대규모 언어 모델(LLM)은 엔진이다
LLM 엔지니어링에 대한 단상 - 1


Image generated by playground ai; Prompt - "Alphabet letters coming in and out of a mechanical engine".
대규모 언어 모델, LLM이 올해 전세계를 휩쓸고 있습니다. 정말 무섭도록 빠르게 기술이 발전하고 있습니다.
매주 여기저기서 새로운 모델이 출시되고 있어, 하나한 따라잡기 어렵습니다. 솔직히 말해서, 몇 가지 "획기적인" 연구 외에는 다 캐치업을 하고 있지 않지만, 저는 요즘 계속 머리에 떠오르는 주제가 있었는데요: “LLM이 어떻게 소프트웨어 엔지니어링에 영향을 끼칠 것인가”였습니다.
운좋게도 저는 비교적 일찍 스케일이 큰 LLM을 만져볼 프로젝트 기회들이 있었습니다. 또한 최근에 공유되는 여러 LLM 엔지니어링에 대한 다양한 글을 읽기도 하고, 직접 작은 실험도 해보기도 했죠.
다음 두 포스트에서 LLM 엔지니어링에 대한 제 생각을 공유하려고 합니다. 이 분야는 빠르게 변화하고 있기에, 언제든지 바뀔 수 있는 아이디어 정도로 생각해주시면 감사하겠습니다.
이 포스트의 내용은 제 개인적인 의견이며 제 회사를 대변하지 않습니다. 공개되지 않은 정보를 공유하지 않습니다.
Google Bard와 함께 제 자신의 글을 번역 및 편집했습니다. (원문)

LLM이란?
기본 개념부터 다시 살펴 볼까요. 언어 모델이란 문장에서 다음 단어를 예측합니다. 방대한 텍스트 및 코드 데이터로 학습되어, 다양한 작업을 수행할 수 있죠. 예를 들어, 텍스트 생성, 언어 번역, Q&A 등을 할 수 있습니다. 일부 사람들은 “고도화된 자동완성”이라고 하기도 합니다. 그러나 최근에 나온 대규모 언어 모델(LLM)은 더 많은 규모와 데이터를 통해 단순히 텍스트 자동완성이 아니라 주어진 지시(instruction)를 따를 수 있게 되었습니다. 정말 마법처럼 인간이 몇 시간 또는 며칠이 걸리는 창의적이고 지능이 필요한 작업을 몇 초 만에 수행할 수 있습니다.
LLM은 두 가지 유형으로 나눌 수 있습니다: [1] Vanilla* [2] Instruct-led.
Vanilla LLM은 다음 단어를 예측하도록 학습되지만, Instruct-led LLM은 사용자 프롬프트에 들어 있는 지시를 따르도록 추가로 학습됩니다.
Instruct-led LLM은 "Reinforcement Learning In Human Feedback (RLHF)"라는 기술을 사용하여 추가 데이터를 사용해 LLM이 사용자가 준 지시를 이해하고 답변할 수 있도록 학습됩니다. 그래서 이러한 인풋 텍스트를 "프롬프트(prompt)”라고 부르고 LLM의 행동 변화를 위해 텍스트를 바꾸는 것을 "프롬프팅(prompting)”이라고 부릅니다.
*다른 토핑이 올려져 있지 않은 가장 기본적인 바닐라 아이스크림에서 나온 용어입니다. 가장 기본적인 모델을 일컫습니다.
따라서 어떤 LLM을 사용할지 선택할 때 Vanilla인지 Instruct-led로 학습되었는지 꼭 체크하는 것이 중요합니다.
LLM은 엔진이다?
LLM은 제품 그 자체가 아니라 제품을 만들기 위한 엔진입니다. 엔진은 무언가를 움직이는 힘을 제공하지만, 다른 파트가 있어야만 비로서 가치를 제공할 수 있죠. 예를 들어, 자동차 엔진은 바퀴, 차체, 운전 휠 등이 함께 있어야 하나의 자동차를 완성시킬 수 있습니다.
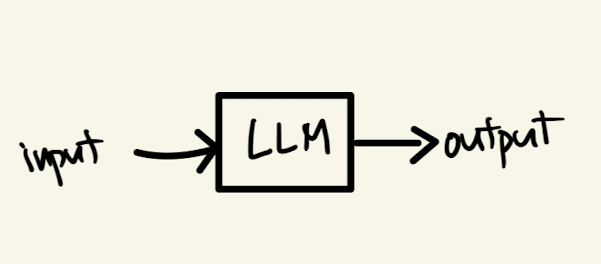
LLM도 마찬가지로 하나의 유용한 제품이 되려면 다른 구성 요소가 필요합니다. 예를 들어, 인풋 프롬프트의 포맷이라던가 LLM의 아웃풋을 후처리(postprocessing)해야 할 수도 있습니다. 또한 사람들이 쉽게 사용할 수 있도록 UI가 있어야 하겠죠. LLM 엔진을 어떻게 사용할지는 디자이너와 개발자에 따라 크게 달라질 수 있습니다.

