

ChatGPT가 나온지 얼마도 되지 않아 GPT-4가 발표되었습니다. OpenAI가 움직이는 속도는 참 경이롭습니다. 마이크로소프트 인프라의 날개를 달아 그런지 더욱 빠르게 움직이는 것이 아닐까 싶습니다.
요즘 NLP를 공부하시는 분들은 하루하루 정신이 없으시죠? 그럴수록 정보의 홍수 속에 허우적되는 것보다, 핵심 정보만 선별해서 소화하는 것이 중요하다고 생각합니다. 특히 이럴 때일수록 공식 블로그나 논문을 원문으로 읽는 것이 노이즈를 제거하는 것에 큰 도움이 됩니다.
다만 이번에 안타까운 점은 OpenAI가 GPT-4를 논문이 아니라 테크니컬 리포트의 형태로만 공개했다는 것입니다. 정확한 모델의 구조, 파라미터 수 등은 공개하지 않고, High-level overview와 성능 평가 결과만 보여주었습니다. 그럼에도 불구하고 꽤나 많은 정보가 담겨 있었기에 읽을 가치가 있었지만, 앞으로 치열한 경쟁 속에서 이런 트렌드가 계속 될까봐 우려가 되기도 합니다.
이번 <위클리 NLP>에서는 GPT-4에 무엇이 업그레이드 되었는지 정리해보았습니다.

이미지를 Input으로 받을 수 있다
가장 큰 변화는 이미지도 Input으로 받을 수 있다는 것입니다. 이를 다중인풋(Multi-modal) 모델이라고 합니다.
