


2022년 6월, 요즘 트위터에 들어가면 이상한 이미지들이 수십 개씩 피드에 등장하고 있습니다. 말도 안되는데 그럴 듯한 이미지들의 정체는 무엇일까요?
이들은 최근에 공개된 Text-to-Image 모델들의 결과물입니다. 작년 Week 40: 내가 말하는 걸 보여줘, DALL-E에서 텍스트가 주어졌을 때 이에 맞는 이미지를 생성하는 DALL-E를 소개했었죠. 그 때도 획기적인 결과물로 모두를 놀래켰는데 1년정도 지난 지금, 훨씬 더 발전된 모델들이 나왔습니다.
바로 OpenAI의 DALL-E:2 그리고 Google의 Imagen과 Parti입니다.
이제는 “말하는 것을 보여줘”가 아니라 “상상하는 것을 보여줘"라고 할 정도로 비현실적인 상황을 묘사한 글로만으로도 꽤나 정교한 이미지로 생성되는 것을 볼 수 있는데요. 과연 어떤 발전이 있었는지, 세 모델의 차이점은 무엇인지, 한계점은 무엇인지 정리해보겠습니다.
잠깐! 일단 글을 읽을까 말까 고민하기 전에 이 모델들이 어떠한 이미지를 생성할 수 있는지 보고 오시길 바랍니다! 정말 엄청납니다..
 OpenAI
OpenAI



*이 글은 공개된 연구 논문을 바탕으로 작성되었으며, 소속된 회사의 입장이 아닌 개인의 의견임을 미리 밝힙니다.
모델 구조
자, 생성된 이미지들을 보고 오셨다면 도대체 얘네는 어떻게 만들어진 것인지 궁금할 것이라고 생각합니다.
디테일로 들어가기 전에 한번 큰 개념부터 생각해봅시다.
글을 이미지로 변환하는 Text-to-Image. 잘 생각해보면 이것 역시 일종의 번역(translation)이라고 볼 수 있습니다. 우리의 말 또는 글을 보이는 이미지로 바꿔주는 거니깐요. 마치 영어를 한국어로 변환시켜주는 번역기처럼요.
음성 인식 기술 역시 개념적으로는 똑같습니다. 우리가 들을 수 있는 사람 목소리의 음파를 읽을 수 있는 글로 바꾸는 것.
Text-to-Image도 데이터의 형태가 다를 뿐 결국 같은 문제라는 것을 알 수 있습니다.
<위클리 NLP>를 열심히 읽으신 독자분들은 이미 이러한 번역, 변환에 효과적인 모델 구조이 무엇인지 알고 계실 것이라 생각합니다. 바로 Encoder-Decoder, 그리고 이 구조에 월등한 성능을 보여주는 트랜스포머(transformer) 모델입니다.
DALL-E:1 과 Parti에 쓰이는 트랜스포머 Encoder-Decoder
Week 40에서 소개한 DALL-E는 GPT-3와 비슷한 구조로 트랜스포머 Encoder-Decoder를 학습시켜 Text-to-Image 모델을 만들었습니다.
Parti 역시 거의 같은 구조를 가지고 있습니다.
Parti는:
1. 더 큰 스케일의 모델과 데이터로 학습,
2. Vit-VQGAN이라는 발전된 방식으로 이미지 데이터를 압축하여 표현
했다는 차이가 있습니다.
특히 구글이 지난번에 발표한 언어 모델 PaLM (Week 54)와 같은 parallel computing 방식으로 200억(20B) 파라미터를 가진 거대 모델을 학습시켰다고 합니다.
DALL-E:2
OpenAI의 DALL-E:2는 DALL-E의 후속작이지만 전혀 다른 구조를 가지고 있습니다.
DALL-E:2는 텍스트와 이미지가 같은 CLIP (Week 42)의 벡터 임베딩 공간(joint representation space)를 활용합니다.
CLIP은 어떤 텍스트(ex. “불 뿜는 트럼펫을 든 강아지”)와 어떤 이미지가 유사할수록 벡터 공간(Week 3)에서 가깝도록 학습되었습니다.
