
![Week 38 - [팩트체크] NLP로 가짜 뉴스 거르는게 가능할까?](https://images.unsplash.com/photo-1611926653458-09294b3142bf?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=MnwxMTc3M3wwfDF8c2VhcmNofDk4fHxzb2NpYWwlMjBtZWRpYXxlbnwwfHx8fDE2MjIyNzk0NTc&ixlib=rb-1.2.1&q=80&w=2000)
빠름빠름 LTE를 넘어 5G 네트워크 세상이 되었습니다. 이렇게 통신 기술이 빨리 발전하다보니깐 손 안에서 동영상을 어디서든 기다리지 않고 볼 수 있다는 장점도 있지만, 악성웨어나 바이러스가 우리 주머니 속의 스마트폰으로도 침투할 수 있다는 단점도 있겠지요.
2020년 4월, 영국에서는 몇몇 분들이 화를 주체하지 못한 나머지 네트워킹용 장비를 불태우는 일까지 벌어졌습니다. 이러한 네트워크 기술의 발전(?)으로 2020년부터 전세계에 코로나 바이러스가 퍼져, 우리의 일상을 마비시킨 팬데믹도 겪다고 생각했기 때문이라고 합니다. (!?) 아직까지도 바이러스가 활기치는 것을 보니 네트워크 전체를 제거하기에는 역부족이었나봅니다.

코로나 바이러스 때문에 겪고 있는 현실도, 위의 어처구니 없는 이야기도 거짓말이었으면 좋겠지만, 전부 실제 있는 일입니다.
"5G 네트워크가 코로나 바이러스 전파의 원인이다"라는 말도 없는 주장으로 가짜뉴스를 퍼트린 것도 어이가 없지만, 이를 믿고 저러한 행동을 한 사람들이 있다는 것도 참 놀랍습니다.
그만큼 가짜 뉴스, 가짜 정보가 판을 치고 있습니다. 특히 전세계 사람들이 여러 소셜 미디어/동영상 플랫폼에 많은 시간을 쏟고 있는 세상이 된 지금, 이러한 "진실 아닌 거짓"은 이 사회를 위협하는 악이라고 생각합니다. 실제로 이로 인해 재물 파손, 폭력, 살인 등의 범죄 그리고 거짓에 기반으로 한 잘못된 선동이 일어나고 있기 때문이죠.
엄청나게 많은 양의 정보가 생성되는 지금, 모든 것을 사람들이 확인할 수는 없는 노릇입니다. 그렇다면 NLP를 이용하여 "팩트체킹"을 한다면 어떨까요? 최근 놀라운 성능을 보여주고 있는 대형 언어 모델(LM)을 이용할 수는 있을까요?
현재 홍콩과기대에서 팩트체킹 연구하는 이나연 박사 연구원님을 이 글을 통해 소개하려고 합니다. 팩트체킹 문제에 대해 소개하고, 하고 계신 연구의 방향성과 결과에 대해 인터뷰를 통해 의견을 나누어보았습니다.
**<저널리즘 x NLP> 시리즈의 두번째 글입니다.

자기소개 부탁드립니다.
안녕하세요! 홍콩과기대학교(HKUST)에서 파스칼 펑(Pascale Fung) 교수님* 지도 하에 박사 과정 중인 이나연이라고 합니다. 저는 허위정보(misinformation)와 관련된 사회적 문제에 NLP를 사용해 해결하는 연구를 하고 있습니다. 현재는 팩트체킹(fact-checking)에 초점을 두고 있습니다.
*필자: 저의 석사과정 지도 교수님이셨고, 이나연 연구원과는 저는 과거 같은 연구 팀에 있었습니다.
이 토픽은 어떤 계기 또는 동기로 연구를 하게 되셨나요?
소셜 미디어의 부상으로 허위정보 문제가 더욱 심각해지고 중요해졌습니다. 좋은 정보 공유가 쉽다는 장점도 있지만, 가짜 뉴스나 루머가 쉽고 빠르게 전파된다는 단점도 있어, 그로 인한 피해가 점점 더 많아지고 있습니다.
아마 최근 코로나 사태때 많은 가짜정보와 뉴스가 퍼져서 어떤게 사실인지 헷갈리거나 괜히 더 두려워졌던 경험이 있으실거라 믿습니다. 실제로 작년에 아리조나에서 염소(chlorine)가 코로나에 도움이 된다는 잘못된 정보를 믿고 마셨다가 사망한 안타까운 사례가 있었습니다.
