ChatGPT로 프로덕트를 만들기 전 고려할 사항은?


“a large monster with ropes tied to it in every direction. ropes are pulled to tame the monster. Artistic” Playgroundai.com에서 이미지 생성
ChatGPT라는 괴물이 세상에 던져졌습니다.
요즘은 정말 많은 사람들이 ChatGPT에 대해 이야기하고, 걱정하고, 공부하고 있습니다 (덕분에 블로그의 조회수가 폭발하고 있습니다!).
이 모델의 원리, 한계에 대해서 읽어보신 분들은 다음 떠올리는 질문이 있을거라 생각됩니다.
이걸 어떻게 써먹을 수 있을까?
많은 사람들은 이미 UI를 통해 검색엔진 대신 쓰고 있다고 합니다. 어떤 회사들은 벌써 ChatGPT를 연동하여 프로덕트를 출시하기도 하였습니다. Product Hunt에 트렌딩 키워드로 뜬 것만 봐도 알 수 있죠.
ChatGPT라는 괴물을 길들여 프로덕트로 만든다는 것은 어떤 의미일까요? 그리고 고려해야 할 사항은 무엇일까요? 과연 증기 기관처럼 세상을 바꾸는 엔진이 될 수 있을까요?
이번 글에서는 ChatGPT의 프로덕트화에 대해 저의 생각을 다루어 보았습니다.
*이 글은 소속된 회사의 입장이 아닌 개인의 의견임을 미리 밝힙니다.

ChatGPT를 나의 프로덕트와 연동할 수 있는 방법
ChatGPT를 먼저 접할 수 있는 방법은 UI를 통해서 입니다. 하지만 만약 프로덕트에 연동을 시키려면 이 방식을 사용할 수는 없겠죠. 브라우저에 새로운 탭을 키고 OpenAI에 접속해서 물어보라고 한다면 UX적으로도 좋지 않고, 유저 인터렉션이 프로덕트 밖에서 일어나기에 결국 어떠한 데이터도 얻을 수 없습니다.
예를 들어, ChatGPT가 잘한다는 Regular Expression(regex) 써주기를 한다고 합시다. 저는 보통 Regex를 Code Editor에서 써야 합니다. 만일 ChatGPT를 써야 한다면 브라우저를 켜놓고 질문을 하겠죠.