CLIP을 이용하여 텍스트가 주어졌을 때, 이에 대응되는 이미지 벡터를 생성합니다. 그리고 이 이미지 벡터를 이를 Diffusion Model이라는 이미지 생성 모델에 집어넣습니다.
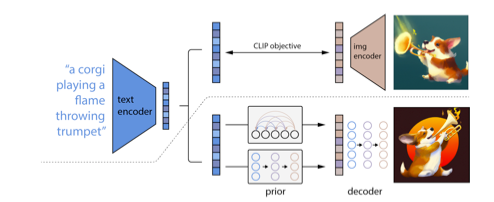
Diffusion 모델은 벡터를 통해 이미지를 생성하는데 굉장히 뛰어난 성능을 보여줍니다! (저는 가운데 "미친 팬더 과학자가 가장 마음에 듭니다!)

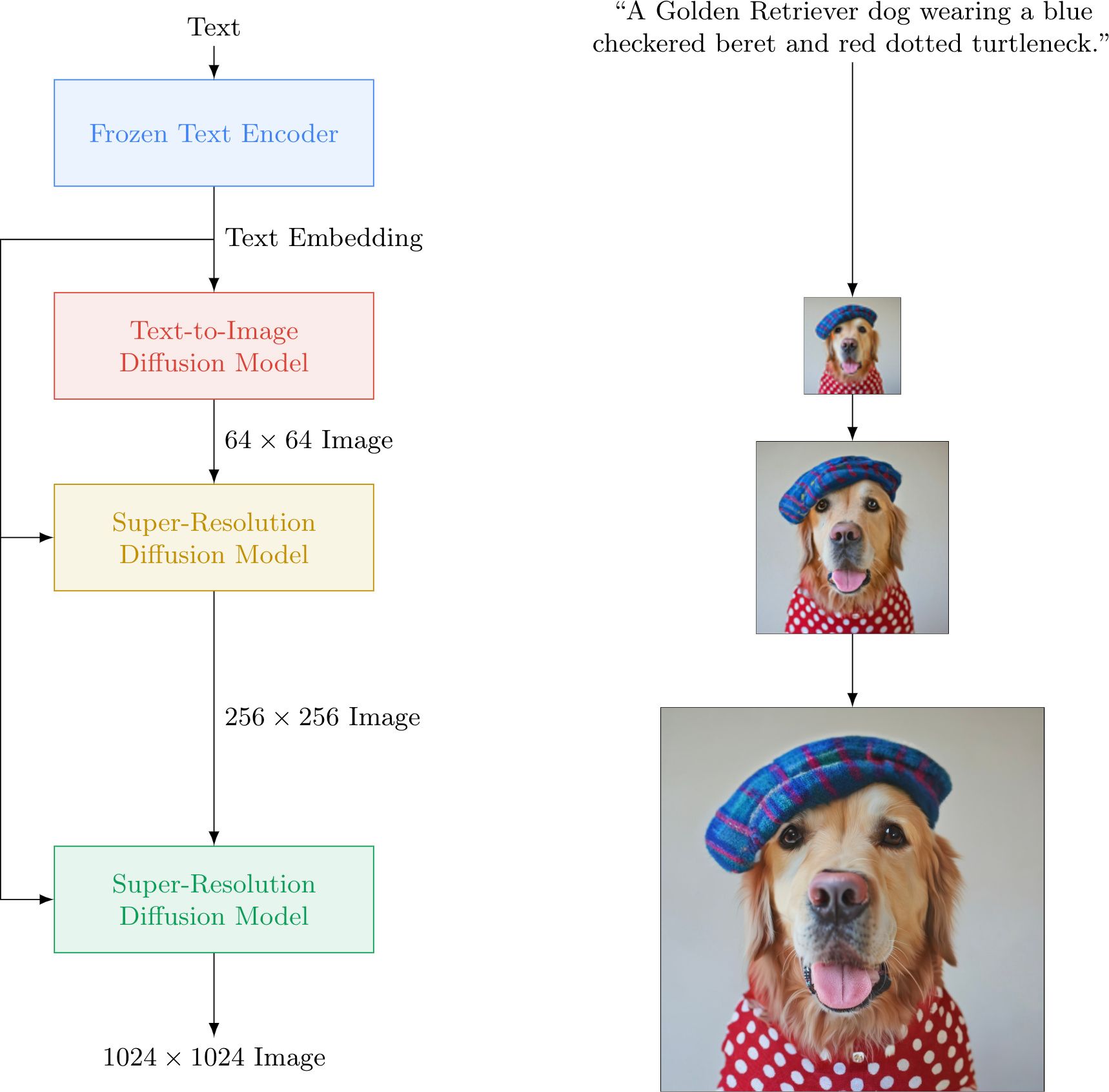
Imagen의 구조
Imagen은 트랜스포머 기반 텍스트 encoder, diffusion 모델, 그리고 super-resolution 모델을 사용합니다. DALL-E:2와 Parti을 섞어놓은 느낌이죠.
