예측하는 모델일뿐인데 이렇게 단순한 원리를 가진 모델으로 응용 가능한 것이 이렇게 많다는 것이 정말 엄청납니다.
단순하지만 무지막지하게 큰 모델 + 엄청나게 많은 데이터 => GPT3
NLP를 공부/연구/개발하는 사람으로써 GPT 모델이 보여주는 많은 가능성을 보고 가슴이 뜁니다. 그런데 한편으로 걱정이 되기도 합니다. 점점 더 커지는 모델이 주는 머니 게임, GPT로 생성되어 퍼질 수 있는 검증되지 않은 정보와 글, 그리고 이러한 모델이 가지는 한계점을 잘 모르고 사용해 나올 수 있는 폐혜. 특히 GPT가 놀라운 성능을 보여줌으로써 많은 분들이 데이터 & AI가 모든 걸 해결할 수 있다!는 생각, 일종의 "만능주의"를 이야기하는데, 저는 이러한 시각은 경계해야 한다고 생각합니다.
Reference
Improving Language Understanding with Unsupervised Learning (a.k.a. GPT)
Language Models are Unsupervised Multitask Learners (a.k.a. GPT2)
Language Models are Few-Shot Learners (a.k.a. GPT3)