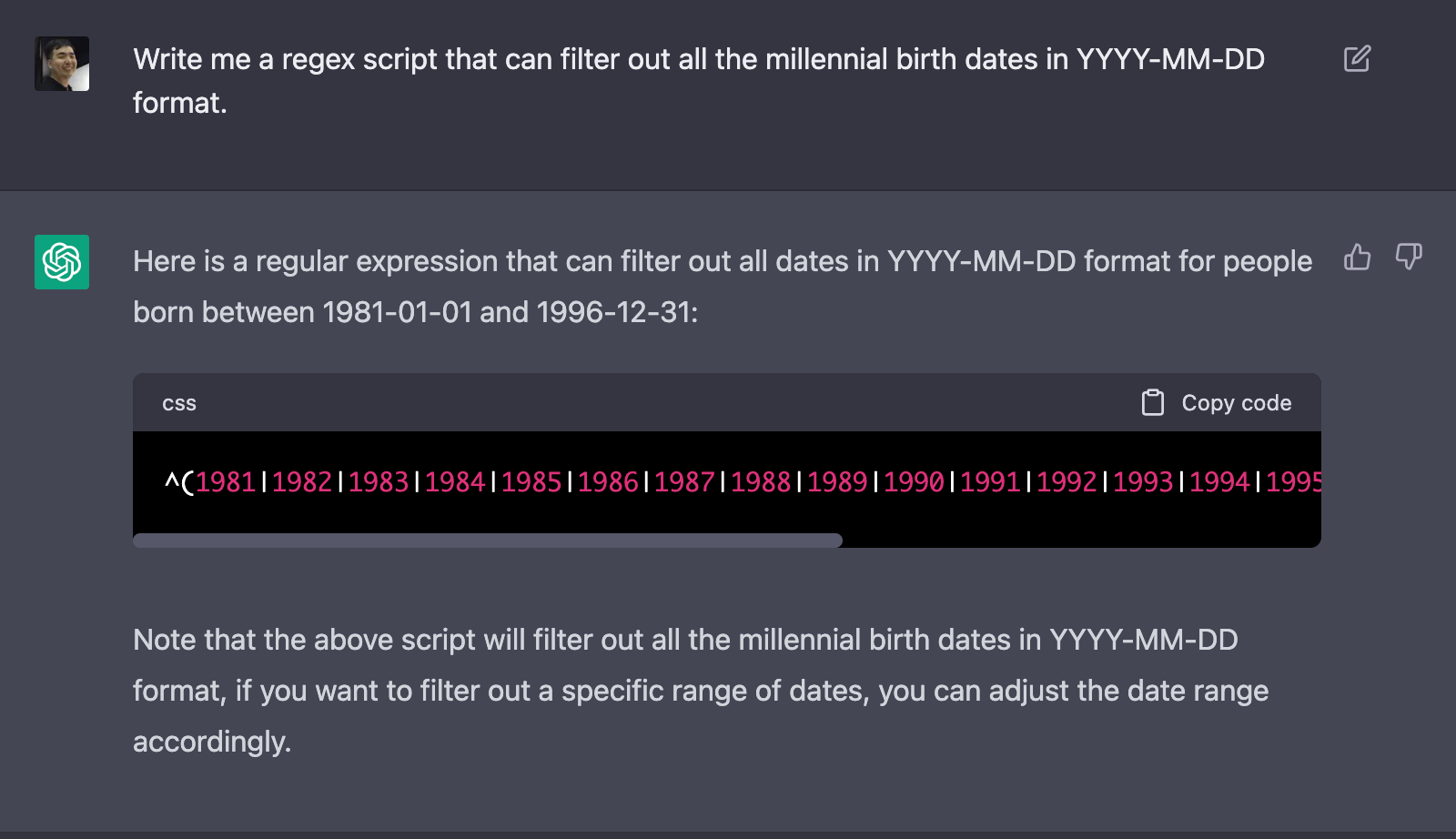
여기서 나온 결과를 Ctrl+C해서 다시 제 Code Editor로 Ctrl+V해야 합니다. 나쁘지 않지만, 바로 Editor에서 결과를 받아볼 수 있으면 좀 더 편하고 빠르겠죠?
그렇다면 Editor Extension 어플을 만들어야 하고, 결국 ChatGPT의 API를 활용해야 합니다.
API(Application Programming Interface)란?
API란 프로그램 간 정보 교환을 통해 소통할 수 있게 하는 커뮤니케이션 방식입니다. 어떠한 프로그램에 내가 원하는 정보를 요청했을 때, 어떠한 결과를 받아오는 Input => Output 방식이죠.
가장 간단한 API는 오픈 데이터베이스에 데이터 일부분을 받아오는 것입니다. 예를 들어, 기상청에서 오늘 날씨 정보를 받아올 수 있습니다.
주로 API는 뒤에 어떤 프로그램, 서버, 데이터베이스가 들어가있는지 알 수 없습니다. 어떤 API는 복잡한 서버 로직을 가지고 있지만, 사용자는 상관 없이 Input에 따른 Output만 받을 수 있습니다. 이는 API의 주인이 사용자에게 자신이 가지고 있는 코드의 내용을 노출시키지 않고 그때그때 결과만 제공할 수 있다는 큰 장점을 가집니다.
OpenAI의 API
OpenAI UI에서 ChatGPT에서 질문하면 답이 나오는 것 역시 API를 통해 가능한 것입니다. UI는 밖에 보이는 껍데기일뿐 이고요. UI에 입력된 나의 메시지가 API를 통해 OpenAI의 서버로 전송됩니다.
ChatGPT는 GUI로는 누구나 등록하면 사용할 수 있지만, API로도 사용이 가능합니다(2022-02-19 업데이트: 현재 API는 waiting list에 등록을 해야한다고 합니다.).
코드를 쓰면 ChatGPT와 질문과 답변을 주고 받는 프로덕트를 만들 수 있습니다. 최근 종종 보이는 ChatGPT 기반 카카오톡, 슬랙 챗봇이 다 이러한 방식을 사용하는 것 입니다.
