Google I/O 2022 NLP 중심 리뷰


매년 열리는 구글의 기술 뽐내기 장터, Google I/O가 올해는 드디어 Shoreline Amphitheater에서 5월 10일 관중들과 함께 치루어졌습니다.
저도 입사 이후 무려 2년 반만에 처음으로 해외 출장이 풀리게 되어 5월에 마운틴 뷰 본사에 가볼 기회가 있었는데요. 아쉽게도 I/O 기간과는 겹치지 않아 라이브로 보지는 못했지만, 작년과 마찬가지로 NLP 위주의 리뷰를 해보려고 합니다.
이번 I/O를 보면서 느낀 점은 거의 절반 이상의 내용이 NLP에 관련되어 있다는 것이었습니다. 그냥 리뷰를 써도 NLP 위주가 될 수 밖에 없겠더군요.
구글의 주력 제품이 Search(검색)이기 때문에 더더욱 그렇지만, 이번 I/O에서는 구글 번역(Translate), 구글 챗 및 독스를 아우르는 워크스페이스(Workspace), 안드로이드(Android), 그리고 제가 일하는 구글 어시스턴트(Assistant) 등 여러 제품에서 NLP가 적용된 사례를 발표하였습니다.
커버할 내용이 많은데요. 이번 I/O의 키워드를 뽑자면:
Multi-lingual (다국어)
Multi-modal (다중 인풋)
입니다.
Multi-lingual(다국어)는 하나의 시스템이 여러 언어를 다룰 수 있다는 것입니다. 가장 대표적인 구글 번역기가 있죠. 더 중요한 것은 하나의 NLP 모델이 여러 언어를 이해할 수 있냐는 것인데요. 특히 구글처럼 제한된 인력으로 세상의 모든 언어로 된 정보를 모아 정리하려는 목표를 가진 회사로써는 다국어 NLP 모델이 굉장히 중요합니다.
Multi-modal (다중 인풋)은 여러 개의 형태의 데이터를 한번에 다룰 수 있는 머신러닝 모델/시스템을 뜻합니다. 지금까지의 구글 검색은 텍스트 위주였다면, 사진, 음성, 비디오 등 여러 형태의 데이터를 조합하여 원하는 정보를 찾아주는 방식으로 진화하고 있습니다.
많은 내용이 있지만 시간 순서대로 다루어보도록 하겠습니다.
*이 글은 구글 I/O에서 공개된 내용을 바탕으로 작성되었으며, 소속된 회사의 입장이 아닌 개인의 의견임을 미리 밝힙니다.

번역 (Translate)
구글 번역은 우리의 해외 여행에 도움을 줄 뿐만 아니라, 여러 사람들의 생활에도 중요한 역할을 할 수 있습니다. 특히 전쟁 때문에 폴란드로 피난을 간 우크라이나인들에게는 구글 번역기가 중요한 역할을 하고 있다고 합니다.
다만 세상에는 상당히 많은 언어가 있기에, 소수의 사람들만 쓰는 언어는 데이터가 부족할 수 밖에 없습니다. 소수 언어를 쓰는 사람들에게는 번역은 단순히 불편함 해소용이 아니라 생계와 안전에 직결되는 경우가 더 많음에도 불구하고 말이죠.
Week 20에서 공부했듯이, 기계 번역 모델을 학습하려면 Parallel corpora, 즉 번역하려는 양 쪽 언어의 데이터가 쌍으로 필요합니다. 하지만 데이터가 부족한 언어들은 영어와의 쌍조차 부족합니다. 예를 들어, 한국어와 우크라이나어를 직접 번역한 데이터는 얼마나 모으기 어려울까요.
이를 해결하기 위해 기계 번역 연구자들은 monolingual learning이라는 새로운 번역 모델 학습 방식을 연구해왔습니다. Parallel corpora가 없거나 적더라도, 하나의 언어(monolingual) 데이터로도 번역을 가능케 하는 방식인데요.
구글에서는 이 방식을 통해 24개의 새 소수 언어를 번역에 새로 지원하기로 발표하였습니다.
(일종의 비지도 학습(unsupervised learning)을 사용하고 있는데, 나중에 기회가 된다면 깊게 다루어보도록 하겠습니다.)
유튜브 (Youtube)
세계에서 두번째로 큰 검색엔진인 유튜브 역시 엄청나게 방대한 데이터가 처리되는 시스템입니다. 비디오, 텍스트, 음성이 다 함께 존재하는 Multi-modal 데이터가 가장 많은 곳 중 하나일 것 같습니다.
다만 비디오라는 포맷은 원하는 정보를 빠르게 얻기에는 쉽지 않습니다. 비디오를 전부 봐야하는 경우가 많죠. 이를 타파하기 위해 유투브에서는 크리에이터가 직접 비디오를 챕터로 나누어 보여줄 수 있는 기능을 선보였습니다.
그리고 이번에 공개한 기능은 AI 시스템이 자동으로 챕터를 생성하는 기술입니다. 비디오의 내용을 분석하여 챕터로 나누어주고, 크리에이터가 이를 검수 및 수정할 수 있도록 하여 챕터에 관한 편집 시간을 획기적으로 줄였습니다.