일부 회사는 자체 엔진 그리고 이를 사용한 제품을 모두 만듭니다. 예를 들어, Google과 OpenAI는 자체 LLM을 훈련하고 Bard 및 ChatGPT와 같은 제품을 출시했죠. Meta의 경우에는 Llama라는 엔진을 제공하고 있죠. 마치 Rolls-Royce가 비행기 엔진을 제조하지만, 비행기 자체를 제조하지 않는 것과 비슷하죠. 또 다른 회사들은 특정 데이터에 Fine-tuning된 맞춤형 LLM 엔진을 개발할 수도 있습니다. 예를 들어, Bloomberg는 금융에 맞는 LLM을 개발했습니다.
대부분의 회사는 LLM을 처음부터 만들지 않고, 다른 회사에서 학습된 엔진을 활용할 것입니다.
이는 LLM을 처음부터 만드는 것이 매우 비싸기 때문입니다. 비용의 대부분은 사전 훈련 단계(pre-training)에서 발생합니다. 이 단계는 수천 개의 GPU를 이용해 수개월 동안 모델을 학습시키기에, 비용만 해도 수백만 달러가 필요합니다. 풍부한 리소스를 보유한 회사 또는 소수의 오픈 소스 프로젝트만이 이를 감당할 수 있겠죠.

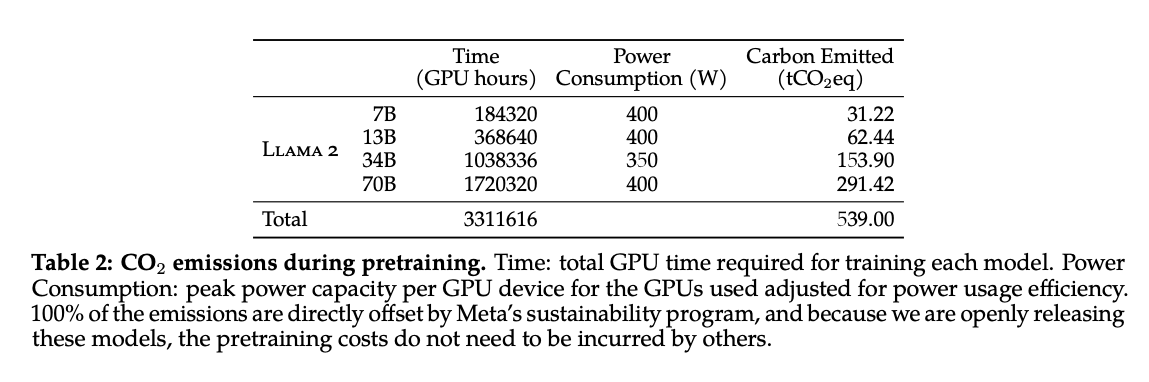
어찌 됬든 지구를 위해서라도 이런 식으로 LLM이 발전하는 것이 바람직하다고 생각합니다. 아래 Llama 2 논문에서 한 개의 모델을 훈련하는 동안 얼마나 많은 탄소가 배출되었는지 계산해 공개한 부분을 살펴보면 꽤 많다는 것을 알 수 있습니다.
LLM 사용법
현재 LLM을 사용하는 방법은 크게 두 가지가 있습니다.
- API 호출: 가장 간단한 방법입니다. API를 호출하는 몇 줄의 코드를 작성하기만 하면 필요한 결과를 얻을 수 있죠. 이는 소규모 프로젝트 또는 자체 LLM을 호스팅하는 번거로움을 겪고 싶지 않은 사람들에게 가장 간편한 옵션입니다.
- 자체 호스팅: 모델에 대한 더 많은 컨트롤이 필요로 하거나 대규모 프로젝트에 사용해야 하는 경우 자체적으로 호스팅할 수 있습니다. 이는 더 많은 기술적 노하우가 필요하지만 더 많은 유연성과 컨트롤을 제공합니다.
API 호출
Google, OpenAI, HuggingFace 등 다양한 회사에서 LLM API를 제공합니다. 이러한 API는 어떤 사람이든, 어떤 목적이든 간에 아주 쉽게 LLM을 사용할 수 있게 만들었습니다. 간단한 API 클라이언트 코드를 작성할 수 있는 개발자는 누구나 LLM 모델의 파워를 활용해 앱을 만들 수 있습니다. 이 방법의 장점은 인프라, 속도, 모델 학습 등 어려운 부분은 전부 API 제공업체가 해준다는 점입니다. 클라이언트는 그저 API 콜에 대해 돈을 내기만 하면 되죠.
