Week 49 - AI 스마트 스피커 작동 방법 해부하기


"OK G, 오늘 날씨 어때?",
"A, 타이머 5분 설정해줘.",
"Hey C, 노래 틀어줘"
몇년 전 스마트 스피커가 나왔을 때 정말 신기했었는데, 2022년 지금은 이미 많은 사람들의 방구석으로 들어왔습니다. 이제는 익숙해져서 처음의 신기함보다는 "왜 더 똑똑하지 못하냐"는 불평, 불만이 더 앞서는 분들도 있을지 모르겠네요. (저처럼..)
미국에서는 인터넷을 사용하는 사람 중 약 절반 정도가 스마트 스피커를 가지고 있다고 합니다. 앞으로는 집 뿐만 아니라, 차량/상점/행정업무/콜센터 등에 보편적으로 AI가 여러분과 대화하는 시대가 올 것 같습니다. 이미 2020년 코로나 바이러스 때문에 더 가속화된 디지털화로 "챗봇"에 대한 기업들의 관심도가 폭발적으로 늘어났죠.
위클리 NLP에서는 Week 31에서 챗봇에 대해 다루었었습니다. 하지만 그 때는 "이루다", "심심이" 같은 자유 주제 대화 챗봇에 집중을 했었죠.
이번 글에서는 챗봇과는 좀 다른 문제 해결용 대화 시스템(Task-oriented Dialogue System), 즉 스마트 스피커에 들어있는 AI 비서에 대해 이야기해보려고 합니다.
AI 비서는 어떻게 우리의 말귀를 알아듣는 것일까요?

*특정 회사의 AI 대화 시스템이 아닌 학계에서 널리 연구되어 공개된 대화 시스템의 구조임을 미리 밝힙니다.
친구가 "밥 먹었냐"를 대처하는 우리의 방식
친구가 "밥 먹었냐?"라고 물어봤을 때, 우리가 어떻게 답변을 하는지 나누어서 생각해봅시다.
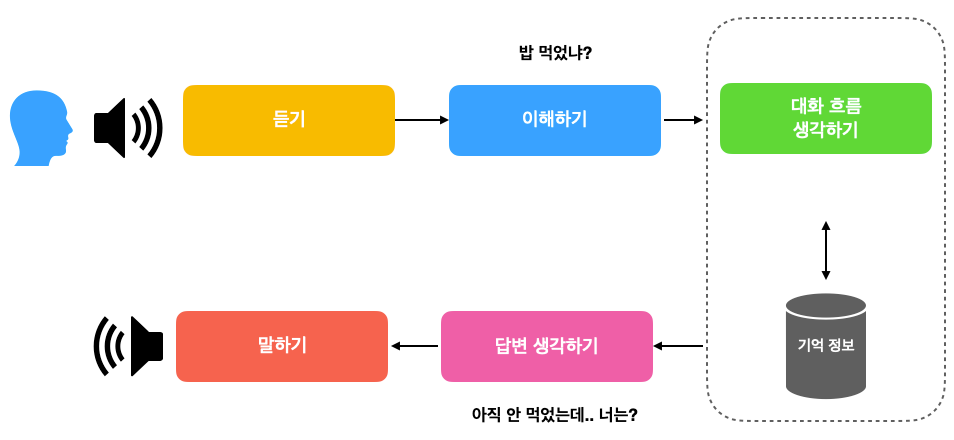
1. 듣기
친구의 목소리는 공기의 진동이 만들어 낸 파동입니다. 파동 자체는 그 자체로는 어떤 의미를 지니지 않습니다. 그저 소리 신호일 뿐이죠.
이를 우리가 이해할 수 있는 언어로 바꾸는 것은 우리의 뇌입니다. 소리 신호를 의미가 있는 "밥", "먹었냐" 같은 단어로 해석합니다. 만일 친구가 내가 알지 못하는 외국어로 물어보았다면 도저히 뭔 말인지 알아들을 수가 없겠죠.
만약 친구가 말로 하는 대신 문자를 보냈다면 이 부분은 "듣기"가 아니라 "읽기"로 바뀔 것 입니다. 화면에 나온 문자를 눈으로 읽어 친구의 의미를 파악합니다.

2. 이해하기
소리 신호를 언어로 바꾸고 난 후에는 이해를 해야 합니다.
친구는 내가 밥을 먹었는지 아닌지에 대한 정보를 묻고 있습니다. 하지만 어떤 때에는 의미가 분명하지 않을 수도 있습니다. 만약에 지금 시간이 11시라면 아침을 얘기하는지, 점심을 얘기하는 것인지 헷갈릴 수도 있겠죠.
그 전에 했던 대화의 흐름에 따라 의미가 완전 달라질 수도 있습니다. 만일 바로 직전에 내가 "영희랑 어제 만났어"라고 했었다면, "밥 먹었냐"는 "어제 영희랑 만났을 때 밥 먹었냐"라고 해석될 수도 있겠죠.