특히 미리 학습된 T5 언어모델 (간단히 말해 구글 버전의 GPT)를 이용해 텍스트 임베딩을 구한 후, 이를 Diffusion 모델로 이미지를 만들어냅니다.
여기서 생성된 이미지는 작은 편(64x64)인데, 이를 고해상도로 높이기 위해 Super-resolution Diffusion이라는 기술을 사용해 256x256, 1024x1024로 만들어줍니다.
Diffusion 모델이 도대체 뭔데?
생성 모델(Generative Model)은 어떤 데이터가 주어졌을 때, 이의 통계학적 분포를 모델링하는 것을 뜻합니다.
반대로 어떤 데이터가 주어졌을 때 각 클라스 (ex. 부정 vs. 긍정; 강아지 vs. 고양이 등)를 통해 통계학적 분포를 모델링하는 것은 분류 모델(Discriminative Model)이라고 하죠.
생성 모델의 장점은 이미지나 텍스트 같은 복잡한 세상 데이터를 조금 더 간단한 고차원 벡터 공간에 모델링할 수 있다는 것입니다. 특히 딥러닝 모델이 나오면서 훨씬 더 고차원적, 그리고 방대한 양의 학습 데이터로 다채로운 표현을 학습할 수 있게 되었습니다. 그렇기 때문에 학습데이터에 전혀 등장하지 않는 이미지, 예를 들어, 하와이안 티셔츠를 입고 있는 웜뱃 같은 상상력 풍부한 이미지도 생성해낼 수 있는 것입니다.
Diffusion Model은 최근 생성 모델 중 가장 효과적이라고 각광받는 기법입니다 Autoencoder와 비슷한 원리로 원래 데이터를 복원시키는 방식으로 학습되는데, 더 디테일로 들어가기에는 저의 수학적 지식에 한계가 있기도 하고, 위클리 NLP의 포커스에 맞지 않는 것 같아 관심있으신 분들을 위해 한국어로 된 자료를 첨부합니다.
[참고 자료]
1. Diffusion을 여행하는 히치하이커를 위한 안내서: 유튜브 영상
2. SI Analytics 블로그
생성된 이미지의 퀄리티는?
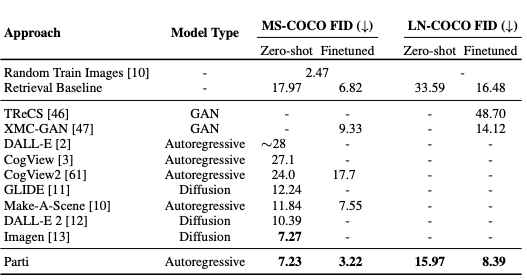
“이 세 모델 중에 어떤게 더 좋은가요?”라는 질문에 논문에서는 크게 두 가지 평가 방법을 제시합니다. 자동으로 계산할 수 있는 FID와, 여러 사람이 평가하는 설문 방식입니다.
먼저 언급되는 측정 점수 Fréchet inception distance(FID)는 Inception V3라는 미리 학습된 CNN 모델을 공통으로 이용해, 새롭게 생성된 이미지들과 원본 이미지들의 분포 차이값을 계산합니다. 예를 들어, MS-COCO라는 벤치마크 데이터 셋에서 텍스트 캡션을 DALL-E, Imagen, Parti에게 각각 입력하여 이미지를 생성하고, 데이터 셋의 원본 이미지들과 얼마나 비슷한지 계산하는 것 입니다.