이렇게 LLM에 대한 진입 장벽이 획기적으로 없어지면서 NLP라는 분야는 완전히 판이 바뀌었습니다. 최근 1년 동안 API를 통해 LLM을 실험하는 사람들이 급증했고, 흥미로운 앱도 많이 나오기 시작했습니다. 일부에서는 이것이 모바일 앱 생태계를 연 iPhone의 앱스토어 출시보다 더 큰 현상이라고 말합니다. 이제 중고등학생도 최소한의 코딩 지식만 알고 있다면 상당히 잘 작동하는 챗봇을 만들 수 있는 세상이 되었기에, 저와 같은 NLP 엔지니어는 커리어에 큰 위기가 온 시기입니다!
그러나 API 호출에는 몇 가지 단점이 있습니다.
- 속도: API 호출은 앱에 지연 시간(latency)추가할 수 있습니다. API 요청을 보낸 후 결과를 돌려 받는 시간이 있기 때문입니다.
- 비용: 각 API 호출에 대해 비용을 지불해야 하는데, 대규모 프로젝트에 API를 사용하면 비용이 많이 들 수 있습니다.
- 데이터 프라이버시: API에 전달하는 데이터는 API 소유자에게 공개되고 그들의 서버에 저장됩니다. 때로는 모델 품질 개선을 위해 사용될 수도 있다는 약관이 있고는 합니다.
- 제한된 컨트롤: 인풋의 길이와 파라미터 선택은 API에서 제공하는 것에 따라 크게 제한됩니다.
자체 호스팅
이에 대한 대안으로, LLM을 자체 호스팅하면 모델과 데이터에 대한 더 많은 컨트롤을 얻을 수 있습니다. API를 호출하기에는 너무 느리거나 비싼 복잡한 작업에도 LLM 모델을 사용할 수 있습니다. 그러나 자체 LLM을 호스팅하는게 꼭 쉬운 것만은 아니기에 선뜻 선택할 옵션은 또 아닙니다.
최근에 다양한 크기의 다양한 오픈 소스 LLM이 급증하고 있습니다. 특히 Meta의 Llama 2는 유출된 이전 모델과 달리 이제 상업적으로 사용할 수 있기에 가장 큰 주목을 받고 있고, StableLM과 MPT 같이 자신들이 다른 주요 모델보다 더 낫거나 비슷한 퍼포먼스를 보여준다고 주장하는 모델들이 속속 출시되고 있습니다.
장점
- 데이터 소유권: 인풋과 아웃풋이 제3자를 거치지 않아도 됩니다. 어떤 프로젝트에는 소유권이 가장 중요한 결정 포인트가 될지도 모릅니다.
- 비용: 대규모 데이터를 처리해야 할 경우 API를 호출하는 것보다 비용이 낮을 수 있습니다.
단점
- 인프라 난이도: LLM을 자체 호스팅하기 위해서는 인프라를 만들고 유지 관리해야 하는데 기술적인 난이도가 있습니다. 클라우드 업체에서 점점 더 쉽게 만들 것으로 보이지만, 여전히 API에 비하면 전문 기술력이 필요합니다.
- 성능: LLM은 더 커질수록 성능이 더 좋아지는 경향이 있는데, 정말 거대한 모델은 자체 호스팅하기가 훨씬 더 어렵습니다.
또한 자체 LLM은 커스텀 독점(proprietary) 데이터로 추가로 튜닝할 수도 있습니다. 그러나 fine-tuning(지도 학습 또는 RLHF) 역시 기술적인 난이도가 높은 작업이기에, 앞으로는 finetuning-as-a-service를 제공하는 더 많은 회사가 생길 것이라고 생각합니다.
이번 글에서는 LLM 엔지니어링에 대해 전반적인 개념을 잡아보았습니다. 가장 중요한 포인트는, “LLM은 제품이 아니라 엔진이다”입니다. 이러한 관점이 많은 제품 디자이너들과 개발자 분들에게 LLM 활용에 있어 영감이 되었으면 하는 바람입니다.
다음 글에서는 자연스럽게 떠오르는 질문, “그럼 LLM을 가지고 일하는 소프트웨어 엔지니어는 뭘해야 하나?”에 대해서 다루려고 합니다. 살짝 스포일러를 드리자면 프롬프트 엔지니어링도 해야 하지만, 그 이상의 일도 해야 한다는 점입니다!