이처럼 어떤 말을 이해한다는 것은 굉장히 높은 상황/배경 정보와 이를 처리하는 지적 수준을 요구하는 작업입니다.
3. 대화 흐름 생각하기
만일 정말 내가 밥을 먹었는지 안 먹었는지 묻는 것이라고 이해했다고 칩시다. 그러면 일단 내 기억 정보 (또는 배꼽 시계)를 통해 아직 밥을 안 먹은 것을 기억해냅니다.
슬슬 점심 시간이라는 정보도 알아챕니다. 점심 약속이 있는지 없는지도 기억으로부터 확인해봅니다. 오늘은 딱히 약속이 없는데, 혼자 먹기는 싫다는 감정도 확인합니다.
그렇다면 자연스럽게 같이 밥을 먹으러 가려고 하려면 어떤 대화 흐름을 가져야 할까 고민합니다. "안 먹었으니 같이 가자고 할까..?" 그러면 뭔가 너무 적극적인 것 같습니다. 괜히 그랬다 거절 당하면 기분이 나쁘니깐, 나도 간접적으로 친구의 식사 여부에 대한 정보를 요청을 하기로 합니다. 그러면 친구도 나의 의도를 알아챌 수 있을 것 같습니다.
4. 답변 생각하기
나의 대화 전략을 결정하였으니, 이제 말로 옮길 때 입니다. 이곳이 군대나 회사 같은 상하가 딱딱한 환경에서 상사에게 대답을 하는 것이라면, "아직입니다. 식사 여부를 여쭤봐도 괜찮겠습니까?" 라고 하겠지만, 상대는 그냥 친구입니다.
"아직 안 먹었는데, 너는?" 이라고 답하기로 결정합니다. 너무 딱딱하지도 부드럽지도 않은 것 같습니다.
5. 말하기
드디어 친구의 말을 듣고, 이해하고, 대화 흐름 전략을 생각하고, 답변을 결정하였습니다. 이제 입과 혀를 움직여 소리 신호를 생성해야 합니다. 만약 조용한 도서관이라면 작은 소리를 내도록, 만약 친구가 귀가 어두운 녀석이라면 큰 소리를 내도록 조절하도록 합니다.
이처럼 우리가 친구가 "밥 먹었냐"라고 했을 때 대응할 때 이처럼 많은 정보 처리가 이루어집니다. (일상대화가 가능하신 분들은 본인의 지능에 감탄하셔도 좋습니다.)
인간의 두뇌는 엄청나기 때문에 이를 아주 짧은 시간에 해냅니다. 한마디를 내뱉는데 1~2초만 걸려도 친구는 "괜찮냐" (또는 "왜 이래")라고 반응하겠죠.
사람의 사고 방식을 닮은 AI 대화 시스템
AI 대화 시스템(챗봇)이 대화를 하는 방식은 인간과 크게 다를 바가 없습니다.
AI 스마트 스피커에게 "오늘 서울 날씨 어때?"라고 했을 때 어떻게 처리되고 있는지 한번 살펴봅시다.
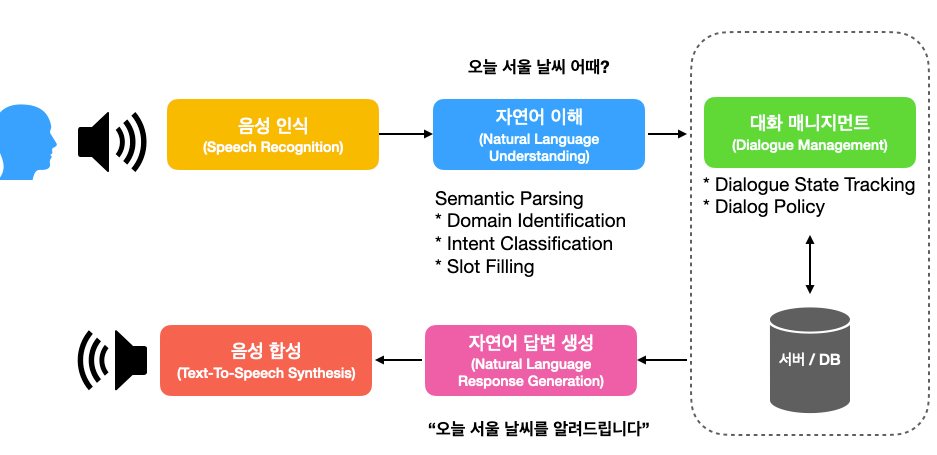
1. 듣기 = 음성 인식 (Speech Recognition)
음성 인식은 소리 신호를 언어 정보(텍스트)로 바꿔주는 기술입니다.
Week 15와 Week 16 에서 언어 모델과 어쿠스틱 모델으로 나누거나 이를 합쳐 E2E로 딥러닝 모델로 처리하는 기술이 있다고 배웠습니다.
