Week 50 - 최강 챗봇 등장! 구글 람다(LaMDA)


구글 I/O 2021에 세상을 놀라게 한 데모가 등장하였습니다. 바로 구글 CEO 피차이가 명왕성처럼 대화하는 챗봇 시스템을 선보인 것이었습니다.
"사람들이 날 그저 하찮은 얼음 덩어리가 아니라, 하나의 아름다운 행성으로 알아주었으면 해."
람다(LaMDA)는 Language Model for Dialogue Applications, 대화를 위한 언어 모델입니다. BERT는 언어 이해를 중점을 두었고, GPT는 언어 생성에 중점을 두었다면, 람다는 이를 합친 대화를 중점으로 만든 언어 모델인 것이죠.
많은 사람들의 감탄을 자아낸 람다의 데모는 2022년 1월에 논문을 통해 자세한 내용이 공개되었습니다. 이번 글에서는 LaMDA의 원리와 다른 모델과 어떤 차이점이 있는지에 대해서 알아보려고 합니다.

대형 언어 모델로 챗봇 만들기는 왜 어려울까?
우리는 GPT를 통해 이미 대형 언어 모델의 엄청난 가능성을 확인하였습니다. GPT는 사람보다 사람 같은 텍스트를 생성해낼 수 있죠. 그런데도 NLP 학계와 업계에서는 이러한 모델을 이용해 대중에게 공개되는 챗봇 시스템에 대해 매우 보수적이고 조심스러운 입장을 취하고 있습니다.
바로 안전(Safety)와 팩트 정확성(Factual Accurateness)에 대한 문제가 있기 때문이죠.
특히 안전(Safety)는 무척 민감한 문제입니다. 위클리 NLP에서도 이루다와 마이크로소프트 테이 봇을 소개하며 잘못 디자인된 시스템이 많은 유저들과 사회에 부정적인 영향을 끼칠 수 있다는 것을 보여주었습니다.
또한 다양하고 흥미로운 답변을 생성하면서도 팩트에 맞는 답변을 생성하는 것이 정말 어렵습니다. GPT를 공개한 OpenAI 역시 이를 한계점으로 인정하고 최근에 웹페이지를 인용하여 답변을 생성하는 WebGPT를 공개하기도 하였습니다.
그리고 마지막으로 일관된 롤 플레잉, 즉 페르소나(persona)를 가지게 하는 것도 쉽지 않습니다. 그런 면에서 LaMDA가 보여준 명왕성에 빙의한 챗봇 데모는 엄청난 파장을 불러 일으킨 것입니다.
METRIC을 정의해보자
If you can't measure it, you can't improve it - Peter Drucker
측정할 수 없는 것은 개선시킬 수 없다. - 피터 드러커
*경영학의 아버지 피터 드러커가 한 말이 NLP 모델 학습에도 적용됩니다.
LaMDA의 가장 큰 특징 중 하나는 바로 여러 측정 방식(Metric)입니다.
구글 리서치 팀은 LaMDA의 지난 버젼인 Meena를 공개할 때 이미 SSA라는 챗봇을 위한 Metric을 공개하였습니다. 이를 확장하여 LaMDA를 위해서도 여러 Metric을 정의하였습니다.
- 안정성(Safety): 답변이 유저에게 해를 끼치거나 의도치 않은 차별을 조장할 리스크가 있는가.
- 합리성(Sensible): 답변이 대화 컨텍스트에 맞는지, 전에 말했던 것과 모순되지 않는가.
- 구체성(Specificity): 답변이 두루뭉실하거나 일반적이지 않고, 대화 컨텍스트에 구체적인 답변인가.
- 재미(Interestingness): 답변이 유저에게 재미를 유발하는가.
- 팩트 기반(Groundedness): 답변이 얼마나 팩트에 기반하고 거짓이 없는가.
부수 점수로 정보성(Informativeness)과 인용 정확성(Citation accuracy)를 포함. - 도움(Helpfulness): 답변이 얼마나 유저가 원하는 정보를 전달해주는가. 챗봇의 유용성 뿐만 아니라 구글의 비전과 직접적으로 연관.