OpenAI의 프로덕트 전략은 연구실에서 개발된 거대한 ML 모델들(ex. ChatGPT, GPT-3, DALL-E 등)을 API화해 세상에 내놓는 것입니다. 그리고 수익 전략은 API의 사용량에 따라 부분 유료화*를 하는 것 입니다.
* 그렇기에 OpenAI가 돈 내면 "Open"한 AI라고 비난받았죠.
OpenAI의 API는 간단합니다. 어떤 모델(model)인가, 들어가는 인풋(prompt), 그리고 랜덤함을 조절하는 온도(temperature), 최대 길이(max_tokens) 정도 밖에 없죠.
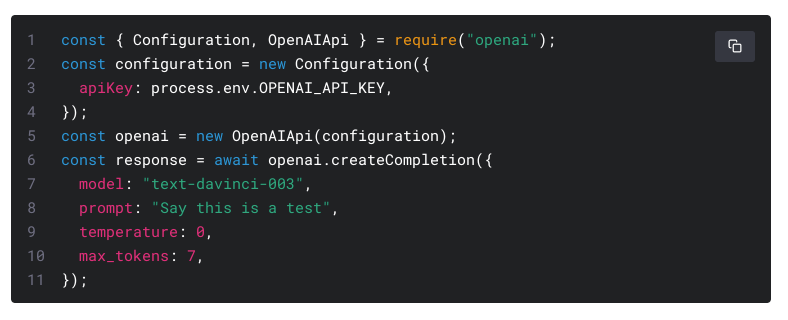
참 쉽죠? 하지만 이 간단하지만, 강력한 API를 이용하여 어떤 프로덕트를 만드려면 많은 것을 고민해야 합니다.
ML 기반 프로덕트를 만들기 전에 생각해볼만한 것들
ChatGPT 뿐만 아니라 어떠한 ML 모델을 기반 프로덕트를 만들 때 고려해야 할 점이 많습니다.
- ML 모델 성능은 어떻게 측정할 것인가
- 오류에 얼마나 민감한가
- 모델 개선 / 오류 교정을 어떻게 할 것인가
- 답변 안정성은 어떻게 보장하는가
- 얼마나 속도에 민감한가
- 데이터에 대한 법적 책임은 어떻게 되나
하나하나 짚어보도록 하겠습니다.
1. ML 모델 성능은 어떻게 측정할 것인가
모든 ML 모델을 사용하기 전에는 성능을 측정해야 합니다. 자신이 학습해 구축한 모델이라면, 가지고 있는 데이터의 일부분을 떼서 평가용 데이터로 쓰는 것이 일반적입니다. (Week 12: AI 모델에게도 예비 고사와 수능이 있다고요?)
문제는 OpenAI 같이 다른 회사가 제공하는 모델을 API를 통해 쓸 때입니다. 이럴 때에는 평가용 데이터 셋이 더더욱 중요해집니다. 왜냐하면, API로 모델이 학습된 데이터와 이 프로덕트에 들어오는 데이터가 다를 확률이 높기 때문입니다. 물론 GPT 같은 거대 언어 모델은 워낙 방대한 데이터로 학습되었기에 전세계 모든 텍스트 유형을 보았기에 높은 “일반성"을 보여준다고 주장하지만, 분명 프로덕트마다, 분야마다, 언어마다 특성이 강하기 때문에 이를 체크하는 것이 중요합니다.
그렇기에 프로덕트에 맞는 평가용 데이터 셋을 구축해야만 합니다. 아니면 눈을 가리고 앞으로 전진하는 것과 같습니다. OpenAI 역시 이러한 평가용 데이터 셋의 중요성을 강조하고 있습니다.
그러나 이러한 데이터 셋을 구축하고, 라벨링(labeling)하고, 매트릭(metric)을 정하고, 그리고 주기적으로 자동 평가하는 자체 시스템을 구축하는 것이 비용면으로나, 엔지니어링 난이도면으로나 쉽지만은 않습니다. 그렇기에 Week 50에서 다룬 KLUE처럼 여러 연구 기관들이 함께 벤치마크 데이터 셋을 합동으로 만들기도 합니다.
