Week 31 - 이루다 같은 챗봇은 어떤 원리로 작동하는 걸까?


2021년 1월 새해가 밝자마자 한국 스타트업 업계에 자연어처리(NLP)가 화두로 떠올랐습니다. 바로 스캐터랩이라는 회사가 공개한 이루다라는 챗봇 때문입니다. "너와 매일 일상을 나누고 싶어! 나랑 친구할래?"라는 슬로건으로 나와 항상 친구처럼 대화를 할 수 있는 AI를 지향한 이 제품은 상당히 인간 같은 대화를 구사하는 것으로 관심을 끌었습니다. 많은 사람들이 상당히 재밌어하고 놀라했죠. 하지만 몇 주가 되지 않아 개인정보 유출, 혐오 발언 등 여러 가지 논란을 남기고 서비스를 중단해야만 했습니다. 이러한 논란에 대해 알아보기 전에 먼저 이루다 같은 챗봇은 어떤 원리로 작동하고 있는지 궁금하시지 않은가요? 어떤 기술인지 알아야만 문제로 지적되는 것들도 정확하게 가치 판단할 수 있다고 생각합니다. <위클리 NLP> 2021년 첫글은 챗봇으로 시작합니다!

대화 시스템의 종류
대중들이 주로 챗봇(chatbot)이라고 부르는 기술은 NLP 학계에서는 대화 시스템(dialogue system)이라고 부르고, 크게 두 가지로 구분이 됩니다.
- 문제 해결용 대화 시스템(Task-oriented Dialogue System): 문제를 해결하기 위해 설계된 시스템입니다. 우리가 주로 많이 쓰는 구글 어시스턴트, 시리, 알렉사, 빅스비가 이 종류에 속합니다. 이 시스템은 최대한 적은 대화로 이용자가 원하는 것을 이해하고 해결해주려는 것에 초점이 맞추어져 있습니다.
- 자유 주제 대화 시스템(Open domain Dialogue System): 수다를 위해 만들어진 시스템입니다. 유저가 어떠한 주제로 말을 걸어도 시스템은 이에 알맞은 답변을 하여 대화를 이어나가기 위해 만들어집니다. 지속적으로 유저의 흥미를 유발하여 최대한 긴 대화를 하는 것이 목적입니다.
이루다는 자유 주제 대화 시스템 챗봇입니다. 몇몇 분들은 2002년에 나온 심심이라는 서비스를 기억하실지도 모르겠습니다. 근본적으로 이루다와 심심이는 같은 목적을 가지고 있습니다. 지루하지 않게 흥미로운 대화를 최대한 오래하는 것.
**이번 글에서는 이루다를 포함해 자유 주제 대화 시스템에 쓰이는 NLP 기술에 대해 이야기해보겠습니다. 문제 해결용 대화 시스템은 다음 글에 자세히 다루도록 하겠습니다.
자유 주제 대화 시스템을 만드는 기술에는 대표적으로 두 가지 모델 방식이 있습니다.
- 답변을 직접 생성하는 모델
- DB에서 답변을 고르는 모델
1. 답변을 직접 생성하는 모델
지난 글에서는 한참 글을 직접 쓰는 언어 모델(Language Model)에 대해서 다루었습니다. 트럼프의 트위터로 시작해, 외국어 번역, 이미지 캡션, 그리고 장문의 블로그 글도 척척 쓰는 GPT. 이러한 모델을 사용하면 대화도 할 수 있지 않을까요?
