Week 48 - AI가 유튜브를 본다면?


인터넷이 처음 나왔을 때는 전부 텍스트로 정보가 왔다 갔다 했었습니다. 1990년대 후반에 태어난 분들만 해도 잘 모를 수 있지만, 인터넷이 전화 모뎀으로 연결되던 시절에는 그랬었죠. 속도가 기하급수적으로 개선되면서 사진을 공유하는게 일반화 되었고, 지금은 인스타그램, 유튜브, 틱톡 등 여러 플랫폼을 통해 동영상을 보는 것이 일상이 되었습니다.
사람은 원래부터 글로만 또는 말로만 얻는 정보보다 눈으로 보면서 정보를 익히는 방식에 익숙합니다. 그리고 끊임 없이 보이는 것에 대해 말이나 글로 텍스트를 생성하죠. 마치 스포츠 경기를 보면서 모든 상황을 해석해주는 해설자처럼, 유튜브 브이로그에 달리는 설명/자막처럼요.
그렇다면 NLP 모델은 어떨까요?
위클리 NLP에서는 쭉 텍스트 기반 모델에 대한 지식을 쌓아오다가, Week 40부터 Week 42까지는 텍스트와 이미지, 즉 멀티모달(multi-modal) 모델을 소개했습니다. 그리고 지난 Week 46과 Week 47에서는 관점을 줌아웃 하여 기초 모델(foundational modal)들의 장단점과 리스크를 다룬 논문을 리뷰하였습니다.
여기서 나온 핵심 결론 중에 하나는 "기초 모델이 멀티모달에 더 적합하게 진화해야 한다"였는데요. 다시 줌인을 해서 이를 위해 어떠한 연구들이 진행되고 있는지 살펴보려고 합니다.
이번 글에서는 텍스트-비주얼 이해(text-visual understanding)이라는 개념을 소개합니다. 텍스트와 비주얼 이미지를 함께 이해한다는 것이 무슨 뜻이고, 이를 위해 어떤 데이터를 어떻게 쌓고 있는지 다루어보겠습니다.

텍스트와 시각 정보를 함께 이해한다는 것은?
하나의 모델 또는 시스템이 텍스트와 시각 (이미지나 동영상)을 함께 이해한다는 것은 여러 가지 방식이 있을 수 있습니다만, 가장 기본이 되는 방식은 하나의 벡터 공간(vector space)에 텍스트와 시각 데이터를 함께 놓는 것입니다.
NLP 기초를 다룰 때, 단어 임베딩(word vector embedding)을 배웠습니다. 단어를 하나의 벡터로 표현하여 같은 공간에 들어가도록 학습하면 재밌는 속성을 가진다고 배웠죠.
기본 원리는 이와 같습니다. 텍스트-이미지 임베딩(text-visual vector embedding)을 학습시키는 것입니다. (*비디오는 클립 단위로 쪼개어 여러 이미지로 표현합니다)
그렇게 되면 어떤 속성을 가질까요?
- 데이터 포인트 간 유사도를 계산할 수 있다.
- 이를 이용해 비슷한 데이터 포인트를 찾을 수 있다.