이는 정말 쉽지 않은 AI 기술입니다. 비디오, 텍스트, 음성을 함께 분석하여 내용을 이해해 정리해야 하기 때문이죠. 그렇기 때문에 구글의 가장 뛰어난 AI 연구 팀인 딥마인드(DeepMind)이 투입되어 이 기능에 쓰이는 모델을 개발했다고 합니다.

워크스페이스 (Workspace)
TL;DR이 무슨 뜻인지 알고 계신가요? 바로 "Too Long; Didn’t Read"의 약자인데요. 너무 기니까 요약 좀 해달라는 이야기입니다. 요즘은 TL;DR을 아예 문서 위에 요약 또는 개요의 의미로 쓰고 있습니다.
회사 일을 하다보면 요약이 필요한 경우가 굉장히 많죠. 특히 코로나 덕에 많아진 재택근무 때문에 우리는 문서, 채팅, 이메일 등 더 많은 정보에 허덕이고 있습니다. 그래서 구글 독스(google docs), 챗(chat), 밋(meet), 지메일(gmail)을 아우르는 제품인 워크스페이스 팀에서 좀 더 유저들의 일을 편안하게 하기 위해 NLP를 활용하기 시작했습니다.
바로 자동 요약(text summarization) 기능입니다!
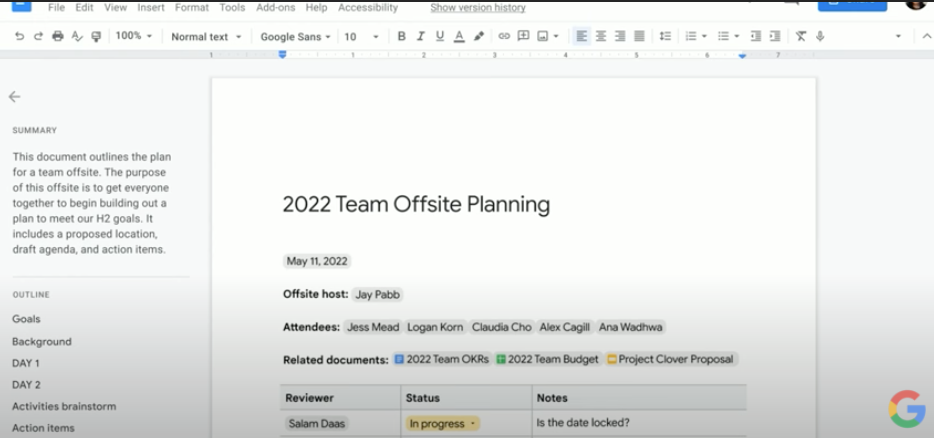
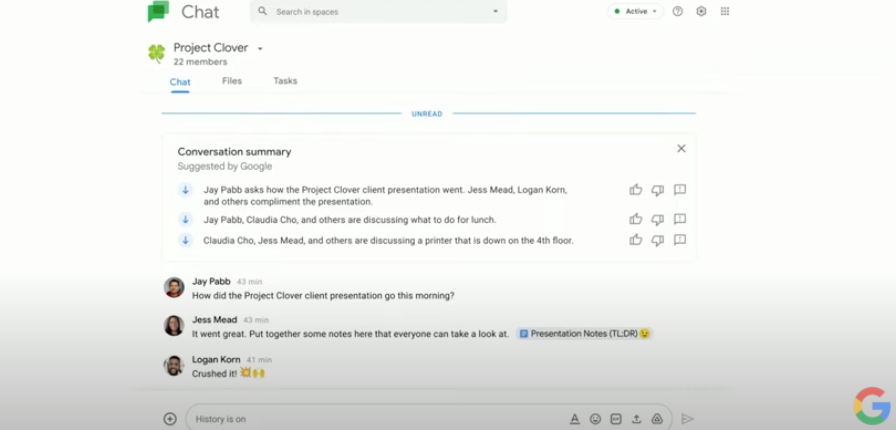
정말 많은 사람들의 시간을 절약해줄 기능이네요. 이참에 구글 워크스페이스를 사용해보는건 어떨까요? (광고 아닌 추천?! 저는 매일 쓰고 있는데 만족도가 높습니다.)
검색 (Search)
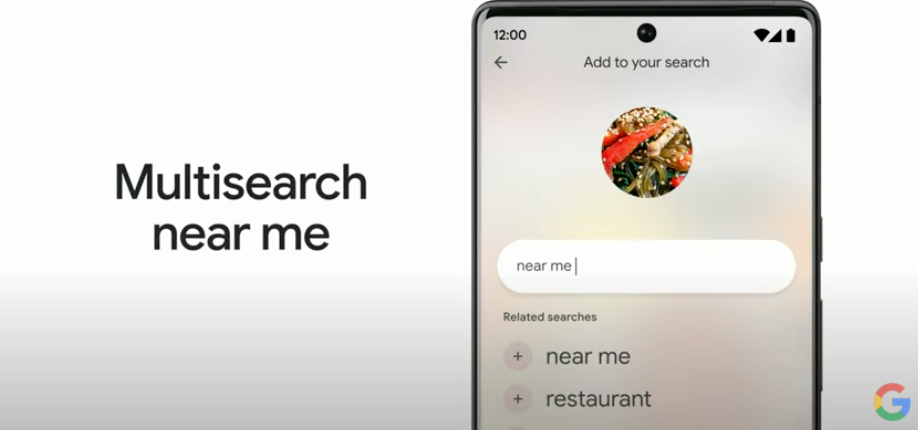