전에 OpenAI의 또다른 모델 DALL-E, 그리고 구글에서 발표한 MUM, MultiSearch (I/O 2021, I/O 2022) 가 대표적인 Multi-modal 모델입니다.
GPT-4는 Input으로 이미지와 텍스트를 받고, 텍스트를 Output 합니다. 그렇다면 이런 식의 대화가 가능하겠죠.

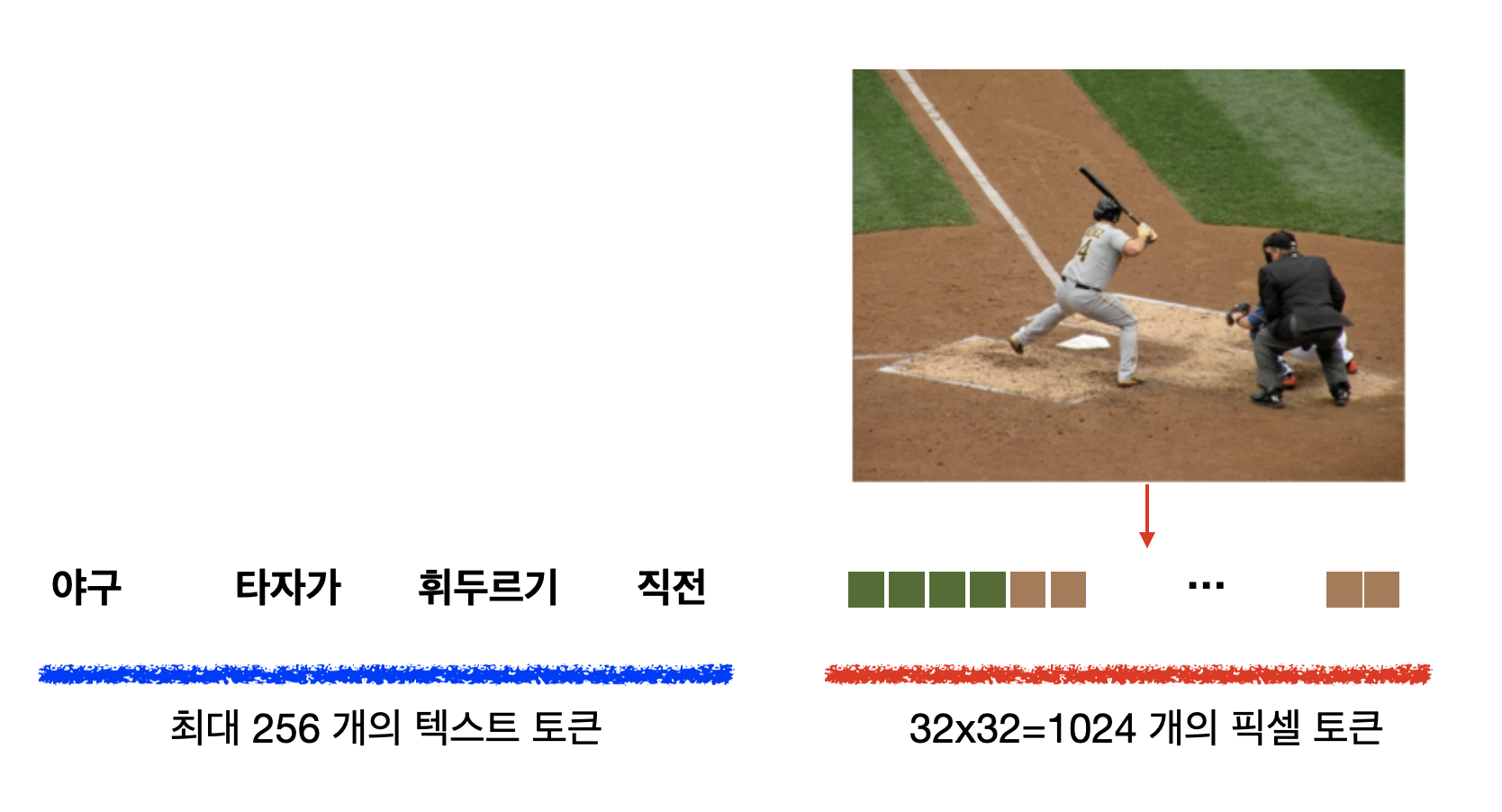
이미지를 Input으로 받는 것은 어떻게 가능한 것일까요?
DALL-E (Week 40)를 공부하면서 설명했듯이, 이미지의 픽셀을 토큰화 시키면 트랜스포머 모델에 넣을 수 있습니다. GPT-4가 DALL-E와 다른 점은 이미지 토큰을 받기만 하지 출력하지는 않는다는 점입니다.
Input 길이가 대폭 늘어났다
ChatGPT는 3천여개의 단어, GPT-3.5는 8천여개의 단어까지 Input으로 받을 수 있는 반면, GPT-4는 2만5천여개로 늘어났습니다.
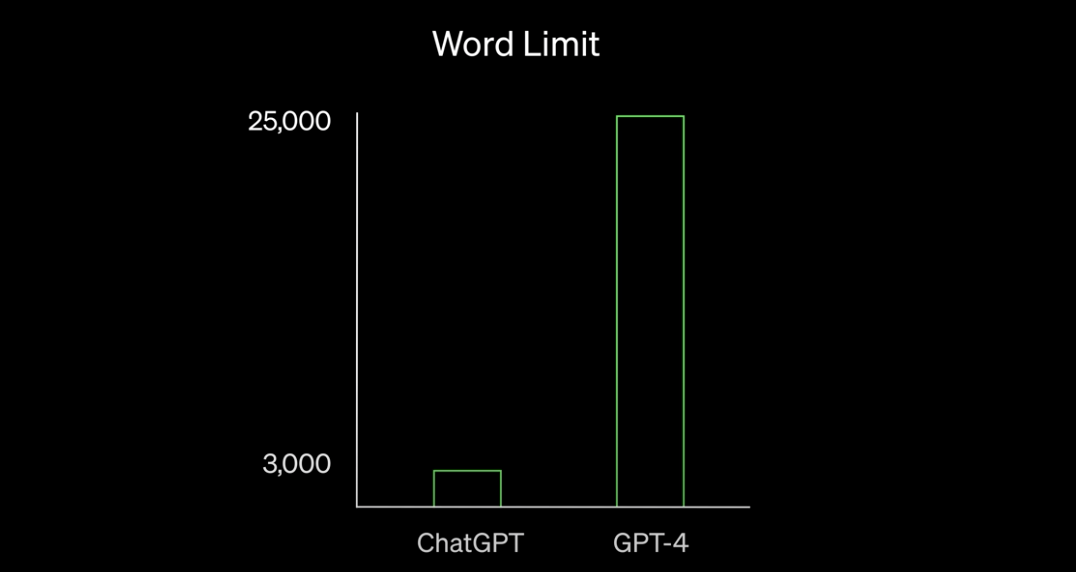
꽤나 의미 있는 증가입니다. GPT는 대화 또는 문제에 필요한 Context (맥락)을 파악하기 위해, 과거 대화 히스토리 또는 필요한 정보를 Input 앞에 붙이는 방식(ChatGPT 원리 편 참고)을 사용하고 있는데, 이러한 길이 증가는 성능 향상에 큰 도움이 될 것입니다.