근데 데이터가 텍스트 뿐만 아니라 이미지라면, 텍스트와 텍스트 뿐만 아니라, 텍스트와 이미지 간 유사도를 계산할 수 있다는 획기적인 장점이 있습니다.
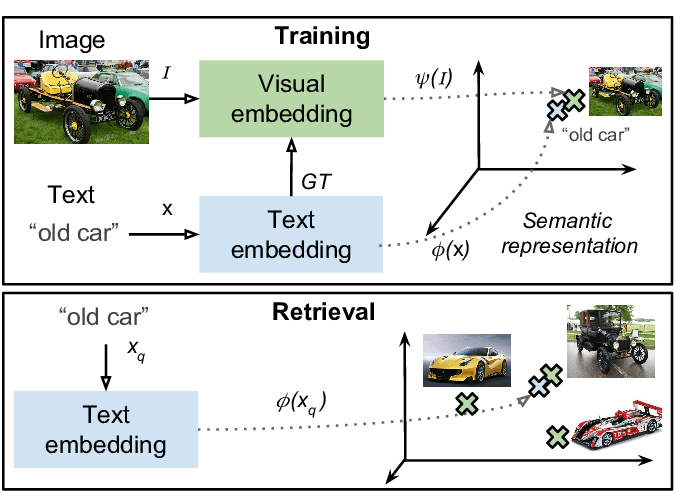
이러한 방식은 텍스트를 검색했을 때 알맞는 이미지를 찾아내는 Text Image Retrival 문제에 아주 적합한데요. 검색 엔진에서 원하는 이미지를 찾을 때, 글로 설명했는데도 이미지로 검색 결과가 나올 수 있는 원리이기도 합니다.
지난 Week 41에서 소개한 자연어 차량 검색 문제에서도 같은 방식을 채택하고 있습니다.
어떤 데이터 셋이 존재할까?
텍스트-이미지 임베딩을 학습하려면 그 두 가지 종류의 데이터가 함께 묶여있어야만 합니다.
어떤 모델이 쓰이는지 알아보는 것도 흥미롭겠지만, 저는 이번 글에서는 어떤 데이터 셋이 존재하고, 어떻게 구축되었는지에 집중하도록 하겠습니다.
모델은 나날이 새로운 테크닉이 나오며 발전하고 있기 때문에 새로운 것으로 교체될 확률이 높지만, 데이터 셋은 주로 벤치마크를 위해 계속 쓰이기도 하고, 어떤 문제에 응용될 수 있는지 감을 잡기 좋다고 생각합니다. 그리고 개인적으로 데이터 셋 구축을 하는 다양한 방식에 흥미가 있습니다. (저도 글을 쓰면서 앤드류 응 교수 님의 데이터 중심 AI 개발 철학에 큰 영향을 받았나 봅니다)
1. HowTo100M
첫번째 데이터 셋은 2019년에 공개된 HowTo100M입니다
요리, 가구 조립 등 생활 속에 필요한 지식이 너무나 많습니다. 유튜브가 없던 시절에는 설명서나 책을 통해 한단계 한단계 따라하며 배우는 경우가 많았지만, 요즘은 기업들도 제품 설명서에 유튜브 영상 링크를 첨부하는 경우가 많습니다. 그만큼 설명과 함께 비디오가 있으면 무엇이든 쉽게 따라 배울 수 있죠.
그래서 이 데이터 셋은 유튜브에서 "How to ~"로 시작하는 비디오를 모으는 것에서 출발합니다. 이러한 "설명 "형식을 가진 비디오는 여러 장점을 가집니다.
- 각 장면 간에 명확한 인과 관계가 있다 (ex. 라면 봉지를 뜯는다 => 면발을 끓인 물에 넣는다)
- 시작 상태와 끝 상태가 분명합니다 (ex. 라면 봉지 => 완성된 음식)
- 시각 정보와 텍스트 (음성 또는 자막) 정보의 연관성이 높다. (ex. "이제 스프를 넣고 3분 기다립니다.")
유튜브는 자막을 api를 통해 제공하기 때문에 비디오 뿐만 아니라 텍스트 데이터를 함께 모으기 용이합니다. 만일 콘텐츠 생산자가 자막을 업로드하지 않았더라도, 음성인식(ASR)을 통해 자동 생성 자막을 제공합니다. (물론 ASR으로 생성된 자막은 에러가 더 있겠지만요).
논문 저자들은 샘플된 데이터 검수를 통해 약 51%의 경우 텍스트에 언급된 동작이나 물체가 해당 타임스탬프의 비디오 클립에 등장한다고 밝혔습니다. 꽤 높은 연관성이라고 볼 수 있겠습니다. 나머지 49%는 보이는 것을 넘어서는 설명이거나 (ex. "야식으로 맛있는 음식이 무엇이 있을까요?", "냉장고에 파가 있으면 썰어 넣어주세요") 보이는 물체와 관련 없는 잡담 또는 설명이겠죠.