2. 오류에 얼마나 민감한가
다음으로 프로덕트가 ML 모델의 오류에 얼마나 민감한가 고민해야 합니다. ChatGPT처럼 텍스트를 생성하는 모델이라면 이를 바로 유저에게 보여주는 것이라면 많이 민감할 수 밖에 없습니다. 지난 Week 33에서 다룬 이루다 케이스를 보면 이를 잘하지 못했을 때 프로덕트 자체가 위험에 빠질 수 있다는 것을 알 수 있습니다.
평가 셋에서 99% 정확도를 보였더라 하더라도 한두번의 실수가 전체를 망칠 수 있는 것이죠. 그렇기 때문에 구글 (LaMDA Week 50) 같은 회사에서도 텍스트 생성 모델에 대한 안정성 이슈를 신중하게 다루고 있다는 것을 알 수 있습니다.
ChatGPT에서는 안정성 관련된 인풋은 자체적으로 거르기도 하고, 기본 검열(Moderation) API를 제공하고 있긴 합니다만, 이로 인해 발생되는 문제에 대한 책임은 사용자에 넘기고 있습니다.
만일 다른 인간이 한번 검수 또는 수정을 할 수 있는 과정이 있다면 조금 더 여유가 있습니다. 어떠한 글을 ChatGPT가 초안을 작성한 후 사람의 수정을 거치는 방식만으로도 꽤 큰 생산성 향상을 이룰 수 있다고 생각합니다. 최근에 한국에서도 Wrtn.ai (하이퍼클로바 기반) 같이 이러한 프로덕트가 출시되고 있는 것 같습니다.
예를 들어, 관공서에 작성해야 하는 문서는 형식 및 구조가 정해져 있지만, 쓰기는 귀찮고 긴 글쓰기에 활용하면 좋지 않을까 싶습니다. 이러한 경우에는 엉뚱하거나 안정성이 낮은 답변이 나오더라도 사람이 보고 다시 생성하거나 부분 수정하면 되죠.
3. 모델 개선 / 오류 교정을 어떻게 할 것인가
평가용 데이터 셋을 성공적으로 구축하고 ChatGPT의 성능 측정까지 끝냈다고 합시다. 아마 100% 성능은 아닐 것입니다. 그렇다면 이제 어떻게 해야 할까요?
이 부분은 두 가지로 나누어 볼 수 있습니다: (a) 전반적인 개선, (b) 오류 개별 교정
(a) 전반적인 개선
ChatGPT를 기반으로 프로덕트를 만든다면 ML 모델을 변형하는 방식의 개선은 불가능합니다. 왜냐하면 모델은 OpenAI가 업데이트를 하지 않는 이상 변하지 않기 때문이죠. 그렇기에 API를 이용하는 입장에서는 할 수 있는 것은 한가지 밖에 없습니다. Input Prompt를 바꾸는 것. 이를 Prompt Engineering이라고도 합니다.
전에 Week 30에 다루었던 GPT가 기존 NLP 모델과 다른 이유는 직접 ML 모델에게 문제에 대해 자연어로 설명을 하고 예시를 주는 방식을 사용할 수 있다는 것입니다. 즉, 어떠한 코딩이나 데이터 추가 없이도 설명만으로 GPT의 예측 방식에 영향을 줄 수 있다는 것이지요.
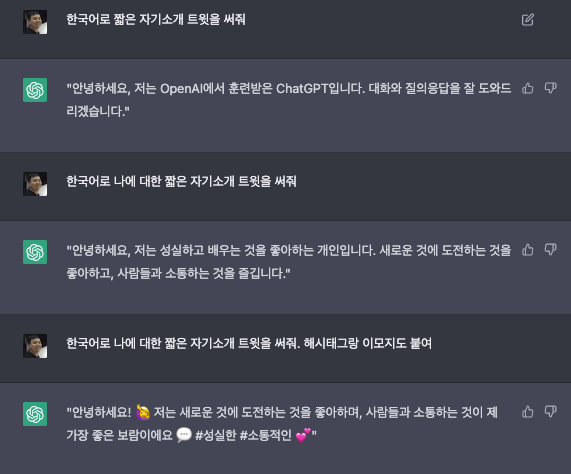
이는 비전문가도 ML 모델을 “제어"할 수 있기 때문에 정말 획기적인 방식이기는 합니다만, 문제는 “제어"하는 것이 쉽지 않다는 것입니다. 마치 블랙박스를 두고 이걸 눌러보고, 저걸 눌러보고 하면서 결과물을 보고 무엇이 되는지 안되는지 찾아야 합니다. 하나를 바꿔서 어떤 예시에 잘 작동하면, 잘 되던 다른 예시에는 잘 안되는 등 직관적이지 않고 시간이 많이 드는 작업입니다. 위 예시처럼 간단한 경우만 있는게 아니니깐요.