구글 Search의 수장인 Prabhakar가 발표한 부분의 키워드는 “multisearch”이었습니다. 지난 해 발표한 MUM을 본격적으로 검색 기능으로 넣기 시작했는데요. 텍스트와 이미지를 함께 검색하는 방식의 진화된 구글 검색을 보여주었습니다.

그리고 더 나아가 위치 정보까지 조합할 수 있는데요. 공교롭게도 예시는 “잡채"였습니다. Prabhakar가 “인터넷에 있는 이 음식 맛있어 보이는데 뭘까"하고 사진을 검색하여 한국 음식인 잡채라는 것을 확인한 후, “near me”라는 추가 검색어를 넣으니 주변에 잡채를 파는 한국 음식점까지 찾을 수 있었습니다.
이미지와 텍스트로 정보를 찾는 진화된 검색엔진과 맵스(maps)라는 또다른 강력한 위치기반 검색엔진까지 이어지는 훌륭한 예시라고 생각합니다.
어시스턴트 (Assistant)
그 다음은 제가 일하고 있는 어시스턴트의 차례였습니다. 어시스턴트의 새로운 수장 Sissie Hsiao가 직접 데모를 하였는데요. 이번 데모의 중점은 “어떻게 하면 좀 더 자연스러운 대화를 할 수 있을까?”였는데요. 특히 대화가 시작되는 첫 트리거(trigger)에 대한 기능이 발표되었습니다.
어떤 스마트 스피커든 대화를 시작하려면 “OK 구글", “하이 알렉사", “헤이 빅스비", “헤이 클로바" 등 스피커를 부르는 것으로 시작하는데요. 이를 “hotword” 또는 “wakeup word”라고 합니다. 다만 항상 이러한 hotword로 시작해야 한다는 것이 굉장히 불편한 UX를 초래하기도 합니다. 특히 인식율이 좋지 않다면요.
사람 간의 대화에서는 이름을 부르는 것으로 시작하기도 하지만, 그냥 쳐다보거나 손짓 등으로 대화가 시작되기도 하죠.
이처럼 구글 어시스턴트도 그저 쳐다보는 것으로도 대화를 할 수 있게 기능이 추가되었습니다.

