ChatGPT에 화들짝 놀라신 분 들어오세요 - 원리 편


ChatGPT launched on wednesday. today it crossed 1 million users!
— Sam Altman (@sama) December 5, 2022
ChatGPT가 공개된지 5일 만에 백만 유저가 가입했다고 합니다. 2020년 GPT3가 공개 되었을때 이상으로 화제를 불러일으키고 있습니다. 여태까지 공개된 언어 모델은 사람이 쓰는 글과 비슷하여 대단하다고 느꼈던 반면, 이번 버전은 인간 이상의 작문 능력과 창의력을 보여주기에 더 놀라움을 줍니다.
ChatGPT explains HTML like we’re@a dog: pic.twitter.com/iSkhVZJRdX
— ChatGPT (@ChatGPTGoneWild) January 8, 2023

방대한 양의 데이터에서 영화의 시나리오에 대한 정보를 가지고 있는 것은 그렇다고 쳐도, 주인공이 실패하는 경우를 상상해달라고 했을 때 세상에 없는 스토리를 조합하여 써낼 수 있다는 것이 정말 신기합니다.
세상을 놀라게 하는 ChatGPT는 어떤 원리로 작동하는 것일까요?

ChatGPT는 거대한 언어모델이다

ChatGPT의 기본은 언어 모델입니다. 여태까지 주어진 단어들을 주었을 때, 다음 단어를 예측하는 모델이죠. 정말 방대한 양의 데이터를 학습하고, 정말 큰 트랜스포머 모델을 사용합니다. 한 단어 한 단어를 예측하면서 대화를 생성해나갑니다.
하지만 이번에 발표된 ChatGPT는 단순히 스케일을 넘어, 추가적인 데이터 수집을 통해 더 강력해졌습니다.
OpenAI의 빌드업
거대한 AI 연구소와 같은 OpenAI는 빠르지만 착실하게 한걸음씩 핵심 AI 제품을 성장시켰습니다. 먼저 GPT를 1에서 3까지 데이터와 모델 사이즈를 증가하며 발전시켰습니다. 스케일을 올리면 성능이 증가한다는 것을 보여주었죠.
그리고 좀 더 인간의 명령을 잘 이해하고 따를 수 있도록 학습한 InstructGPT를 발표하였습니다. Week 53에서도 보았듯이 강화 학습(Reinforcement Learning)을 이용하여 더 성능을 끌어 올렸습니다.
특히 이 때 활용된 기술은 학습 과정에 인간의 직접적인 지도를 받는 Human-in-the-loop (HITL) 방식을 사용하였는데, ChatGPT는 이를 좀 더 정교하고 많은 지도 데이터를 사용된 것입니다.

OpenAI의 블로그에 따르면, 먼저 기존 GPT와 비슷한 방식의 GPT3.5를 학습시킨 후, 인간(crowdworker 또는 labeler라고도 지칭)에게 두 가지 일을 주었습니다.
1. 주어진 질문에 대한 답변을 대신 써줘.
2. 생성된 답변 여러 개를 랭킹 매겨줘.
이런 식으로 두 종류의 데이터를 생성한 후에 강화학습 알고리즘을 사용하였습니다.
이렇게 설명하면 무척 간단하지만, 실제로 유의미한 성능 증가를 이루어 낼 스케일의 데이터를 생성하려면 꽤나 많은 리소스가 투입되었을 것으로 예상됩니다. 그리고 수년 간 쌓아온 OpenAI의 강화학습 알고리즘 연구와 노하우가 쌓인 것이 GPT에 잘 접목한 것이 정말 대단합니다.
ChatGPT가 잘하는 것
인간 역시 연습이 완벽을 만드는 것처럼, ChatGPT 역시 어떤 추가 데이터로 강화가 되었는지 보면 무엇을 잘하기 위해 학습되었는지 알 수 있습니다.
다만 OpenAI에서 정확히 어떤 질문에 대해 데이터를 수집했는지는 공개하지 않고 있습니다. 그래서 추측만 할 수 있죠.
제가 감히 예측하건데 여태까지 API 공개를 통해 수집한 유저 데이터를 분석하여 어떤 유형의 질문에 대한 니즈가 높은지 파악한 후, 각 유형마다 세별 데이터 작업지를 만들어 Crowdworker들에게 나누어 주지 않았을까라는 생각이 듭니다.
그렇다면 우리는 어떤 데이터를 수집했는지 어떻게 알 수 있을까요? 저는 두 군데에서 힌트를 얻을 수 있다고 생각합니다.
1) ChatGPT Blog에 나온 Example