**Finetune 방식을 쓰면 안되나요? (심화)
Finetune 방식은 이미 pretrain된 모델에 좀 더 작지만 특정한 태스크에 맞는 데이터 셋을 추가 학습을 통해 성능을 올리는 방식입니다 (Week 28; BERT와 함께 설명). OpenAI에서는 Finetuning을 Beta로 제공하고 있지만 아직까지는 ChatGPT에는 적용할 수 없습니다.
현실적으로 이 방식이 가장 확실한 모델 개선 방법이라고 생각합니다. OpenAI 역시 ChatGPT가 특정한 종류의 문제에 더 좋은 성능을 보이기 위해 노동력이 싼 곳에서 크라우드워커(crowdworker)를 통해 추가 데이터를 모아서 Finetuning을 한 것으로 보입니다.
다만 문제는 Finetuning을 위해 데이터를 모으는 것은 프로덕트 개발 팀 입장에서 꽤나 비용 및 시간이 드는 작업이라는 것입니다. OpenAI 역시 Finetuning을 한 모델을 각각 개별로 Hosting 및 Serving해주어야 하는데 ChatGPT 정도의 스케일에서 경제성 있는 시스템을 만들 수 있을지 현 상황에서는 모르겠습니다.
(b) 오류 개별 교정
앞서 말했듯이 99% 맞는 답을 내놓는다고 해서 1-2개의 답에 오류가 있으면 제품 출시에 큰 장애물이 될 수 있습니다. 유저들이 자주 물어보는 질문에서 잘못된 팩트를 출력하면 어떻게 해야 할까요?
예를 들어, 이벤트에 관한 Q&A 챗봇을 만들었는데, 자꾸 이벤트의 날짜나 장소를 틀리게 말한다면? 고객 센터 챗봇인데 없는 반품 과정을 지어내 답변한다면? 자유 주제 대화 챗봇인데 잘 이야기하다가 하나의 중요한 키워드에 대해서는 부정적인 답변을 내놓는다면?
ChatGPT 같은 생성 모델을 사용할 때는 개별 오류 교정은 정말 어려운 문제입니다. OpenAI에게 확실히 고쳐달라고 할 수 있는 프로세스도 있지 않습니다. GUI에 있는 엄지 척/다운 뿐이지요. 언제 고쳐질지도 모릅니다.
이처럼 전반적인 모델 개선에 대한 주도권을 가지고 있지 않다면, 개별 오류를 하나하나 교정하는 것은 어렵습니다. ChatGPT에 들어가는 Input과 Output을 따로 분석을 하여 대응하는 시스템을 따로 갖추어야 할지도 모릅니다. 자주 물어보는 질문(FAQ)은 이미 있는 답변 풀에서 답을 한다거나, 사용자에 메시지에 따라 추가 정보를 ChatGPT에 들어가는 Input을 붙여준다거나요. 정해진 답이 없습니다.
4. 답변의 안정성은 어떻게 보장하는가
<서브웨이>에서 샌드위치를 주문하는 방식은 처음 가는 사람에게는 무척 어렵습니다. 빵부터 소스까지 골라야하는 것이 많죠. 하지만 몇번 가다보면 같은 패턴이 반복되기 때문에 적응이 되지요. 근데 만약 갈 때마다 물어보는 순서, 종업원들이 묻는 질문/답변 형태가 달라지면 얼마나 헷갈리고 짜증이 날까요?
이와 같이, 내가 한 같은 말에 대해 시스템의 답변이 그때그때 다르다면 굉장히 혼란스러울 것 입니다. 매일 “방에 불을 켜달라”고 했을 때 잘 알아듣다가 갑자기 어느 날 “어떤 방에 불을 켜드릴까요?”라고 되묻는다면 어리둥절할 것입니다.