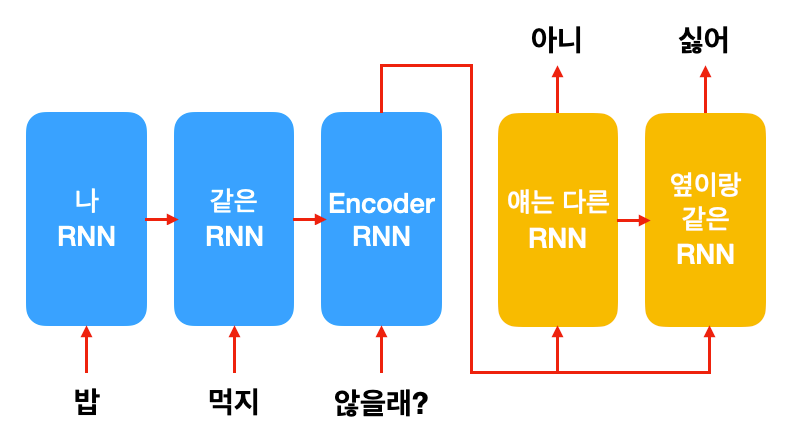
이러한 식으로 seq2seq 모델을 기반으로 한 대화 시스템은 2015년에 처음 구글의 Neural Conversational Model이라는 연구로 시도되었습니다. 이 딥러닝 모델은 유저의 말을 읽고, 답변을 한 단어 한 단어씩 생성합니다. 그래서 이를 생성 대화 모델(Generative Conversational model)이라고 합니다.
그 이외에 많은 후속 연구가 진행되었는데 그 중 가장 대표적인 연구자는 Jiwei Li입니다. 그의 박사 학위 논문 <기계에게 대화를 가르치는 법>을 읽으면 2015년부터 2017년 사이의 챗봇 연구를 전부 공부할 수 있습니다.
그의 연구에서 던지는 문제들은:
- 좀 더 다양한 답변을 생성할 수 있을까?
- 좀 더 일관성 있는 캐릭터를 가진 챗봇을 학습시킬 수 있을까?
- 좀 더 긴 대화를 이끌 수 있을까?
- 모르는 것을 물어보는 챗봇을 만들 수 있을까?
- 인간이 직접 가르치는 챗봇을 만들 수 있을까?
이 질문들을 보면 답변을 직접 생성하는 모델이 가지는 문제점도 짐작할 수 있습니다.
1. 좀 더 다양한 답변을 생성할 수 있을까? => 답변이 평이해지기 쉬움
seq2seq 모델은 Maximum Likelihood 로 학습이 되기 때문에 자주 나오는 "I don't know.", "Yes" 같은 평이한 답변을 자주 생성하기 쉬습니다. 어떤 대화든 확률적으로 가장 높은 답변이기 때문이죠.

2. 좀 더 일관성 있는 캐릭터를 가진 챗봇을 학습시킬 수 있을까?
한 사람의 데이터가 아니라 수많은 사람들의 대화 데이터를 섞어서 학습시키기 때문에 일관성을 가지는 것이 쉽지 않습니다. 아래처럼 어디 사냐고 물어보았을 때 오락가락하는 경우가 많았죠.

3. 좀 더 긴 대화를 이끌 수 있을까?
바로 직전의 대화 말고도 여태까지의 대화 기록(context)을 감안해서 답변을 생성해야 하는 것이 어렵습니다. 또한 유저가 지속적으로 더 대화를 할 수 있게 유도를 하는 식으로 답변을 하는 것 역시 어려웠죠.
4. 모르는 것을 물어보는 챗봇을 만들 수 있을까?
챗봇은 세상에 존재하는 사실 관계에 대한 데이터베이스가 없기 때문에 주어진 학습 데이터 안에서 답을 찾으려고 합니다.그렇기 때문에 가짜 사실, 혐오, 상식에 어긋나는 발언을 생성해낼 수 있는 리스크가 있습니다.
5. 인간이 직접 가르치는 챗봇을 만들 수 있을까?
사람은 지속적인 대화에서 나오는 피드백을 통해 나날히 발전하는데, 챗봇은 실시간으로 이러한 정보를 반영하기 어렵습니다.