그리고 여기서 더 나아가 사람들에게 생성된 이미지를 비교(Human Evaluation)하게 하였습니다. 두 개의 모델이 생성한 이미지 두 장을 옆에 놓고 설문조사를 합니다.
측정한 요소는 Imagen 논문에 자세히 나오는데:
1. 이미지 퀄리티: “어떤 이미지가 더 사실적인가?”
2. 텍스트 연관성: “주어진 텍스트 캡션을 정확히 묘사하는가?”
추가로 DALL-E:2 논문에서는:
3. 다양성: “한 텍스트에서 여러 이미지를 생성했을 때, 다양하게 이미지가 생성되었는가?”
그 외..
논문을 읽으면서 흥미롭다고 느꼈던 점을 공유하자면:
- 스케일: 모델의 크기가 커질수록 더 현실적이고 다양성도 높은 퀄리티 이미지가 생성된다 (이제는 너무 당연한 소리긴 하지만, 결국 돈이 많아야 된다는 소리입니다). 기존에 학습된 pretrained 모델(ex. T5, CLIP)을 잘 활용할 수 있다.
- 한계: 사물 간의 현실적 크기를 모른다거나 (ex. 비행기만한 고양이), 숫자를 반영하지 못하거나, (ex. 3마리 고양이), 반어 반영 (ex. 고양이가 없는 사진), 텍스트 렌더링 (ex. “고양이”라고 한글로 써있는 간판), 동음이의어 (ex. “Star” => 연예인? 별?)에 어려움을 겪는다.
- 체리피킹: 언어모델, 기계번역, 그리고 이미지 생성 같은 생성 문제는 체리피킹(cherry-picking)에 대한 비판을 받고는 합니다. 실제로 모델 데모를 통해 생성을 해보면 10개 샘플 중에 1,2개 밖에 건질만한게 없다고 하죠. 잘 된 것만을 골라서 논문에 예시로 보여주는 것을 체리피킹이라고 합니다. Parti 논문에서는 이를 의식하여 아예 점진적으로 텍스트를 추가하여 어떻게 좋은 샘플을 얻을 수 있는지 섹션을 만들어 설명합니다. “Growing a cherry tree”라고.. Google Brain의 연구자 David Ha는 창의적인 도구로 활용될 때는 허용되어야 한다고 주장합니다.
Tried to use #Imagen to generate collectable Japanese postage stamps about VR cats. I love these results!
— hardmaru (@hardmaru) June 13, 2022
“Ukiyo-e painting of a cat hacker wearing VR headsets, on a postage stamp” ❤️ pic.twitter.com/4NpXAy5cVD
세 논문을 정리하면서 이미지 쪽의 새로운 개념도 많이 공부하고, 이미지 샘플을 보면서 데이터와 모델의 스케일에 엄청남을 느꼈습니다. 특히 1-2년 만에 이렇게 발전한 하나의 분야를 보고 한편으로는 흥분되면서도, 다른 한편에서는 발전 속도에 무서움을 느꼈습니다.
과연 Text-to-Image은 어떤 곳에 응용될 수 있을까요? 가장 당연한 사례는 미술(art)입니다. 연구자들도 이를 염두에 두고 여러 가지 미술적 요소를 논문에 가미하였습니다. 이제는 붓이 아닌 AI 모델로 미술 작품을 만드는 시대가 온 것일까요.
논문에서 언급된 것 중 흥미롭다고 느낀 것은 일상 소통에서의 활용입니다. 어떠한 이유로 말이나 텍스트로 소통하기 힘들 때, 아니면 비주얼로 소통하는게 더 효과적일 때 이러한 모델을 사용하는 것은 어떨까요? 해외 여행 시 번역기가 아니라 내가 원하는 것을 이미지로 생성해 보여주면 더 효과적이지 않을까요?
혹시 여러분이 생각하는 다른 응용 사례가 있다면 댓글로 남겨주시길 바랍니다!

Reference
- [DALL-E:2] Ramesh et al. 2022, Hierarchical Text-Conditional Image Generation with CLIP Latents
- [Imagen] Saharia et al., 2022, Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
- [Parti] Yu et al. 2022, Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
- OpenAI Blog: DALL-E:2
- Google Research: Imagen
- Google Research: Parti