HowTo100M 데이터 셋으로 학습된 모델은 무척 재밌게 활용될 수 있습니다.
- 두 비디오 간 유사성 계산
- 하나의 비디오 안 다른 비디오의 클립(이미지 한장)과 유사한 장면 검색
- 텍스트로 비디오 장면 검색 (ex. "물 끓는 장면" 찾기)
- 두 비디오 클립 간 인과 관계 예측 (ex. 라면 봉지를 뜯는 장면 vs. 면이 끓는 장면 중 어떤 것이 먼저인지)
2. Speech2Action
두번째 데이터 셋은 영화 자막과 장면을 활용한 Speec2Action 데이터 셋입니다. 이 데이터 셋은 텍스트 설명보다는 사람의 액션과 비디오 장면을 매칭시키려고 한 점이 특징입니다. 특히 영화 자막을 아주 영리하게 이용한 점이 재밌어서 소개하려고 합니다.
먼저 논문에서는 영화 자막을 분석하여 재밌는 인사이트를 발견했습니다. 자막에 인물의 대사 외에도 동작을 설명하는 부분이 종종 등장한다는 점인데요. 특히 접근성(accessibility)을 높히기 위해 최근에는 자막에 인물들의 동작 또는 상황을 설명하는 부분이 많이 포함되고 있습니다.

이러한 동작 설명을 이용하여 비디오 장면의 인물의 동작에 대한 데이터를 구축하는 것은 어떨까요? 여기서 가장 큰 장벽은 모든 장면에서 동작 설명이 들어가지 않는다는 점입니다.
이를 해결하기 위해 먼저 동작 설명과 대사가 쌍을 이루는 텍스트 데이터를 모은 후, 동사 분석을 통해 약 18개의 대표적 액션으로 분류하였습니다. 여기서 동사 분석은 지난 Week 44에서 배운 POS 분석기를 이용합니다.

위 예시 데이터를 읽어 보시면 대사만 보아도, 장면에 주인공이 어떤 동작을 할지 예측이 될 수 있다는 것을 알 수 있습니다..
이것을 학습 데이터로 하여 BERT기반의 Speech2Action 모델을 만들었습니다. 즉, 어느 장면에 주인공의 대사가 주어졌을 때, 주인공이 어떤 동작을 함께 할 수 있는지 예측합니다. 물론 모든 대사와 어떤 동작과 연관되어 있지는 않을테니, 이런 경우는 미리 데이터에서 제외할 수 있도록 하였습니다.
그리고 여기서 더 나아가 약 22만 개의 영화 또는 드라마에 이 Speech2Action 모델을 적용하였습니다. 주인공의 대사가 나오는 시점을 중앙에 놓고, 10초 구간의 비디오 클립을 추출합니다.
이렇게 비디오 클립에 대사와 동작 종류의 두 가지 라벨을 자동으로 생성해 총 83만여 개의 비디오 클립을 라벨링하였습니다. 물론 자동 생성 라벨이기 때문에 정확도는 높지 않지만, 대량으로 데이터를 생성할 수 있었습니다. 논문을 살펴보면 "phone"이나 "run" 같은 동작은 올바른 비디오 클립에 라벨링된 경우가 많았지만 (precision 0.68 / 0.83), "kiss"나 "hit"은 그렇지 않았습니다 (precision 0.18)