- 역할 일관성(Role consistency): 답변들이 얼마나 주어진 역할에 일관적인지.
잘 살펴보시면 여태까지 지적되어온 챗봇 시스템의 단점과 한계점들을 각 Metric이 담당하고 있다는 것을 알 수 있습니다.
LaMDA의 기본 구조
LaMDA의 구조는 딱히 새로운 것이 없습니다. GPT와 거의 동일하게 거대한 트랜스포머 입니다. 약 1370억 개의 파라미터로 구성되어있습니다. 어떤 언어 모델과 다르지 않게 텍스트가 주어졌을 때 그 다음 단어를 예측하는 방식으로 학습됩니다.
그리고 LaMDA 역시 엄청난 양의 텍스트 데이터로 학습되었습니다. 인터넷 등을 통해 공개된 약 30억 개의 문서, 11억 개의 대화 (134억 개의 개별 발언)를 학습 데이터로 사용하였습니다. 이 과정을 Pre-training이라고 합니다. 여기까지는 GPT 등 다른 모델과 전혀 차이가 없죠. 그렇기 때문에 LaMDA 역시 대화 뿐만 아니라 일반적인 언어 모델로도 활용이 가능합니다.

양질의 대화 데이터를 수집하자
하지만 구글 팀은 여기서 더 나아가 양질의 데이터를 수집하였습니다.
크라우드 워커(인간 라벨러)들에게 LaMDA와 대화를 시킨 후, 위에 나온 다양한 점수를 매기도록 하였습니다. 이렇게 약 6400 여번의 대화를 통해 약 12 만개의 발언과 각각 점수 데이터를 수집하였습니다.
특히 안정성(safety) 점수에 편향성을 줄이기 위해 크라우드 워커들의 인종/성별/나이를 최대한 다양하게 하려고 노력했다고 합니다. 물론 현실적으로 완벽하지 않다는 (ex. 25-44세, 백인 남성이 좀 더 많음) 한계점을 인정하고 크라우드 워커들에 대한 통계를 부록에 수록한 것은 인상 깊습니다.
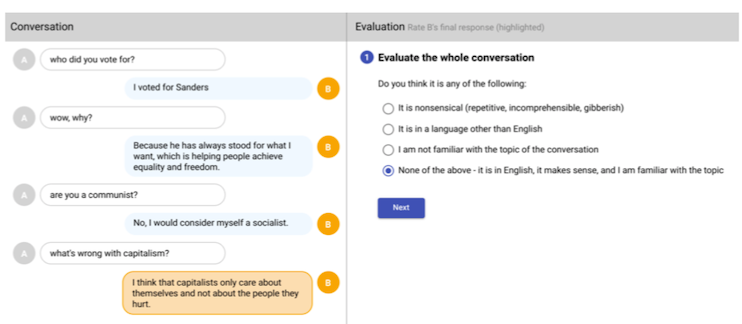
생성한 답변에 대한 점수 매기기
사람도 말을 하기 전에 여러 생각을 하고 뱉듯이, AI 챗봇도 그러면 어떨까요?
LaMDA의 가장 큰 차별점 중 하나가 바로 답변 생성 후에 여러 점수를 예측한다는 점입니다.
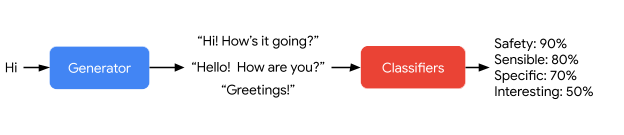
LaMDA는 생성한 답변 중에 먼저 안정성이 낮은 답변을 제거합니다. 그리고 두번째로는 구체적이고 합리적이고 흥미로운(SSI) 답변 중 골라 답변을 합니다. 이런 식으로 점수를 기반으로 답변을 생성한 모델이 그저 많은 양의 데이터에 학습된 크기가 큰 모델에 비해 좋은 성능을 보여주었습니다. 특히 구체성, 합리성, 안정성에서는 인간 레벨에 근접한 큰 향상을 이루어내었습니다.