그렇게 첫 생성형 챗봇이 나온지 거의 5년이 되고, 딥러닝 모델들을 엄청난 발전을 거듭했습니다. 이제는 더 빠르게 훨~~씬 더 큰 모델을 굉장히 많은 데이터로 학습시킬 수 있는 세상이 되었죠. 그렇게 나온 것이 대표적인게 GPT-3입니다. 지난 글에서 GPT-3를 소개했을 때 이 모델 역시 일종의 대화를 생성해냈지만, 사실은 대화를 위해 학습이 된 모델은 아닙니다. 그저 인터넷 데이터에 있는 대화의 파편들을 학습하는 것이지요.
그렇다면 정말 대화를 위해 학습된 모델 중 끝판왕은 무엇일까요? 바로 2020년 초 발표된 구글의 미나(Meena)입니다.
GPT처럼 모델과 학습 데이터의 스케일을 엄청나게 올렸습니다. 그러다 보니, "좀 더 다양한 답변을 생성할 수 있을까?", "좀 더 긴 대화를 이끌 수 있을까?" 같은 문제들은 어느 정도 해결이 된 것으로 보입니다.
미나의 원 논문을 읽어보면 대화의 품질을 좀 더 구체적으로 측정하기 위해 SSA라는 새로운 점수를 소개합니다. 이 점수는 얼마나 답변이 구체적이고 말이 되는지를 사람인 심사자들에게 물어보아 채점을 하는데, 그냥 인간의 대화가 86점일 때 미나는 79점을 받았다고 합니다. 그만큼 사람 못지 않은 대화 실력을 갖추었다고 평가할 수 있겠습니다. (다만, 구글은 이 시스템은 대중들에게 공개하고 있지는 않습니다)
2. DB에서 답변을 고르는 모델
답변을 직접 생성하는 모델은 한 단어 한 단어 생성해야 하기 때문에 많은 연산이 필요합니다. 그리고 높은 품질에 도달하려면 엄청나게 큰 모델, 많은 데이터가 필요하죠. 그렇기 때문에 이를 보완한 것이 Retrieval-based model, 즉 DB에서 답변을 고르는 모델 방식입니다. 이루다는 이러한 방식을 채택하였습니다.
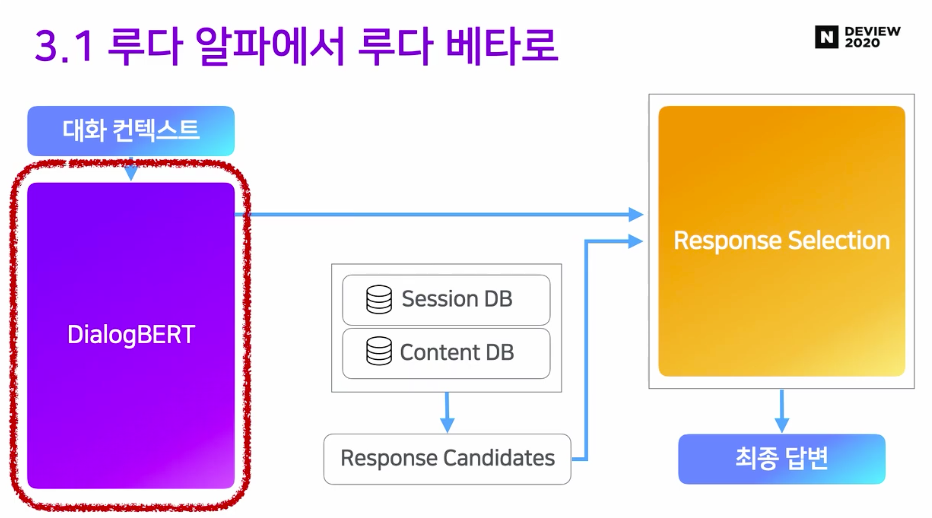
루다AI는 카톡 대화 데이터에서1억여 개의 답변 DB를 구축한 후, 여태까지 진행된 대화와 마지막 유저 메세지를 보고, DB에서 그럴듯한 N개의 최종 답변 후보를 뽑은 후, 좀 더 자세히 검토해 한 개의 답변을 선택합니다.