두번째는 Quick Phrases라는 기능입니다. 자주 사용하는 명령을 hotword 없이 바로 사용할 수 있게 하는 것입니다. “침실 불 켜줘", “오늘 날씨 뭐야" 같이 자주 쓰는 명령을 미리 등록할 수 있게 되었습니다.

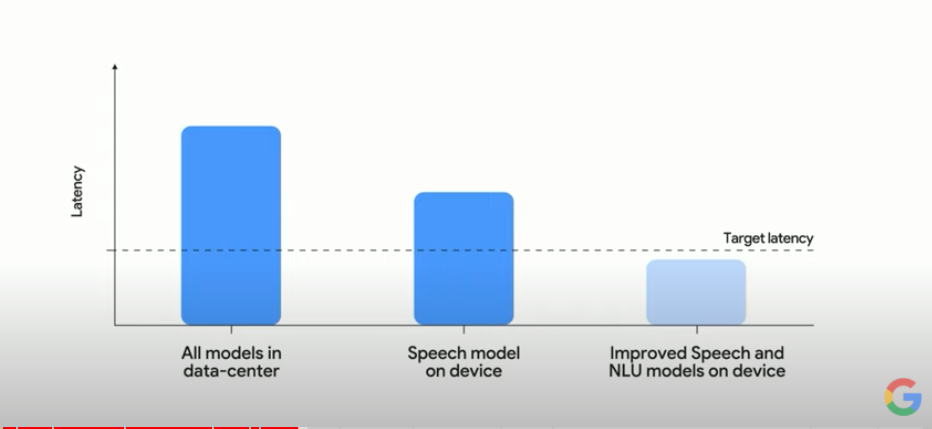
어시스턴트가 부자연스럽게 느껴지는 이유 중 두 개는 1) 반응 속도가 느리다, 2) 중간에 말을 더듬거나 생각하거나 잠시 멈추면 말을 끊는다, 가 있습니다.
반응 속도가 느린 이유는 음성인식과 언어이해가 전부 클라우드에서 진행되기 때문인데요. 그렇기 때문에 집의 인터넷 상황에 따라 어시스턴트와의 대화는 무척 다른 경험이 될 수도 있습니다.
이를 해결하기 위해 어시스턴트는 많은 부분을 클라우드가 아닌 on-device, 즉 하드웨어에서 처리할 수 있도록 하려고 합니다. 특히 이번에 출시된 Pixel 6에 텐서 칩이 들어간 것 처럼 앞으로는 하드웨어에도 ML 관련 성능이 크게 향상될 것으로 보고 있는 것 같습니다.
마지막 데모로는, 음악을 고를 때 잠시 말을 끄는 경우를 보여주었습니다. 현재의 어시스턴트는 “그 뭐지 음악(Play the new song from…" 이러면 말을 끊어버리는데, 앞으로의 어시스턴트는 유저가 말을 끝낼 때까지 기다리고 듣고 있다는 신호까지 주는 방식으로 진화될 것을 보여주었습니다.
이 역시 인간은 쉽게 하지만, AI가 하기에는 상당히 어려운 기술인데요. 텍스트를 음성과 함께 이해해 말을 끝냈는지 안했는지 결정해야 하기 때문입니다.
이에 대한 데모는 비디오를 직접 보시는 걸 추천합니다 (5:20부터).
언어모델: LaMDA & PaLM
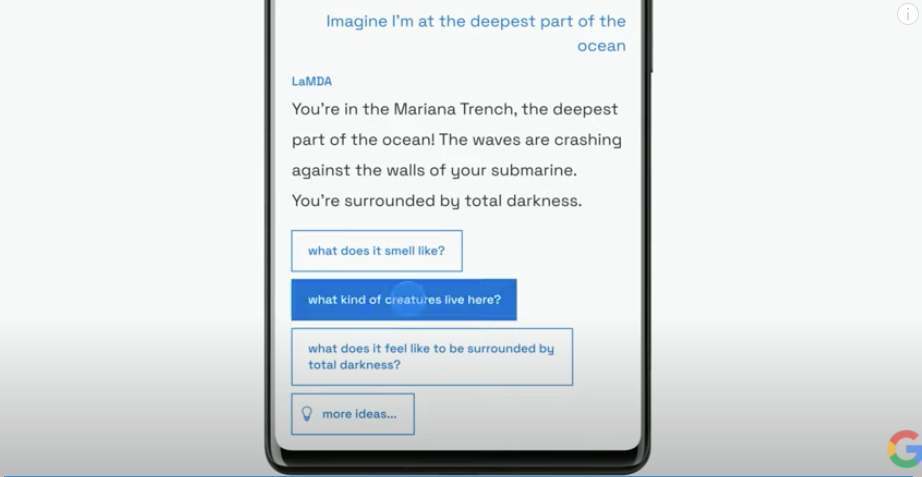
작년 발표된 엄청난 최강 챗봇인 LaMDA는 AI Test Kitchen이라는 재밌는 어플에 담겨 돌아왔습니다. AI와 함께 아이디어를 개발하는 방식(Imagine), 하나의 토픽에 대해 계속 대화를 하는 방식(Talk), 그리고 어떤 일을 하기 위해 할일 목록을 정리할 때 AI와 함께 계획하는 방식(List), 총 3 가지 기능을 선보였습니다.