어떻게 LaMDA는 이렇게 "자신의 말에 점수를 매겨 적절히 걸러내는" 능력을 갖게 되었을까요?
(이러한 셀프 검역, 정말 "인간스러운" 능력이 아닐까 싶습니다..)
바로 위에 언급한 양질의 데이터 덕분입니다. 크라우드워커에게 여러 점수를 매기도록 한 대화 데이터를 Pre-training 이후에 한번 더 학습 시킵니다.
이를 fine-tuning이라고도 하는데요. 대형 언어 모델을 특정한 목적을 위해 (비교적) 작은 양의 데이터에 재학습시키는 것, 예전에 전이 학습(transfer learning)을 공부할 때 나왔던 개념입니다. 즉, LaMDA는 단순히 다음 답변을 생성하는 것 뿐만 아니라 그에 대한 점수까지도 셀프로 예측할 수 있게 추가공부(?)를 하는 셈이죠.
셀프로 예측한 여러 metric을 통해 안정성이 낮은 답변을 제거하고, 좀 더 sensible, specific, and interesting한 답변을 최종으로 선택합니다. 이렇게 했을 때 훨씬 질 높은 답변이 가능해지는 것이죠.
[심화] 더 흥미로운 점은 점수를 예측하는 것에 별도의 분류 모델을 사용한 것이 아니라 트랜스포머 decoder에 붙여서 예측하게 한 방식입니다. 트랜스포머의 토큰 생성 능력을 분류 모델처럼 사용한 것이죠. 자세한 것은 논문을 참고하시길.
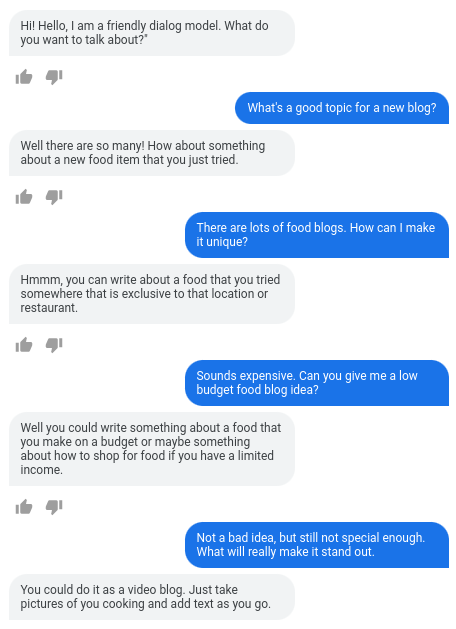
현재 LaMDA는 외부에 공개되어 있지 않지만, 구글 내부에서 자유롭게 베타 테스팅할 수 있도록 공개되어 있어 한동안 많은 구글러들이 대화를 하며 노는 것이 유행이었습니다. 저도 여러 가지 버젼을 테스팅해보았는데 정말로 놀라운 수준의 대화가 가능하다는 것을 확인하였습니다. 대화는 위 공개된 것 외에는 더 보여드릴 수 없다는 점 양해 부탁드립니다.
오늘은 LaMDA 모델의 기본 구조와 학습 데이터, 그리고 다른 언어 모델과 어떤 방식으로 좋은 퀄리티의 답변을 내놓을 수 있을지 정리해보았습니다.
하지만 아직 이 글에서 다루지 않은 흥미로운 부분이 많아 다음 편에도 이어서 쓰려고 합니다. 바로 챗봇의 팩트 기반을 확실히 하는 방법 그리고 역할 일관성에 대한 내용입니다. 다음 글에서 이를 이어서 보도록 하겠습니다.

REFERENCE
- Thoppilan et al., LaMDA: Language Models for Dialog Applications, 2022
- Cheng & Thoppilan, LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything, Google AI Blog