각각 살펴볼까요.
1. DialogBERT (자연어 이해, NLU 모듈)
- 일단 유저의 메세지를 했는지 이해를 해야 답변을 할 수 있겠죠. 그런데 사실 여기서 "이해"라는 단어는 참 모호한 단어입니다. 여기서 "이해"는 텍스트로 구성된 메세지를 하나의 벡터로 치환하는 과정을 말합니다. 이 대화가 데이터의 어떤 데이터와 비슷하고 다른가, 이를 벡터를 치환하여 알아냅니다. 이 치환을 담당하는 모델은 바로 BERT 구조를 가지고 있습니다. 이루다는 스캐터랩에서 수집한 카카오톡 대화 데이터를 가지고 BERT 모델을 학습시키고 이를 DialogBERT라고 부르고 루다AI의 자연어 이해 모듈로 사용하고 있습니다.
2. Session DB / Content DB => Response Candidates
- 답변 후보들을 저장해놓은 데이터베이스입니다.
- 이루다 팀은 수집한 카카오톡 대화 데이터 중에 질 높은 대화와 답변을 미리 선별해 DB에 저장하였습니다. 이 때 중복 문장, 퀄리티가 낮은 문장, 페르소나에 맞지 않은 응답, 적절하지 않은 응답 등을 필터링 거쳤다고 합니다.
- 이 DB에서 여태까지 진행된 대화와 직전 유저의 메세지를 보고 가장 비슷한 답변 후보를 N개를 선정합니다. 정확히 몇 개를 선정하는지는 모르지만 아마 수십 개에서 수백 개일 것으로 추정됩니다. 실시간으로 약 1억 개 이상의 답변 후보를 검토할 수 있게 했다고 합니다. 미리 계산된 문장 벡터들을 차원 축소를 해 DB에 저장한 후 코사인 거리(Cosine Similarity)를 빠르게 계산해 선별하였다고 합니다.
3. 최종 답변 선택 (Response Selection)
- 위 모듈에서 선정된 N개 중에 하나를 고르기 위해 또다른 머신러닝 모델이 사용됩니다. 이를 Re-ranker이라고도 하는데, 1억 개의 답변 중에 한번 빠르게 후보들을 추리고, 최종 답변을 고르기 위해 좀 더 자세하게 들여다보는 것이라고 생각하시면 됩니다. 모든 후보들을 자세히 보려면 시간이 너무 오래 걸릴테니 말이죠.
- 일관성을 위해 각 개별 대화 데이터를 또 학습하고, 또 위에 구글 논문에서 제시된 SSA 점수를 기반으로 데이터를 추가로 레이블링해 재학습하는 등 여러 가지 미세 조정을 통해 성능을 높였다고 합니다.
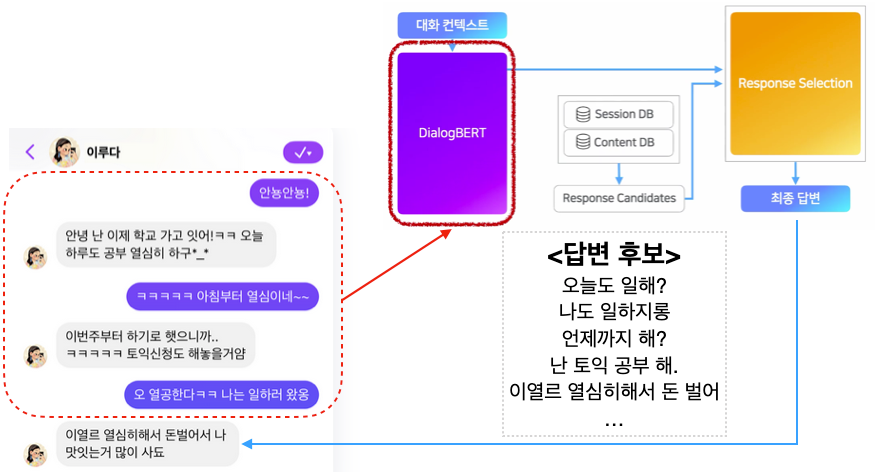
여기서 답변을 생성하는 모델(Generative model)과 가장 큰 차이점은 모든 답변은 기존의 데이터에서 미리 선별된 DB에서 나온다는 것 입니다. 이러한 방식의 가장 큰 장점은 답변이 무척 자연스럽다는 것 입니다. 실제로 사람이 쓴 글이기 때문이죠. 워낙 많은 답변 후보가 있기 때문에 왠만한 대화 컨텍스트에서도 어느 정도 말이 되는 답변을 골라낼 수 있습니다.