- 프로그래밍 도우미 Programming (“이 코드 함께 디버깅해줘")
- 브레인스토밍 (“집을 도둑으로부터 보호하는 방법")
- 간단하게 설명 또는 요약 Explanation in simple terms (“페르마의 소정리가 뭐니? 요약해줘.”)
- 컨텐츠 생성 (“이웃에게 자기소개하는 편지를 써줘")
2) ChatGPT UI에 나온 Examples & Capabilities
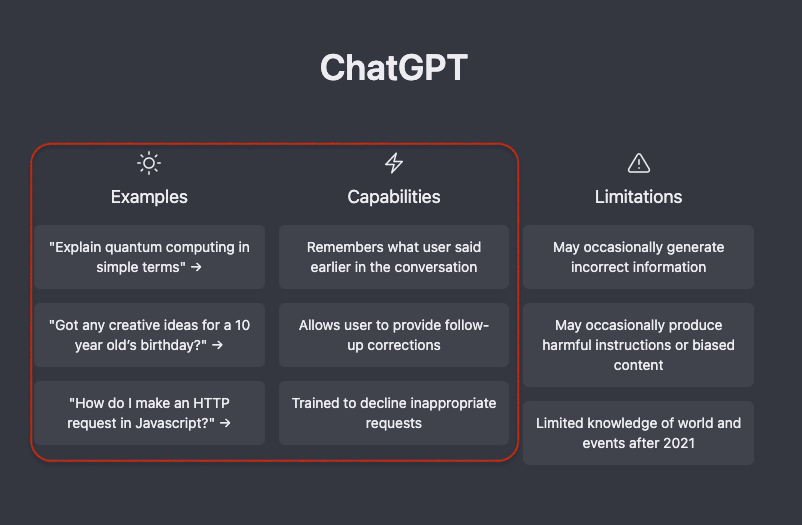
- 간단하게 설명 또는 요약 (“퀀텀 컴퓨팅을 간단하게 설명해줘")
- 브레인스토밍 (“10살짜리 생일에 대한 아이디어를 알려줘")
- 프로그래밍 도우미 (“자바스크립트에서 HTTP request를 만드는 걸 짜줘").
또한 능력(Capabilities)을 살펴보면:
(a) 이전 대화를 기억하여 답변한다.
(b) 적절하지 않은 질문은 거르고 답변한다.
(c) 추가 질의(Follow-on)를 통해 답변을 개선시킨다.
(a) 이전 대화를 기억
ChatGPT는 여태까지 진행된 대화 히스토리를 그 다음 답변을 생성할 때 함께 Input으로 넣는 방식으로 이전 대화를 "기억"합니다 예를 들어:
ChatGPT: 안녕하세요.
사용자: 자바스크립트의 역사에 대해 알려줘.
ChatGPT: 네, 자바스크립트는 ....
라는 대화를 이미 진행했을 때, 다음 질문으로:
사용자: 자바와는 어떤 관계야?
라고 물어봤을 때 앞선 대화 없이는 "자바스크립트와"라는 함축된 문맥을 알 수 없겠죠. 그렇기 때문에 앞서 진행된 대화 히스토리가 전부 다음 답변 생성을 위해 사용됩니다.
ChatGPT: 자바와 자바스크립트는 전혀 다른 언어입니다...
(b) 적절하지 않은 질문은 거르고 답변
(b)는 Week 33에 다룬 챗봇 윤리 편에서 다루었듯이 사용자들의 어뷰징(abusing)을 통한 논란을 방지하기 위해 아주 중요한 장치죠. 이는 구글 LaMDA에서도 안정성(safety) 점수가 있는 같은 이유입니다.
다만 ChatGPT가 더 인상적인 것은 민감한 주제는 답변을 회피하거나 거부하는 식으로 시스템을 만들어 놓은 것이 아니라, 꽤 유연하고 학습된 정보에 기반에 단호하게 답변을 한다는 점입니다.

(c) 추가 질의 후 답변 개선
(c)가 가장 ChatGPT의 강점이라고 생각합니다. 인간들도 협업을 할 때 지속적인 대화를 통해 결과물을 개선시켜나가고, 아이디어를 발전시킵니다. 지금까지의 NLP 시스템을 이러한 방식으로 대화를 하는 것은 굉장히 어려운 일인데, ChatGPT는 꽤나 훌륭하게 이를 수행합니다.

아마 (b)와 (c)를 위해서도 꽤나 많은 추가 데이터를 수집했을 것으로 추측됩니다. 정말 놀라운 것은 이렇게 데이터를 모으더라도 세상의 모든 질문과 대화를 수집할 수는 없는데, 이미 방대한 양의 데이터로 학습한 거대 언어 모델이 이러한 대화 양식과 패턴 역시 학습한 것으로 보입니다. 그래도 “반말로 바꿔줘" 같은 명령은 어디서 학습되는 것인지 놀랍습니다.
아직 ChatGPT를 안 써보신 분은 아직 무료이니 써보시길 바랍니다! 답변을 생성하는데 꽤나 많은 컴퓨팅 비용이 들어갈테니 언젠간은 유료로 전환될 것 같습니다.
다음 글에는 ChatGPT의 한계점과 응용 사례에 대해서 좀 더 다뤄볼 예정입니다.