저는 이 모든게 기술의 발전으로 인해 생겨나고 악화된 문제들이기에, 이를 해결하고 맞서는 기술들도 함께 발전해야 한다고 믿고 있습니다.

팩트체킹(Fact-checking)은 어떤 문제인가요?
크게보면, 팩트체킹은 주어진 주장(claim)의 진실성을 관련된 증거들을 바탕으로 확인하는 작업입니다.
하지만 이 문제를 해결하기 위해서 고려해야하는 몇가지 세부 문제들(sub-tasks/research questions)이 존재합니다.
첫번째, “팩트체킹에 사용되는 ‘증거(evidence)’의 신뢰성을 어떻게 확인하고 보장하는가?”
(또는, “믿을만한 ‘증거’이 존재하지 않는 경우엔 어떻게 하는가?” 또한 중요한 문제가 되기도 합니다)
두번째, “많은 믿을만한 정보들이 주어졌을때, 우리가 팩트체킹 하고자 하는 ‘주장’과 가장 연관이 있는 ‘증거’를 어떻게 효율적으로 찾는가?”
마지막, “가장 연관있는 ‘증거’가 주어졌을때, 이를 어떻게 사용하여 주장의 진실성을 판단할 것인가?” 입니다.
팩트체킹 벤치마크 데이터셋 FEVER와 이에 관련된 shared task에 대해 간략하게 소개해주실 수 있나요?
Thorne et al., 2018 [1]은 이 첫번째 문제를 신경 쓸 필요없게, 위키피디아를 믿을만한 소스(knowledge source)로 사용하는 FEVER 데이터 셋을 제시하였습니다.
이 데이터셋은 540만 개의 위키피디아 문서들과 18만 개의 샘플들로 이루어져 있으며, 현재까지 공개된 팩트 체킹 데이터 셋 중에 가장 큽니다.
각 샘플의 주장(claim)은 위키피디아에서 추출한 문장을 살짝 변형하여(paraphrase)하여 만들어졌습니다.
예시:
"The Rodney King riots took place in Los Angeles"
=> "The Rodney King riots took place in the most populous county in the USA".
진실성 라벨(Verdict)은 주장(claim) 추출을 어떻게 했느냐에 따라 달라집니다. 만약 claim의 팩트/내용을 유지한 채 paraphrase를 했다면 라벨은 TRUE가 주어지고, 반대로 내용을 틀리게 바뀌었다면 라벨은 FALSE가 주어졌습니다. 또 진실성을 증명하기에 증거가 충분하지 않은 경우가 많은 실제상황들을 고려해, 위키피디아 문서로 증명할 수 없는 내용의 주장을 의미하는 NOT-ENOUGH-INFO라는 라벨도 존재합니다.

Thorne et al. 은 이 FEVER 데이터셋을 사용하는 Shared Task를 만들고, 다음과 같은 팩트체킹 파이프라인을 여러 개의 모듈(module)로 정의합니다.