조금은 부정확하더라도 기하급수적으로 많은 데이터에 학습된 모델의 성능은 어떨까요?
논문에서는 동작 분류 문제에서 이 데이터에 학습된 모델에 성능 향상에 기여하고 있음을 보여줍니다. 에러가 많더라도 데이터가 많기 때문에 딥러닝 모델이 일반화를 해낼 수 있는 것이죠.
이렇게 조금은 부정확하더라도 자동으로 생성되는 라벨 데이터를 Weakly supervised label이라고 합니다.
3. 구글의 Conceptual Captions 데이터 셋
구글에서 공개한 데이터 셋으로 인터넷 상에 있는 이미지 중 대체 텍스트(alt-text)가 있는 쌍만 추린 후 가공하였습니다. Alt-text는 주로 이미지가 로딩되지 않을 때 이미지 대신 보여주기 위해 HTML에 입력되는 텍스트인데, 항상 정확하지는 않지만 자동으로 대량의 데이터를 모으는 것이 가능합니다.
데이터 셋을 처음 공개한 원 논문에서는 구글의 지식 그래프(Knowledge Graph)와 클라우드 NLP API 등을 이용하여 원래 텍스트를 좀 더 간결하고 일반적인 단어들로 재가공하는 식으로 약 3백 만개의 이미지 - 텍스트 쌍 데이터를 모았습니다.


그런데 이 데이터 셋의 문제는 이렇게 재가공하는 것은 꽤나 오래 걸리고 비싼 작업입니다. 실제로 이 데이터 셋은 Apache Flume이라는 빅 데이터 처리 플랫폼을 이용하여 방대한 양의 재가공처리를 하였습니다 (구글에서 아주 널리 쓰이는 데이터 툴인데, 다음에 더 자세히 다뤄보겠습니다!).
최근에 공개된 구글의 후속 논문에서는 이러한 한계점을 극복하기 위해, 재가공 작업을 다 생략하고 심플하게 중복만 제거한 데이터를 사용하였습니다. 이렇게 필터링 작업을 많이 거치지 않으면 더 소음이 많을 수 밖에 없지만, "1백만" 단위가 아니라 "10억" 단위의 스케일의 데이터 셋이 쉽게 구축이 가능합니다. 이 역시 Weakly supervised label을 가진 데이터 셋이라고 할 수 있겠습니다.
그리고 CNN과 BERT를 기반으로 한 dual encoder 구조의 아주 큰 모델을 사용하여 pretraining을 하였더니 놀라운 결과가 나왔습니다. 이를 기반으로 한 텍스트-이미지 임베딩을 이용했을 시, 이미지/텍스트를 함께 이해해야하는 여러 문제 대부분의 최고 성능 기록을 깨버렸습니다. (그 전 최고 기록은 Week 42에 소개한 CLIP 이 가진 것이 많았습니다)
거대 딥러닝 모델에는 조금 라벨이 부정확하더라도 그에 걸맞는 스케일의 데이터 셋으로 미리 학습하는 것이 효과적이라는 것을 다시 한번 보여주는 연구인 것 같습니다.

오늘 소개한 데이터 셋들의 공통점은 무엇일까요?
- 이미지(또는 비디오 클립)를 연관된 텍스트와 함께 놓는다.
- 텍스트 라벨을 사람 손이 아니라 자동으로 획득한다 (weakly supervised label).
- 그렇기 때문에 항상 라벨이 정확하지는 않다.
- 그래도 이렇게 해야만 스케일 있는 데이터 구축이 가능하다.
이렇게 구축된 데이터 셋으로 텍스트-이미지 임베딩 모델을 학습시키고, 그 이후에 필요한 텍스트 비주얼 문제에 응용합니다.
오늘은 텍스트-비주얼 이해(text-visual understanding)에 대해 알아보았습니다. 저도 배우면서 글을 쓰고 있어 부족한 점이 있을 수 있으니 피드백이 있다면 꼭 메일이나 댓글로 남겨주시면 감사하겠습니다!

REFERENCE
- Miech et al., 2019, HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips, ICCV 2019
- Nagrani et al., 2020, Speech2Action: Cross-modal Supervision for Action Recognition, CVPR 2020
- Sharama et al., 2018, Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text DatasetFor Automatic Image Captioning, ACL 2018
- Jia et al., 2021, Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision, ICML 2021



