

Grasping other person’s emotions or sentiments through a text is challenging even for humans sometimes. I bet you also have an experience that once you were reading someone’s message multiple times to figure out, “Is he/she upset? Or am I too sensitive?” Emotion and sentiment in textual communication are often ambiguous. There are no other signals like facial expression and voice tones, which in general helps to clear out the uncertainty when seen all together.
Despite the difficulties, figuring out emotion or sentiment in texts is crucial nowadays, due to our daily habit of using emails, mobile messengers, social media, chats (games, video, live stream, etc.). Many of us now prefer texts to phone calls for everyday communication. To clearly articulate our emotions just through texts, we created new methods like emoticons, emojis, and memes. You would be surprised how South Koreans produce hundreds of new emoji/emoticons to playfully express their emotions. This is a global phenomenon.
SemEval-2018: Affect in Tweets
Semantic Evaluation(SemEval), an ongoing serious of evaluation started in 1998, is a well-known to many natural language processing researchers for proposing many different interesting tasks to the field to solve together. It also has some competition aspect by having rankings on shared datasets and evaluation metrics, although the primary purpose is to share ideas and facilitate discussion related to the tasks. This year in SemEval 2018 (to be held as a workshop of NAACL 2018), three interesting tasks related to emotions/sentiment have been included: (1) Affect in Tweets, (2) Multilingual Emoji Prediction and (3) Irony Detection in English Tweets.
This post is to introduce our effort on solving the first task, Affect in Tweets (task description), which was to train a machine learning system that can predict the emotion/sentiment categories and intensities of a tweet. To give you a heads up, our system performed TOP-3 in all five subtasks in the final leaderboard and will be presented during the workshop in June (New Orleans, USA)!
Problem
It’s always data, data, data.
The given competition datasets were in the magnitude of thousands (around 1000~2000 tweets per emotion category). I would say this is not a small dataset, but, in the era of BIG DATA, I can say, “not good enough.” If you think about how many variations of emotional expression in the English language, I would have to say thousands of examples is not sufficient. Although it might work well in the competition test set, I wanted to make a model that can generalize better.
How?
Thanks to the endless stream of social media such as Twitter and Facebook, researchers nowadays are lucky enough to have access to almost an unlimited number of texts generated every day. Nevertheless, for a machine to learn what emotion is inside these texts, there needs to be some answer. Think about a student studying for an exam. Questions with answers are definitely the most helpful. This is called supervised learning in machine learning literature.
However, asking humans for answers about the explicit emotion or sentiment of these texts is very expensive in terms of money and time. For this reason, many works naturally focused on finding direct or indirect evidence of emotion inside each text, such as hashtags and emoticons (Suttles and Ide, 2013; Wang et al., 2012), and found them useful.
Emoji as a hint of emotion
Although emojis inside sentences do not always show the exact emotions of the texts, they do have high correlations. They might even contain subtle differences among emotion categories and intensities. This recent work (Felbo et al., 2017) showed that teaching machines to predict what kind of emoji this text might have can make them perform better on related tasks such as sentiment analysis.

We also conducted a similar approach by using our own crawled emoji tweet dataset. In total, we gathered 8.1 million emojis and clustered similar emojis to form categorical label groups for training a classifier, which predicts which label group does this text belongs to. After training the classifier, we were able to project each sample in a high dimensional space. The reason we did this was to see whether samples with similar emotions were clustered together.
As seen above, the model effectively learned the similarities of emotions among different texts. Now we can use this model to solve our competition task (SemEval-2018).
This kind of method is called Transfer learning in machine learning literature, because we are teaching the model to predict emojis of the text but later transfer that knowledge to predict the emotion and sentiment of the text.
Results on the competition
One of the main tasks is predicting the intensities of the emotion and sentiment of texts. Predicting a scalar value for something is called regression. (You might be familiar with the word, “linear regression.”) For this competition, we trained a non-linear kernel regression model (support vector regression & kernel-ridge regression) to find the mapping between the texts and the emotional intensities. This is because we use neural network models as feature extractors. Those models tend to be excellent at finding non-linear relationships that are powerful for many tasks. Note that we use deep learning as feature extractors, but use traditional machine learning methods for the final tasks.
With the regression model, we were also able to perform well in ordinal classification tasks (ranking the intensities in integer values). For more details, please check the paper to look at our interesting mapping techniques.
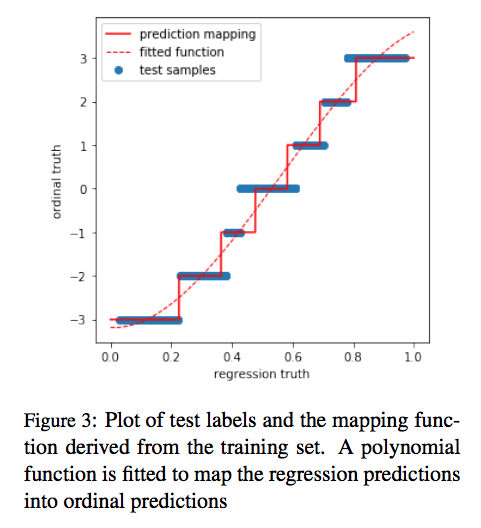
As a result, we were able to rank top-3 in all five subtasks. We used external datasets, which were much larger than the competition dataset but distantly labeled with emojis and #hashtags, to exploit the transferred knowledge to build a more robust machine learning system to solve the task. We avoided using traditional NLP features like linguistic features and emotion/sentiment lexicons by substituting them with continuous vector representations learned from huge corpora.
**For simplicity, we only wrote about the emoji part of the research. For more details like how we used hashtags, please refer to the original paper (https://arxiv.org/abs/1804.08280)!