그리고 마지막으로는 올해 초 발표된 거대 언어 모델 PaLM를 소개하였습니다. 지난 Week 54에서 다룬 내용에서 새로운 내용은 없었으니 전 포스트를 참고하시길 바랍니다.
이렇게 LaMDA와 PaLM 같은 거대 언어 모델을 I/O에서 직접 CEO가 발표하는 것을 보면 NLP 언어 모델이 구글의 핵심 기술로 자리 잡은 것 같습니다.
증강현실 (Augmented Reality)
안드로이드(Android)의 여러 발표와 함께 또다른 화두는 증강현실(AR; Augmented Reality)였는데요. 우리가 현재 살아가는 오프라인 세상과 주로 온라인에 존재하는 여러 AI기술을 어떻게 연결할 것인지에 대한 고민이 담겨있었습니다.
첫번째로는 WearOS와 새로 발표된 Pixel Watch였는데요. 구글 어시스턴트를 사용하여 좀 더 빠르고 간편하게 여러 정보에 접근할 수 있다는 장점을 보여주었습니다.

두번째는 스마트폰 카메라를 통해 눈 앞에 존재하는 것들에 대한 다양한 정보를 빠르게 탐색하는 방식이었는데요. 예시로 보여준 것은 슈퍼마켓에서 진열된 수십 가지의 초콜렛 중에 어떤 것을 골라야 할지 모를 때의 상황이었습니다. 구글 렌즈(Google Lens) 앱을 통해 하나하나 검색해야 하는 정보를 한순간에 보여주는 AR 기능을 보여주었습니다.

세번째는 안경(Google Glass의 부활?)에 적용된 경우입니다. 설명하는 것보다 비디오를 보는 것이 더 빠를 거 같습니다.
이처럼 구글의 미래는 온라인 뿐만 아니라 AR을 통해 오프라인의 접점을 늘릴려고 한다는 것을 알 수 있습니다.
정말 그 어느 때보다 알찬 Google I/O였다고 생각합니다. 여러분이 생각하기에 가장 인상 깊었던 부분이 무엇인지, 혹시 제가 놓친 포인트가 있었는지 있다면 댓글로 알려주시길 바랍니다!