문제는 OpenAI에서 ChatGPT 모델을 업데이트했을 때 본인의 프로덕트에 큰 변화를 줄 수도 있다는 것 입니다. 더 좋은 방향이면 가장 좋겠지만, 아닐 수도 있다는 것이죠. 프로덕트 개발 팀 입장에선 이에 대한 컨트롤을 가지기가 쉽지 않습니다. OpenAI 측에서 본인들의 분석에 의해 추가 데이터를 막 투입해서 재학습시켰는데, 연동된 어떤 프로덕트들은 덕을 보지만, 어떤 프로덕트들에는 해만 끼칠 수 있습니다. 워낙 OpenAI의 모델들은 General purpose로 만들어졌고, ChatGPT는 하나의 모델로 다양한 프로덕트 사례에 쓰이도록 설계 되어있기에 이런 경우가 나올 수 밖에 없다고 생각합니다. 게다가 ChatGPT는 최신 정보를 재학습 외에는 반영할 수 없기에, 모델 재학습은 피할 수 없습니다.
**평가 셋에서 결과 숫자가 내려가지만 않으면 괜찮은거 아닌가요? (심화)
만일 평가 데이터 셋을 가지고 있다면 모델이 업데이트가 될 때마다 평가를 다시 돌릴 수 있습니다. 평가 셋에서 성능이 바뀌지 않은 경우를 한번 같이 생각해볼까요?
전체 성능 매트릭(metric)에는 변화가 없더라도 유저들이 느끼는 변화는 0이 아닐 수도 있습니다. 예를 들어, 업데이트 전에 100개의 데이터 중에 90개는 맞고, 10개는 틀려 90%의 성능을 가지고 있다고 가정해봅시다. 만약 업데이트 후에 틀리던 10개 중에 5개는 개선이 되어 답변을 잘하게 되었지만, 잘하던 90개 중에 5개에서 오류를 범하게 되었다면?
전체적으로 보면 100개 중 90개가 맞기에 90% 성능은 똑같지만, 유저들은 10개의 경우에서 변화를 느끼게 됩니다. 5개는 잘 되던게 안되고, 다른 5개는 잘 안되다가 잘 되는 것이죠. 유저 입장에서는 갑자기 “되네?”라고 기뻐할 수도 있고, 이미 전에 해봤을 때 안 됐기 때문에 다시는 그런 인풋을 안 던져서 결국은 개선된 것을 못 느낄 수도 있습니다.
문제는 되던게 안되는 것입니다. 항상 잘되던 것이 갑자기 안되면 바로 불편함을 느끼겠죠!
이처럼 프로덕트의 결과가 ML 모델에 따른 변동성이 크면 사용자들이 느끼는 신뢰도와 사용성에 문제가 생길 수 있습니다.
이를 방지하기 위해 프로덕트 개발 팀은 ChatGPT의 버전을 잘 기록해놓았다가 업데이트가 나왔을 때 곧바로 업데이트 하는 것이 아니라, 구축한 평가 데이터 셋으로 성능의 증가/감소 그리고 변동성을 모니터링 후에 새 버전을 사용하는 방식을 해야 하지 않을까 싶습니다. 마치 다른 오픈소스 라이브러리 업데이트 전에 Integration testing을 하는 것처럼요.
5. 얼마나 속도에 민감한가
가장 이해하기 쉬운데 간과하기 쉬운 부분입니다. ChatGPT는 거대한 모델이기 때문에 GPU를 병렬처리한다고 해도 텍스트를 생성하는데 시간이 걸립니다. 실제로 GUI를 써보면 텍스트를 생성하는데 시간이 걸린다는 것을 알 수 있죠. 한국어로 하면 Unicode를 사용해서 그런지 더 느립니다.
여러분의 프로덕트를 사용하는 유저에게 속도가 중요한가요? 아니면 좀 기다려줄 수 있나요? 예를 들어, 이메일로 응대하는 고객센터 챗봇이라면 이메일을 생성할 때까지 유저는 기다리지 않기 때문에 괜찮습니다. 하지만 채팅창이라면 마치 반대편에 있는 사람이 타이핑하는 것을 기다리는 것과 같죠.
만약에 게임 NPC를 ChatGPT로 구현했다면 어떨까요? 물론 게임 NPC와 현실적인 대화를 하는 것이 신기하긴 하겠지만, 만일 한 턴당 10초씩 걸린다면 짜증날 것 같습니다.