만일 음성 인식 모델의 성능이 떨어진다면 그 이후 과정에서도 에러가 이어질 확률이 높겠죠. 시작부터 굉장히 어려운 문제입니다.
2. 이해하기 = 자연어 처리(Natural Language Understanding)
텍스트로 변환된 유저의 말을 의중을 파악하여 기계가 이해할 수 있는 언어로 번역하는 부분입니다. 이를 Semantic Parsing이라고 부르기도 합니다.
특히 대화 시스템에서 중요한 컨셉은 크게 Domain, Intent, Slot 세 가지입니다.
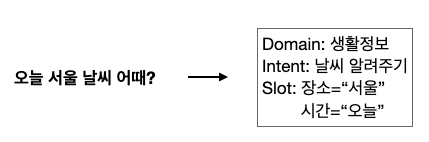
도메인(Domain)은 큰 범위에서의 대화 주제. 유저가 생활 정보를 원하는지, 생산성 기능(ex. 타이머)을 작동시키려는지, 음악 관련 기능을 원하는지, 대략적인 큰 범위를 분류하기 위해 사용.
의도(Intent)은 유저가 하고자 하려는 것에 대한 분류. "날씨 정보 알려주기", "타이머 시작하기", "타이머 끄기", "음악 재생하기", "음악 끄기" 등 각 도메인마다 각각 가능한 의도가 있을 수 있음. 이를 분류해야 대화 시스템이 다음 액션을 선택할 수 있음.
슬롯(Slot)은 유저의 니즈를 해결해주기 위해 필요한 정보. 예를 들어, "오늘 서울 날씨 어때?"에서 장소="서울", 시간="오늘", 두 가지 슬롯이 포함되어 있음.
3. 대화 흐름 생각하기 = 대화 매니지먼트 (Dialogue Management)
상대방의 의도를 파악하고 나서는 이를 위한 정보를 수집해야 합니다.
날씨 정보 같은 경우, DB 또는 외부 API로부터 끌어와야 합니다. 만일 타이머를 새로 만드는 것이라면, 타이머를 담당하는 서버와 소통을 해야 합니다.
만일 원하는 액션을 수행하지 못할 경우에는 유저에게 알려주어야 할 것 입니다. 에러(error)의 이유를 설명할 수 있다면 가장 좋겠죠. (ex. 이해에 실패한 것인지, 날씨 정보 서버가 먹통이라든지..)
만일 "서울"이라는 장소 이름을 빼고 "오늘 날씨 어때?"라고 했다면, 현재 유저의 위치를 서버에 요청해야 할 것 입니다. 위치 정보가 없다면, 유저에게 위치를 정보를 되물어봐야 할 것 입니다.
이처럼 상황 정보에 따라 다양한 대화 시나리오가 가능하다는 것을 알 수 있습니다.
4. 답변 생각하기 - 자연어 답변 생성 (Natural Language Response Generation)
AI 스마트 스피커의 답변이 "오늘 날씨: 맑음, 최대기온: 20도, 최저기온 15도"라면 아니면 "weather server error, code 500"라면 유저로써 어떻게 느낄까요? 답변 역시 우리가 사용하는 자연스러운 언어여야 좋은 경험을 줄 수 있을 것입니다.
어떻게 하면 자연스러운 답변을 만들 수 있을까요? 상황에 따라 수많은 대본(템플릿)을 사용하기도 하고, 언어 생성 모델을 따로 학습시키기도 합니다. 아직 사람만큼 완벽한 답변 생성 모델은 없는 만큼 앞으로 발전이 더 기대되는 분야입니다.
5. 말하기 - 음성 합성 (Text-To-Speech Synthesis)
답변을 생각해냈다면 이제 음성으로 만들어야 할 차례입니다. 텍스트를 소리로 변환시켜주는 부분인데요. 우리가 입술, 혀, 성대를 움직여 목소리를 내는 것과 같습니다.
이러한 기술을 TTS라고 부르는데, 꽤나 자연스러운 수준까지 발전하였습니다. 유명한 연구는 구글의 WaveNet이 있습니다.
오늘은 대화 시스템(Dialogue System)의 기본 구조와 흐름을 인간이 대화를 하는 것과 비교하여 알아보았습니다. 큰 그림을 먼저 그려보았는데요. 거의 대부분의 대화 시스템은 이 뼈대를 바탕을 만들어지고 있는 것으로 알고 있습니다.
각 주제/모듈을 하나하나 깊게 보면 굉장히 많은 연구가 진행되고 있습니다. 혹시 더 깊게 보기를 원하는 주제가 있다면 댓글로 남겨주시면 참고하도록 하겠습니다!

Reference
- Dan Jurafsky and James H. Martin, Speech and Language Processing, Chapter 24 Chatbots and Dialogue Systems