다만 실제로 사람이 쓴 글을 그대로 사용한다는 방식이 가장 큰 단점이 될 수도 있습니다. 원 저자가 쓴 메시지가 토씨 하나 틀리지 않게 답변으로 선택되기 때문 입니다. 물론 "사랑해", "밥 먹었어?" 같이 많은 사람들이 공통적으로 썼던 언어라면 문제가 되지 않겠지만, 어느 사람의 특정할 수 있는 말투, 정보가 들어 있다면 개인정보가 유출되었다고 할 수 있습니다. 특히 데이터에 개인정보 비식별화 작업을 제대로 하지 못했을 경우 주소, 이름, 건강 정보 등 민감한 정보가 유출될 수 있습니다. 이번에 공개된 이루다는 이러한 점이 확인이 되어 논란이 되었지요.
이번 글에서는 자유 주제 대화 시스템, 챗봇의 원리에 대해서 정리해보았습니다. 제가 대학원에 있었을 때 이 주제의 연구를 해볼까 하려고 관련 논문도 많이 읽고, 트위터로 데이터도 모으고, 모델도 학습시켜보고 했었는데, 하면 할수록 정말 어려운 주제라는 것을 깨닫고 주제를 틀었었던 기억이 납니다. 어떠한 주제든 자연스러운 일상적인 대화를 할 수 있는 AI, 정말 신기하고 재밌는 주제/아이디어이지만 기술적인 것은 둘째 치고, 사회적으로 여러 고려할 상황이 많아 정말 까다롭습니다. 이번 이루다가 여러 논란을 남기고 중단되는 사태를 보면서 더더욱 그렇게 느꼈습니다.
다음 글에서는 이루다의 논란된 부분을 함께 짚어보고 이러한 것들을 보완하기 위해 어떤 연구들이 진행되고 있는지 알아보도록 하겠습니다. DB에서 답변을 고르는 모델이 아닌 생성 모델을 사용했으면 문제가 없었을까요? 성희롱, 혐오 발언은 이런 챗봇에서 어떻게 처리되어야 맞는 것일까요? 제가 정답을 가지고 있지는 않지만 함께 논의할 수 있는 글이 되었으면 좋겠습니다.
Reference
- Vinyals & Le, Neural Conversational Model, ICML Deep Learning Workshop, 2015
- Li et. al., 2016. A Persona-Based Neural Conversation Model, ACL 2016
- Li et al., 2017, Teaching Machine to Converse, PhD thesis
- Adiwardana et. al., 2020, Towards a Conversational Agent that Can Chat About…Anything , Google AI Blog
- Adiwardana et. al., 2020, Towards a Human-like Open-Domain Chatbot, 미나(Meena) 원 논문
- 김종윤 (스캐터랩), 오픈도메인 챗봇 ‘루다’ 육아일기: 탄생부터 클로즈베타까지의 기록, DEVIEW 2020
- 뉴닉, AI 챗봇 '이루다' 3가지 논란, 2021