6. 데이터에 대한 법적 책임은 어떻게 되나
마지막이지만 중요한 포인트는 데이터에 대한 법적 책임입니다. 저는 OpenAI의 모든 약관을 읽어보지는 않았지만 Emily Bender 교수는 아래 트윗을 통해 굉장히 중요한 것을 지적합니다:
Was just perusing @OpenAI 's terms of service and was a little surprised to find this. Are they really saying that the user is responsible for ensuring that #ChatGPT's output doesn't break any laws?
— @emilymbender@dair-community.social on Mastodon (@emilymbender) February 1, 2023
Source: https://t.co/VPWd2InRb5
>> pic.twitter.com/NgYecfAZc9
1. API를 통해 들어가고 나오는 Input/Output (합쳐서 Content)는 때때로 OpenAI가 서비스 개선 및 유지를 위해 사용할 수도 있다.
2. 컨텐츠 때문에 발생하는 법적 책임은 당신에게 있다.
먼저 Input부터 생각해보면, 이 프로덕트는 유저의 데이터를 어찌됬든 제3자인 OpenAI에게 제공하는 것입니다. 이는 약관을 통해 확실히 명시하고 동의를 받아야 할 것 같습니다. 그리고 좀 민감한 개인정보에 대해서는 API를 통해 넘어가지 않도록 더욱 조심해야겠네요. (Week 32: AI 챗봇이랑 윤리랑 무슨 상관인데? <개인정보 편>)
두번째 사항이 리스크가 더 큽니다. 앞선 포스트에서 다루었듯이 ChatGPT에는 사실 관계 확인이 되지 않은 분명한 한계가 있습니다. 그런데 만약 ChatGPT 기반으로 한 프로덕트가 어떤 거짓 정보를 통해 유저에게 해를 입혔다면? 아니면 유저가 범죄를 위한 정보를 직접적인 조언을 제공 받았다면? 이에 대한 법적 책임은 OpenAI가 아니라 API를 연동한 제품 개발 팀에게 있다는 것으로 보입니다.
ChatGPT를 연동하기 전에 먼저 프로덕트의 약관과 법적 리스크를 먼저 검토하는 것은 필수이겠네요!
오늘은 ChatGPT 같은 ML로 프로덕트를 만들기 전 고려해야 할 사항에 대해서 다루어 보았습니다. 생각보다 여러 가지가 많습니다. 단순히 API를 연동하는 것을 누구나 할 수 있지만, 실제로 유용한 프로덕트로 만드는 것은 꽤나 난이도가 높습니다. 모든 테크 프로덕트가 그렇듯이 엔지니어링 그리고 제품 기획이 뛰어난 팀이 괴물을 길들여 임팩트를 만들 것이라고 생각합니다 .
OpenAI의 CEO Sam Altman은 ChatGPT를 통해 2024년 1B$ 매출을 예상하고 있다고 합니다. 이를 이루기 위해서는 스타트업 등 많은 회사들이 API를 효과적으로 사용하는 방법을 알아야 할 것입니다. 하지만 OpenAI는 괴물을 내놓기만 했지 길들여 사용하는 방법은 내놓지 않았다고 생각합니다. 누구나 쉽게 AI 파워를 쓸 수 있게 되었다는 주장과는 다르게 ChatGPT 같은 거대 언어모델을 효과적으로 프로덕트에 연동할 수 있는 개발 팀은 많지 않을 것이라고 생각합니다 (제 예측이 틀렸으면!).
그렇기에 OpenAI가 Microsoft에게 전략적 투자를 받은 것이 이해가 됩니다. 빅테크 기업 Microsoft에는 뛰어난 엔지니어, PM 최정예 군대를 가지고 있기에 동시다발적으로 이 괴물에 달라붙어 수많은 밧줄을 던져 길들이기를 시작할 것으로 생각합니다. 많은 팀들은 실패할 것이고, 몇몇 팀들은 크게 성공하겠죠. 이미 Teams에 OpenAI의 모델로 연동된 기능들이 출시되었고, 사람들은 검색엔진인 Bing을 주시하고 있습니다.
앞으로 ChatGPT 연동 프로덕트가 쏟아져 나올까요? 그 중 얼마나 유저들의 지속적인 선택을 받을 수 있을까요?