테크니컬 리포트에는 나와있지 않지만, Image를 함께 Input으로 사용하기 위해 자연스럽게 Input 길이가 늘어나지 않았을까 싶습니다. 이미지 성능 향상에 의미가 있으려면 어느 정도의 해상도 사이즈를 지원해야 할테니깐요.
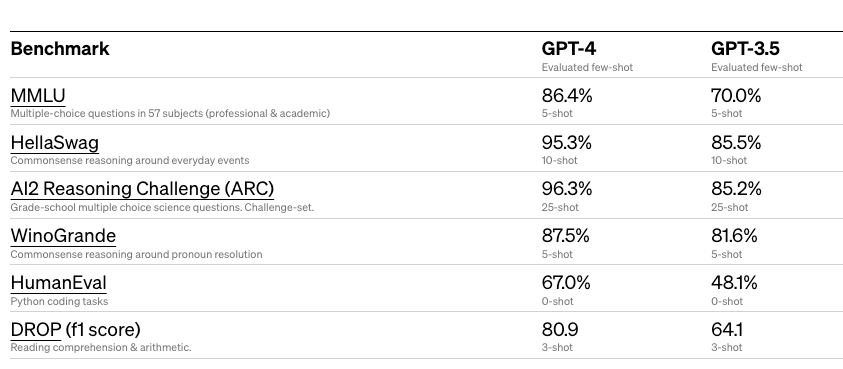
GPT3.5보다 얼마나 업그레이드 되었나?
실제로 테크니컬 리포트에 공개된 결과에서도 기본 상식 테스트, 독해 능력, 파이썬 코딩 등 GPT3.5에서 4로 갈 때 큰 증가를 보입니다.
재밌었던 부분은 GPT 모델들을 실제 미국 대학교, 대학원 입시에 쓰이는 AMC, SAT, AP, GRE, LSAT 등의 시험에 테스트했다는 점인데요. 객관식 뿐만 아니라 주관식 및 서술형 문제도 있기 때문에 실제로 학생들의 채점하는 회사에 의뢰하여 결과를 도출했다고 합니다.
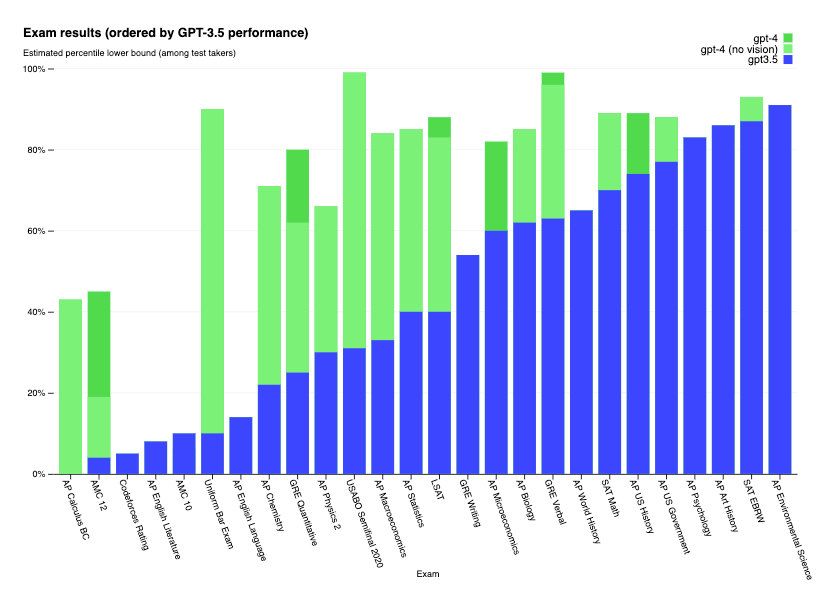
어떻게 업그레이드 되었나?