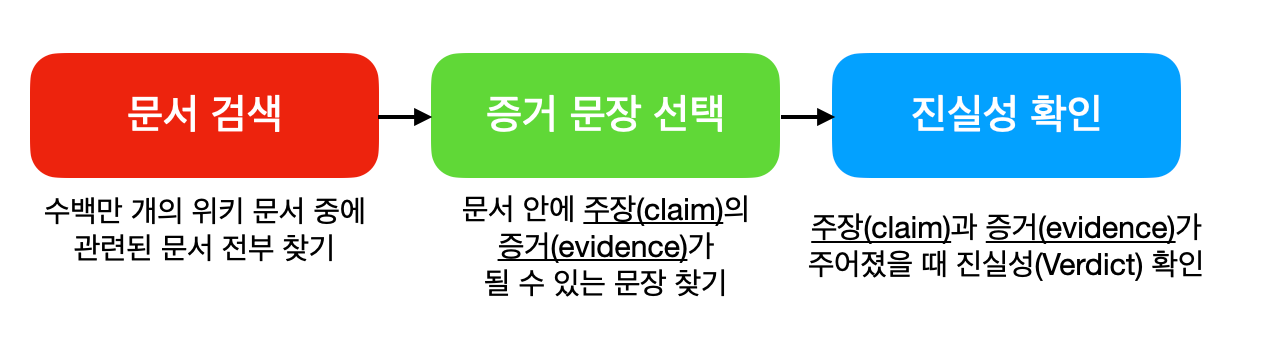
1. 문서 검색 모듈 - 540만 개의 위키 문서가 주어지면, 증거를 포함하는 관련 문서를 식별하는 모듈 (e.g., "Los Angeles Riots")
2. 증거문장 선택 모듈 - 증거를 포함하는 위키문서가 주어지면, claim 과 연관있는 증거문장을 식별하는 모듈 (e.g., "also known as the Rodney King riots")
3. 진실성 확인 모듈 - claim 과 증거가 주어지면, 진실성 라벨을 확인하는 모듈 (e.g., supported )
이 Shared Task의 목적은 FEVEROUS score 을 높이는 것인데, 이 스코어는 최종 결과인 진실성 확인 모듈뿐만 아니라 중간 단계인 증거선택 모듈의 맞아야 한다는 특징이 있습니다. 주장(claim)의 진실성 라벨(Verdict)만 정확히 맞추는 것이 아니라, 증거 선택도 제대로 해야 하는 엄격한 기준의 채점 방식을 채택하고 있습니다.
*Question Answering(QA)와 다른 점
QA 문제는 어떤 질문이 주어졌을 때 주어진 텍스트 안에서 연관 있는 부분을 찾고 답을 예측하거나 생성해야 한다는 점에서 팩트체킹과 비슷합니다. 다만, 팩트체킹 문제는 “올바른" 정답을 찾는데에 좀 더 초점을 두고 있다는 점에서 QA와 차이가 있습니다. 특히 사실에 반한 잘못된 부분까지 잡아내야 한다는 점에서 QA가 팩트체킹 문제를 전부 커버하지 못한다고 생각합니다.
본인의 연구에서 팩트체킹에 언어 모델(LM)을 사용하는 것이 큰 특징인데, 어디서 처음에 아이디어를 받으셨나요?
최근에 LM을 원래의 목적인 언어 생성(Natural Language Generation; NLG)가 아닌 다른 용도로 사용할 수도 있겠다는 연구가 나오고 있습니다. 크게 두가지 방향이 있는데, 하나씩 간단히 설명한 후, 팩트체킹에 어떻게 적용을 했는지 설명하도록 하겠습니다.
첫번째는 LM 을 Knowledge Base (KB) 로 사용하는 방법입니다.
Petroni et al. 은 자신들의 EMNLP2019 논문에서 LM이 사전 훈련 데이터에서 학습한 상식 및 사실 지식을 많이 저장하며, 이런 지식들을 어느 정도 뽑아서 사용할 수 있다는것을 보여줬습니다.

도표에서 볼 수 있듯이, 저자들은 문장의 일부를 마스킹하고 (i.e., [MASK]) LM에게 마스킹된 토큰을 예측하도록 요청함으로써 LM에 "질의"합니다. 이들은 실험을 통해, LM 이 아무 추가적인 트레이닝 없이 LM에 내제된 지식만으로 질의응답에 나쁘지않은 성능을 보인다는걸 증명하였습니다.
이 논문을 보며 "이러한 LM 의 능력을 사용해서 팩트체킹 파이프라인 모듈들을 단순화시키면 어떨까?" 란 생각을 하게 되었습니다.
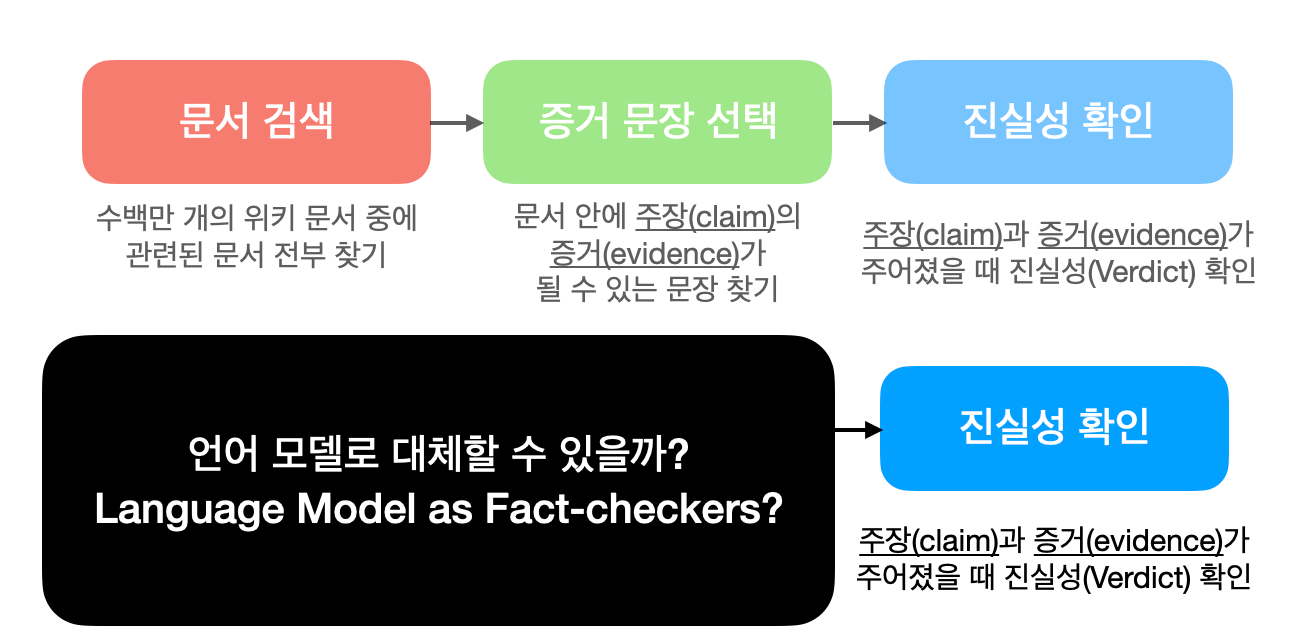
따라서, "Language Model as Fact-Checkers?" [3]라는 저의 논문에서 540만개의 위키피디아 문서들, 문서검색과 증거문장 선택 모듈들을 LM 하나로 대체하는 실험적인 방법을 시도해보았습니다. 이 방법의 가장 큰 장점은 더 이상 많은 메모리를 필요로 하는 외부 데이터베이스에 의존할 필요없다는 점과 간소해진 모듈을 통해 더 빠른 인퍼런스를 가능케한다는 점입니다.
이 방법은 State-of-the-art 모델들을 성능으로 이기지 못하지만, 팩트체킹을 해결하는 새로운 방향에 대한 가능성을 보여줍니다. (더 자세한 내용은 논문을 봐주세요!)
두번째는 LM을 few-shot learner로 사용하는 방법입니다.
Brown et al. 은 자신들의 GPT-3 [4] 논문에서 GPT-3 와 같은 사전학습한 대형 모델이 인상적인 few-shot learner로써의 성능을 가진다는 것을 입증했습니다 (Week 30 참고)
이런 방법을 통해 다양한 NLP 문제들 (e.g., 질문 답변, 요약, 번역, 상식 추론 등등)에 few-shot learning 을 하는 것을 보며, 팩트체킹에도 LM을 비슷하게 사용 할 수 있지 않을까 고민하게 되었습니다.
이에 대한 답으로 저는 "Towards Few-Shot Fact-Checking Via Perplexity"라는 논문에서 perplexity 스코어를 사용한 few-shot fact-checking 을 하는 방법을 제안했습니다. Perplexity는 새로운 문장이 주어졌을 때, 언어 모델이 이 문장이 얼마나 그럴듯한지 계산한 점수입니다 (Week 13 참고).
GPT 같은 언어 모델들은 엄청난 양의 인터넷 데이터로 학습되었기 때문에 이 모델이 계산한 점수를 통해 주장(claim)이 얼마나 진실성이 있는지 확인할 수 있지 않을까라는 가설을 세워보았습니다.
저희의 실험을 통해 언어 모델의 Perplexity Score가 한 주장의 진실성에 대한 좋은 시그널이 될 수 있다는 것을 보여주었습니다.
아래 예시를 보면 “5G 네트워크가 질병을 퍼뜨릴 수 있다", “모든 개는 영어를 유창하게 한다", “손을 씻는 것은 질병을 퍼뜨리는데 도움이 된다" 같은 터무니 없는 주장들이 대체로 Perplexity score가 높게 나온다는 것을 확인할 수 있었습니다.