이처럼 GPT-4에서 더 좋은 성능을 보이는데, 모델 구조나 학습 방법에 어떤 차이가 있는지 전부 나와있지는 않아 알 수 없지만, 인풋 길이가 길어진 것이 꽤나 큰 영향이 있지 않을까 예상합니다. 특히 AP, LSAT 시험 같은 경우에는 지문이 긴 경우가 많을 테니까요.
그 외에 리포트에서는 Post-training alignment process, 즉 학습 후 교정 과정을 통해 GPT의 가장 큰 한계라고 지적되는 팩트 체크(Factuality), 안정성(Safety)를 강화했다는 것을 강조합니다.
GPT를 업그레이드 또는 교정하기 위해 쓰이는 방식은 Reinforcement Learning with Human Feedback (RLHF)인데요. (Week 53, ChatGPT 원리 편). 즉, 추가로 모은 데이터를 가지고 강화학습을 통해 Finetuning하는 방식입니다.
첫번째, 팩트 체크(Factuality)을 위해서 통계 모델 관점(“statistically appealing”이라 표현)에서는 비슷하지만, 사실과는 맞지 않는 데이터를 추가하여 모델의 “Hallucination” (ChatGPT 한계 편)을 줄였다고 합니다. 내부용 데이터 및 공개된 벤치마크 데이터 셋 (Truthful QA)에서 ChatGPT에 비해 유의미한 발전을 이루었다고 하네요.
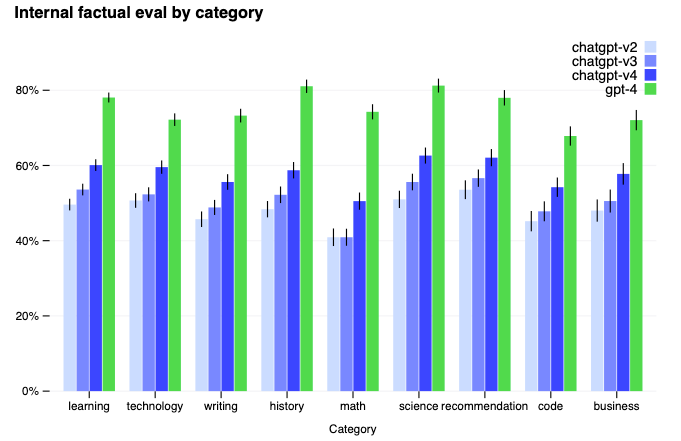
그리고 두번째, 안정성(Safety)에서는 기존에 RLHF에서 추가로 Rule-Based Reward Models (RBRM)이라는 테크닉을 소개합니다. 또다른 GPT-4 모델들에게 Prompt의 안정성을 점수로 평가하게 한 후, 이를 RLHF 학습 때 반영하게 하는 방식입니다. 전에 공부한 AI 챗봇 안전성 (Week 33) 그리고 구글 LaMDA 논문 (Week 50)에서 나온 아이디어들과 강화학습을 섞어 발전된 형태라고 생각됩니다. GPT 모델의 안정성을 다른 GPT 모델로 해결하다니 정말 재밌는 것 같습니다.
다만, ChatGPT에게 안전하지 않은 답변을 생성하게 하는 Jailbreak 방식이 계속 나오고 있기 때문에 얼마나 효과적일지는 출시 되보아야 알 것 같습니다. 이 문제는 계속 경찰이 도둑잡기 식으로 진행될 것으로 예상되고, OpenAI도 내부적으로 White hacker 또는 red team을 구축하고 있는 것 같습니다.

오늘은 새로 출시된 GPT-4를 간단히 소개해보았습니다. 이 외에 API 공개 방식, Pricing 같은 것은 살펴보지 않았는데요. 아무래도 더 많은 연산이 들어갈 것으로 예상되기에 더 비싸지지 않을까 싶은데, 혹시 잘 아시는 분들이 있으면 댓글로 달아주시면 감사하겠습니다!
구글도 Bard를 공개하면서 이 분야의 경쟁이 치열해지고 있는데요. 계속 정신없고 흥미진진한 날들이 펼쳐질 것 같습니다.