팩트체킹에 LM을 사용할 때 장단점은 어떤 것이 있을까요? 예를 들어, GPT로 생성된 문장을 보면 실제 세상과는 맞지 않은 경우도 꽤 있는데, 이러한 한계점을 극복하기 위해서는 어떤 방향으로 가야할까요?
장점부터 말씀드리자면, 대형 언어 모델의 놀라운 발전에 편승할 수 있다는 점입니다. 현재 GPT나 BERT 등 이러한 모델을 발전시키는데 어마어마한 리소스와 노력이 들어가고 있습니다. 그렇기 때문에 아직 완벽하지는 않지만 앞으로 점점 더 성능이 좋아지고 강해질 것이라고 생각합니다. 그에 앞서서 팩트체킹이라는 문제에 언어 모델을 잘 활용하는 방법을 일찍부터 개척한다면, 나중에 LM이 더 강해져왔을 때 팩트체킹 모델도 함께 강해질 수 있을 것이라고 생각합니다.
하지만 질문하신 것처럼 GPT3 같은 모델들도 여전히 단점이 많습니다. 그렇기 때문에 저는 좀 더 이 방향의 연구를 실험적이고 미래지향적이라고 생각하며 접근하고 있습니다.
이러한 미래지향적인 연구를 함과 동시에 좀 더 현실적이고 응용이 가능한 연구도 병행해야 한다고 생각합니다. 만일 이에 대해 관심이 있으시다면 저의 최근 다른 연구인 On Unifying Misinformation Detection을 살펴보시면 감사하겠습니다. 루머, 가짜뉴스, 정치적 주장, 낚시성 기사 등의 문제에 멀티태스크 러닝을 접목시킨 연구입니다.
페이스북에서 인턴으로써 합동 연구를 많이 하였는데, 페이스북에는 fact checking/fake news 같은 주제를 전담하는 연구 팀이 있나요?
인턴 규정상 내부적인 내용을 회사에 대한 내용을 함부로 공개할수 없지만, 공개된 내용들을 정리해 답을 해보도록 하겠습니다.
우선 제 연구는 페이스북의 제품과는 독립적으로 학문적 목적을 가지고 진행된 연구임을 밝힙니다.
페이스북 AI 의 공식 홈페이지에는 큰 연구 분야 중 하나로 진실성(“Integrity”)을 꼽고 있습니다. 사람들이 소셜 미디어 플랫폼에서의 사람들의 안전을 위한 기술 연구를 말합니다. NLP뿐만 아니라 컴퓨터 비전, 머신러닝 등에 분야에서 여러가지 연구를 하고 있습니다.
특히 최근에는 가짜 정보 유통(Misinformation), 딥페이크(Deepfake) 같은 문제를 해결하기 위한 다양한 AI 기반 솔루션을 소개 [8]하였습니다. 딥페이크 감지 챌린저 (Deepfake Detection Challenge) 데이터 셋을 공개하여 다른 연구자들과의 협업을 위한 공유 태스크(Shared Task)를 만들기도 하였고, 실제로 페이스북 제품에 사용하기도 한답니다.
이나연 연구원님, 이메일: nayeon7lee@gmail.com
오늘은 팩트체킹이라는 주제에 대해 알아보고 대형 언어 모델로 이를 해결하려는 방향의 연구를 이나연 연구원님과 알아보았습니다. 점점 더 생성되는 컨텐츠가 많아지는 만큼 NLP 기술로 이 문제를 해결해 가짜뉴스가 없는 세상이 되었으면 좋겠습니다.

Reference
[1] Thorne et al., "FEVER: a large-scale dataset for Fact Extraction and VERification", NAACL2018
[2] Petroni et al., "Language Models as Knowledge Bases?", EMNLP2019
[3] Lee et al., "Language Models as Fact-Checkers?", ACL2020 FEVER Workshop
[4] Brown et al., "Language Models are Few-Shot Learners", Neurips2020
[5] Lee et al., "Towards Few-Shot Fact-Checking via Perplexity", NAACL2021
[6] Lee et al., "On Unifying Misinformation Detection", NAACL2021
[7] Facebook AI Integrity, https://ai.facebook.com/research/integrity
[8] https://ai.facebook.com/blog/heres-how-were-using-ai-to-help-detect-misinformation/